 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptical Flow Based Detection and Tracking of Moving Objects for Autonomous Vehicles
Mar 26, 2024



Accurate velocity estimation of surrounding moving objects and their trajectories are critical elements of perception systems in Automated/Autonomous Vehicles (AVs) with a direct impact on their safety. These are non-trivial problems due to the diverse types and sizes of such objects and their dynamic and random behaviour. Recent point cloud based solutions often use Iterative Closest Point (ICP) techniques, which are known to have certain limitations. For example, their computational costs are high due to their iterative nature, and their estimation error often deteriorates as the relative velocities of the target objects increase (>2 m/sec). Motivated by such shortcomings, this paper first proposes a novel Detection and Tracking of Moving Objects (DATMO) for AVs based on an optical flow technique, which is proven to be computationally efficient and highly accurate for such problems. \textcolor{black}{This is achieved by representing the driving scenario as a vector field and applying vector calculus theories to ensure spatiotemporal continuity.} We also report the results of a comprehensive performance evaluation of the proposed DATMO technique, carried out in this study using synthetic and real-world data. The results of this study demonstrate the superiority of the proposed technique, compared to the DATMO techniques in the literature, in terms of estimation accuracy and processing time in a wide range of relative velocities of moving objects. Finally, we evaluate and discuss the sensitivity of the estimation error of the proposed DATMO technique to various system and environmental parameters, as well as the relative velocities of the moving objects.
A Novel Deep Neural Network for Trajectory Prediction in Automated Vehicles Using Velocity Vector Field
Sep 19, 2023Anticipating the motion of other road users is crucial for automated driving systems (ADS), as it enables safe and informed downstream decision-making and motion planning. Unfortunately, contemporary learning-based approaches for motion prediction exhibit significant performance degradation as the prediction horizon increases or the observation window decreases. This paper proposes a novel technique for trajectory prediction that combines a data-driven learning-based method with a velocity vector field (VVF) generated from a nature-inspired concept, i.e., fluid flow dynamics. In this work, the vector field is incorporated as an additional input to a convolutional-recurrent deep neural network to help predict the most likely future trajectories given a sequence of bird's eye view scene representations. The performance of the proposed model is compared with state-of-the-art methods on the HighD dataset demonstrating that the VVF inclusion improves the prediction accuracy for both short and long-term (5~sec) time horizons. It is also shown that the accuracy remains consistent with decreasing observation windows which alleviates the requirement of a long history of past observations for accurate trajectory prediction. Source codes are available at: https://github.com/Amir-Samadi/VVF-TP.
Trajectory Prediction with Observations of Variable-Length for Motion Planning in Highway Merging scenarios
Jun 08, 2023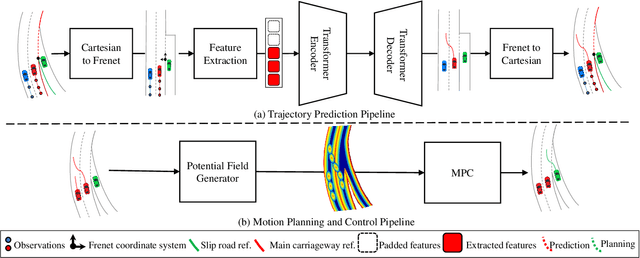
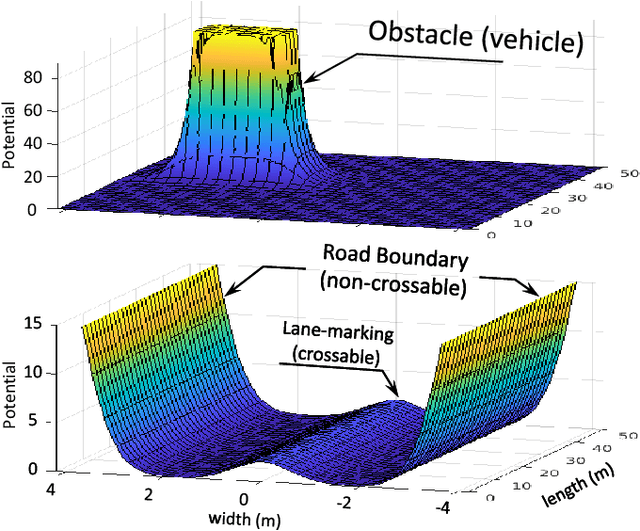
Accurate trajectory prediction of nearby vehicles is crucial for the safe motion planning of automated vehicles in dynamic driving scenarios such as highway merging. Existing methods cannot initiate prediction for a vehicle unless observed for a fixed duration of two or more seconds. This prevents a fast reaction by the ego vehicle to vehicles that enter its perception range, thus creating safety concerns. Therefore, this paper proposes a novel transformer-based trajectory prediction approach, specifically trained to handle any observation length larger than one frame. We perform a comprehensive evaluation of the proposed method using two large-scale highway trajectory datasets, namely the highD and exiD. In addition, we study the impact of the proposed prediction approach on motion planning and control tasks using extensive merging scenarios from the exiD dataset. To the best of our knowledge, this marks the first instance where such a large-scale highway merging dataset has been employed for this purpose. The results demonstrate that the prediction model achieves state-of-the-art performance on highD dataset and maintains lower prediction error w.r.t. the constant velocity across all observation lengths in exiD. Moreover, it significantly enhances safety, comfort, and efficiency in dense traffic scenarios, as compared to the constant velocity model.
Multimodal Manoeuvre and Trajectory Prediction for Autonomous Vehicles Using Transformer Networks
Mar 28, 2023



Predicting the behaviour (i.e. manoeuvre/trajectory) of other road users, including vehicles, is critical for the safe and efficient operation of autonomous vehicles (AVs), a.k.a. automated driving systems (ADSs). Due to the uncertain future behaviour of vehicles, multiple future behaviour modes are often plausible for a vehicle in a given driving scene. Therefore, multimodal prediction can provide richer information than single-mode prediction enabling AVs to perform a better risk assessment. To this end, we propose a novel multimodal prediction framework that can predict multiple plausible behaviour modes and their likelihoods. The proposed framework includes a bespoke problem formulation for manoeuvre prediction, a novel transformer-based prediction model, and a tailored training method for multimodal manoeuvre and trajectory prediction. The performance of the framework is evaluated using two public benchmark highway driving datasets, namely NGSIM and highD. The results show that the proposed framework outperforms the state-of-the-art multimodal methods in the literature in terms of prediction error and is capable of predicting plausible manoeuvre and trajectory modes.
Prediction Based Decision Making for Autonomous Highway Driving
Sep 05, 2022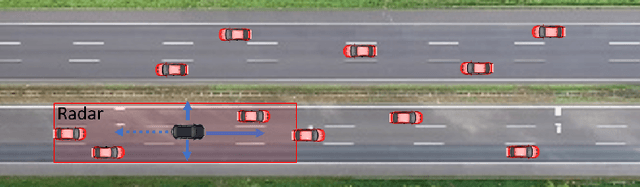
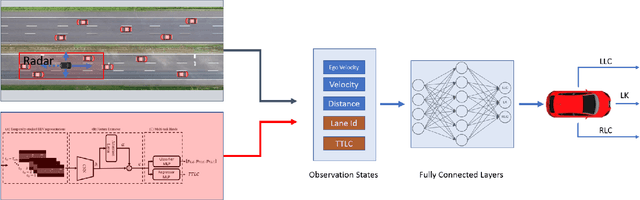

Autonomous driving decision-making is a challenging task due to the inherent complexity and uncertainty in traffic. For example, adjacent vehicles may change their lane or overtake at any time to pass a slow vehicle or to help traffic flow. Anticipating the intention of surrounding vehicles, estimating their future states and integrating them into the decision-making process of an automated vehicle can enhance the reliability of autonomous driving in complex driving scenarios. This paper proposes a Prediction-based Deep Reinforcement Learning (PDRL) decision-making model that considers the manoeuvre intentions of surrounding vehicles in the decision-making process for highway driving. The model is trained using real traffic data and tested in various traffic conditions through a simulation platform. The results show that the proposed PDRL model improves the decision-making performance compared to a Deep Reinforcement Learning (DRL) model by decreasing collision numbers, resulting in safer driving.
Fast and Robust Registration of Partially Overlapping Point Clouds
Dec 18, 2021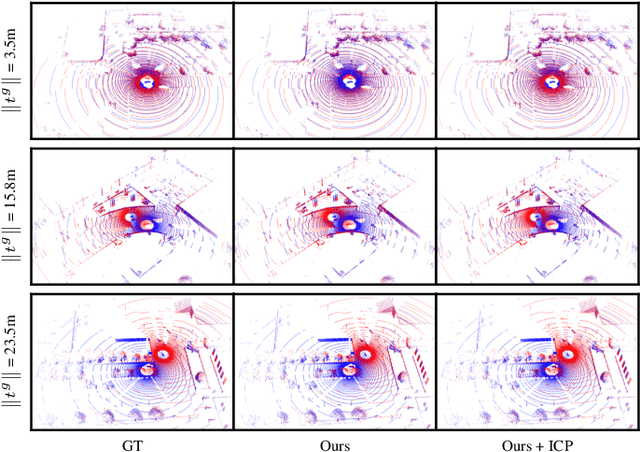

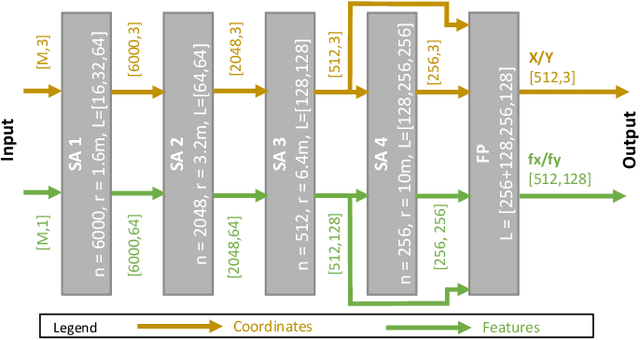
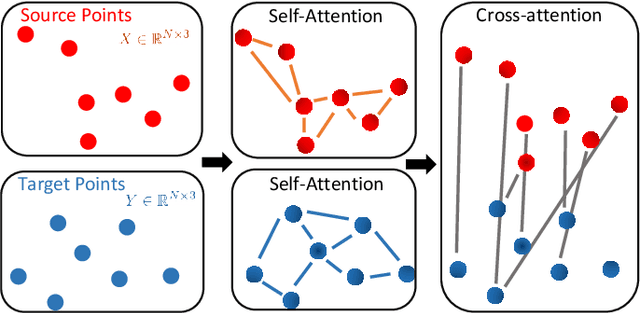
Real-time registration of partially overlapping point clouds has emerging applications in cooperative perception for autonomous vehicles and multi-agent SLAM. The relative translation between point clouds in these applications is higher than in traditional SLAM and odometry applications, which challenges the identification of correspondences and a successful registration. In this paper, we propose a novel registration method for partially overlapping point clouds where correspondences are learned using an efficient point-wise feature encoder, and refined using a graph-based attention network. This attention network exploits geometrical relationships between key points to improve the matching in point clouds with low overlap. At inference time, the relative pose transformation is obtained by robustly fitting the correspondences through sample consensus. The evaluation is performed on the KITTI dataset and a novel synthetic dataset including low-overlapping point clouds with displacements of up to 30m. The proposed method achieves on-par performance with state-of-the-art methods on the KITTI dataset, and outperforms existing methods for low overlapping point clouds. Additionally, the proposed method achieves significantly faster inference times, as low as 410ms, between 5 and 35 times faster than competing methods. Our code and dataset are available at https://github.com/eduardohenriquearnold/fastreg.
Early Lane Change Prediction for Automated Driving Systems Using Multi-Task Attention-based Convolutional Neural Networks
Sep 22, 2021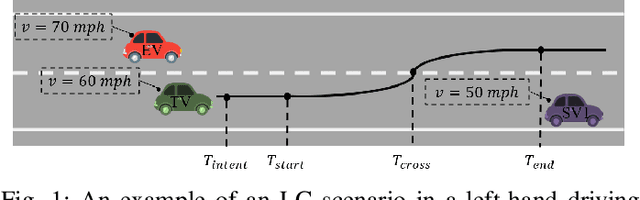
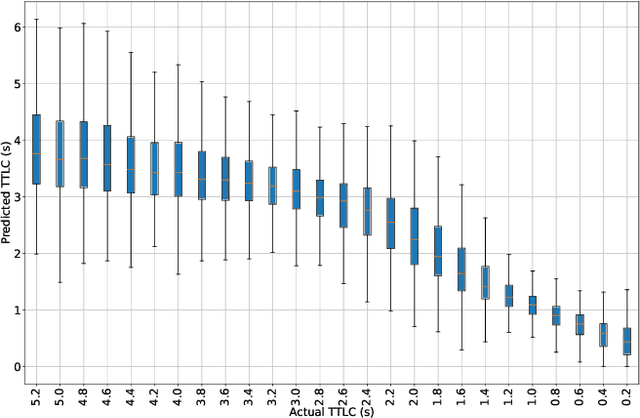
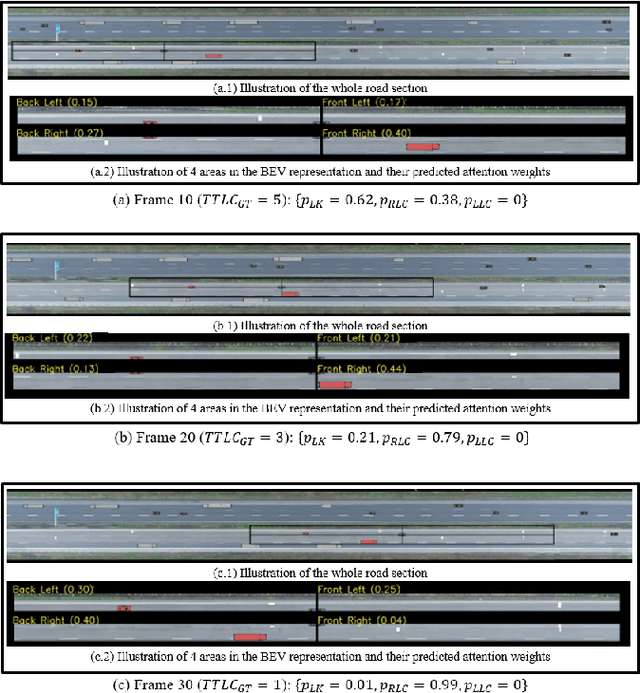

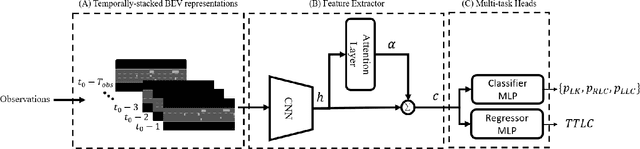
Lane change (LC) is one of the safety-critical manoeuvres in highway driving according to various road accident records. Thus, reliably predicting such manoeuvre in advance is critical for the safe and comfortable operation of automated driving systems. The majority of previous studies rely on detecting a manoeuvre that has been already started, rather than predicting the manoeuvre in advance. Furthermore, most of the previous works do not estimate the key timings of the manoeuvre (e.g., crossing time), which can actually yield more useful information for the decision making in the ego vehicle. To address these shortcomings, this paper proposes a novel multi-task model to simultaneously estimate the likelihood of LC manoeuvres and the time-to-lane-change (TTLC). In both tasks, an attention-based convolutional neural network (CNN) is used as a shared feature extractor from a bird's eye view representation of the driving environment. The spatial attention used in the CNN model improves the feature extraction process by focusing on the most relevant areas of the surrounding environment. In addition, two novel curriculum learning schemes are employed to train the proposed approach. The extensive evaluation and comparative analysis of the proposed method in existing benchmark datasets show that the proposed method outperforms state-of-the-art LC prediction models, particularly considering long-term prediction performance.
Visual Sensor Pose Optimisation Using Rendering-based Visibility Models for Robust Cooperative Perception
Jun 09, 2021

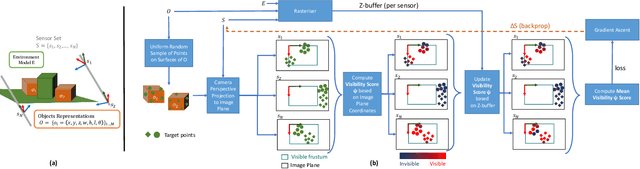
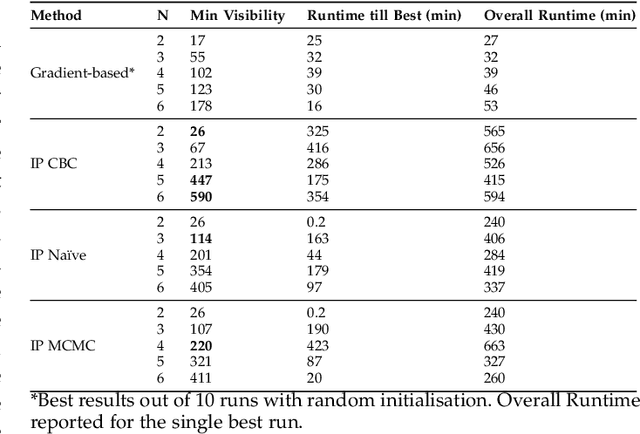
Visual Sensor Networks can be used in a variety of perception applications such as infrastructure support for autonomous driving in complex road segments. The pose of the sensors in such networks directly determines the coverage of the environment and objects therein, which impacts the performance of applications such as object detection and tracking. Existing sensor pose optimisation methods in the literature either maximise the coverage of ground surfaces, or consider the visibility of the target objects as binary variables, which cannot represent various degrees of visibility. Such formulations cannot guarantee the visibility of the target objects as they fail to consider occlusions. This paper proposes two novel sensor pose optimisation methods, based on gradient-ascent and Integer Programming techniques, which maximise the visibility of multiple target objects in cluttered environments. Both methods consider a realistic visibility model based on a rendering engine that provides pixel-level visibility information about the target objects. The proposed methods are evaluated in a complex environment and compared to existing methods in the literature. The evaluation results indicate that explicitly modelling the visibility of target objects is critical to avoid occlusions in cluttered environments. Furthermore, both methods significantly outperform existing methods in terms of object visibility.
Deep Learning-based Vehicle Behaviour Prediction For Autonomous Driving Applications: A Review
Dec 25, 2019
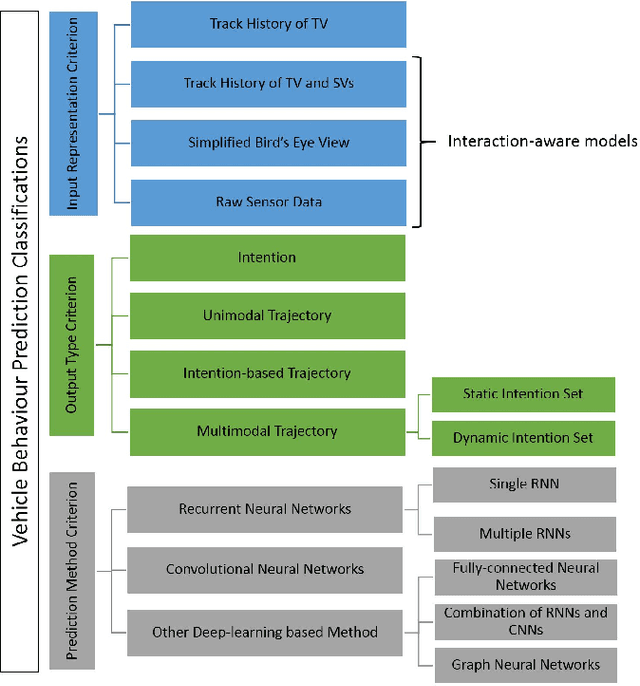

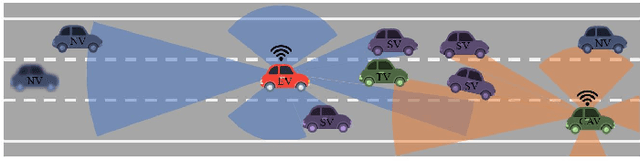
Behaviour prediction function of an autonomous vehicle predicts the future states of the nearby vehicles based on the current and past observations of the surrounding environment. This helps enhance their awareness of the imminent hazards. However, conventional behaviour prediction solutions are applicable in simple driving scenarios that require short prediction horizons. Most recently, deep learning-based approaches have become popular due to their superior performance in more complex environments compared to the conventional approaches. Motivated by this increased popularity, we provide a comprehensive review of the state-of-the-art of deep learning-based approaches for vehicle behaviour prediction in this paper. We firstly give an overview of the generic problem of vehicle behaviour prediction and discuss its challenges, followed by classification and review of the most recent deep learning-based solutions based on three criteria: input representation, output type, and prediction method. The paper also discusses the performance of several well-known solutions, identifies the research gaps in the literature and outlines potential new research directions.