 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGood Data Is All Imitation Learning Needs
Sep 26, 2024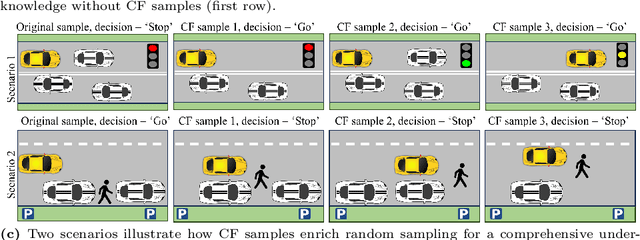
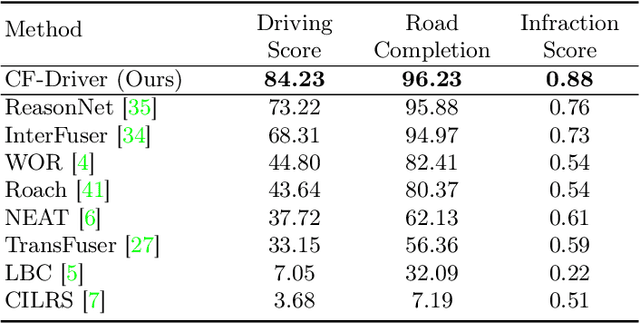
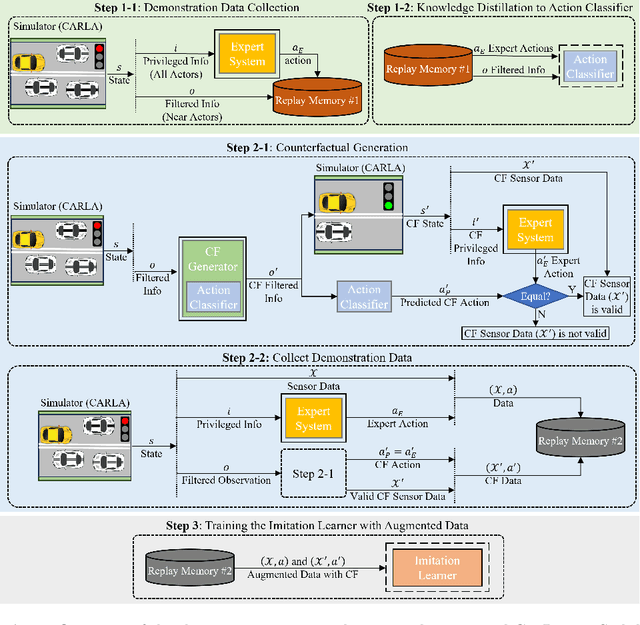

In this paper, we address the limitations of traditional teacher-student models, imitation learning, and behaviour cloning in the context of Autonomous/Automated Driving Systems (ADS), where these methods often struggle with incomplete coverage of real-world scenarios. To enhance the robustness of such models, we introduce the use of Counterfactual Explanations (CFEs) as a novel data augmentation technique for end-to-end ADS. CFEs, by generating training samples near decision boundaries through minimal input modifications, lead to a more comprehensive representation of expert driver strategies, particularly in safety-critical scenarios. This approach can therefore help improve the model's ability to handle rare and challenging driving events, such as anticipating darting out pedestrians, ultimately leading to safer and more trustworthy decision-making for ADS. Our experiments in the CARLA simulator demonstrate that CF-Driver outperforms the current state-of-the-art method, achieving a higher driving score and lower infraction rates. Specifically, CF-Driver attains a driving score of 84.2, surpassing the previous best model by 15.02 percentage points. These results highlight the effectiveness of incorporating CFEs in training end-to-end ADS. To foster further research, the CF-Driver code is made publicly available.
Towards A General-Purpose Motion Planning for Autonomous Vehicles Using Fluid Dynamics
Jun 09, 2024General-purpose motion planners for automated/autonomous vehicles promise to handle the task of motion planning (including tactical decision-making and trajectory generation) for various automated driving functions (ADF) in a diverse range of operational design domains (ODDs). The challenges of designing a general-purpose motion planner arise from several factors: a) A plethora of scenarios with different semantic information in each driving scene should be addressed, b) a strong coupling between long-term decision-making and short-term trajectory generation shall be taken into account, c) the nonholonomic constraints of the vehicle dynamics must be considered, and d) the motion planner must be computationally efficient to run in real-time. The existing methods in the literature are either limited to specific scenarios (logic-based) or are data-driven (learning-based) and therefore lack explainability, which is important for safety-critical automated driving systems (ADS). This paper proposes a novel general-purpose motion planning solution for ADS inspired by the theory of fluid mechanics. A computationally efficient technique, i.e., the lattice Boltzmann method, is then adopted to generate a spatiotemporal vector field, which in accordance with the nonholonomic dynamic model of the Ego vehicle is employed to generate feasible candidate trajectories. The trajectory optimising ride quality, efficiency and safety is finally selected to calculate the imminent control signals, i.e., throttle/brake and steering angle. The performance of the proposed approach is evaluated by simulations in highway driving, on-ramp merging, and intersection crossing scenarios, and it is found to outperform traditional motion planning solutions based on model predictive control (MPC).
A Survey on Hybrid Motion Planning Methods for Automated Driving Systems
Jun 08, 2024



Motion planning is an essential element of the modular architecture of autonomous vehicles, serving as a bridge between upstream perception modules and downstream low-level control signals. Traditional motion planners were initially designed for specific Automated Driving Functions (ADFs), yet the evolving landscape of highly automated driving systems (ADS) requires motion for a wide range of ADFs, including unforeseen ones. This need has motivated the development of the ``hybrid" approach in the literature, seeking to enhance motion planning performance by combining diverse techniques, such as data-driven (learning-based) and logic-driven (analytic) methodologies. Recent research endeavours have significantly contributed to the development of more efficient, accurate, and safe hybrid methods for Tactical Decision Making (TDM) and Trajectory Generation (TG), as well as integrating these algorithms into the motion planning module. Owing to the extensive variety and potential of hybrid methods, a timely and comprehensive review of the current literature is undertaken in this survey article. We classify the hybrid motion planners based on the types of components they incorporate, such as combinations of sampling-based with optimization-based/learning-based motion planners. The comparison of different classes is conducted by evaluating the addressed challenges and limitations, as well as assessing whether they focus on TG and/or TDM. We hope this approach will enable the researchers in this field to gain in-depth insights into the identification of current trends in hybrid motion planning and shed light on promising areas for future research.
Integrity Monitoring of 3D Object Detection in Automated Driving Systems using Raw Activation Patterns and Spatial Filtering
May 13, 2024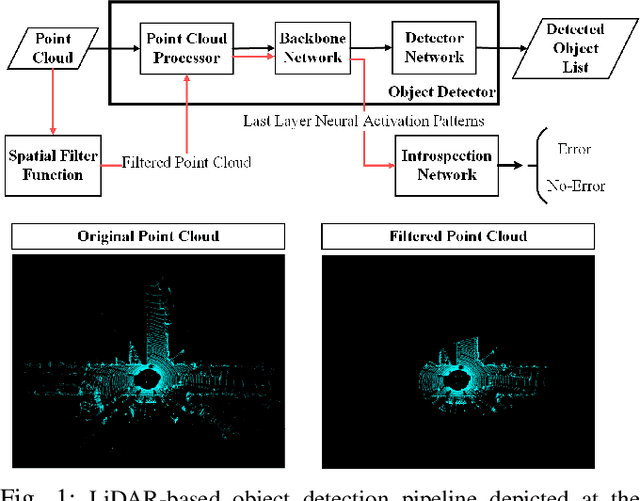

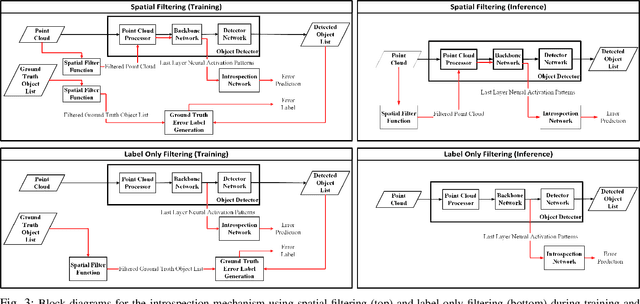
The deep neural network (DNN) models are widely used for object detection in automated driving systems (ADS). Yet, such models are prone to errors which can have serious safety implications. Introspection and self-assessment models that aim to detect such errors are therefore of paramount importance for the safe deployment of ADS. Current research on this topic has focused on techniques to monitor the integrity of the perception mechanism in ADS. Existing introspection models in the literature, however, largely concentrate on detecting perception errors by assigning equal importance to all parts of the input data frame to the perception module. This generic approach overlooks the varying safety significance of different objects within a scene, which obscures the recognition of safety-critical errors, posing challenges in assessing the reliability of perception in specific, crucial instances. Motivated by this shortcoming of state of the art, this paper proposes a novel method integrating raw activation patterns of the underlying DNNs, employed by the perception module, analysis with spatial filtering techniques. This novel approach enhances the accuracy of runtime introspection of the DNN-based 3D object detections by selectively focusing on an area of interest in the data, thereby contributing to the safety and efficacy of ADS perception self-assessment processes.
SAFE-RL: Saliency-Aware Counterfactual Explainer for Deep Reinforcement Learning Policies
Apr 28, 2024



While Deep Reinforcement Learning (DRL) has emerged as a promising solution for intricate control tasks, the lack of explainability of the learned policies impedes its uptake in safety-critical applications, such as automated driving systems (ADS). Counterfactual (CF) explanations have recently gained prominence for their ability to interpret black-box Deep Learning (DL) models. CF examples are associated with minimal changes in the input, resulting in a complementary output by the DL model. Finding such alternations, particularly for high-dimensional visual inputs, poses significant challenges. Besides, the temporal dependency introduced by the reliance of the DRL agent action on a history of past state observations further complicates the generation of CF examples. To address these challenges, we propose using a saliency map to identify the most influential input pixels across the sequence of past observed states by the agent. Then, we feed this map to a deep generative model, enabling the generation of plausible CFs with constrained modifications centred on the salient regions. We evaluate the effectiveness of our framework in diverse domains, including ADS, Atari Pong, Pacman and space-invaders games, using traditional performance metrics such as validity, proximity and sparsity. Experimental results demonstrate that this framework generates more informative and plausible CFs than the state-of-the-art for a wide range of environments and DRL agents. In order to foster research in this area, we have made our datasets and codes publicly available at https://github.com/Amir-Samadi/SAFE-RL.
Run-time Monitoring of 3D Object Detection in Automated Driving Systems Using Early Layer Neural Activation Patterns
Apr 11, 2024



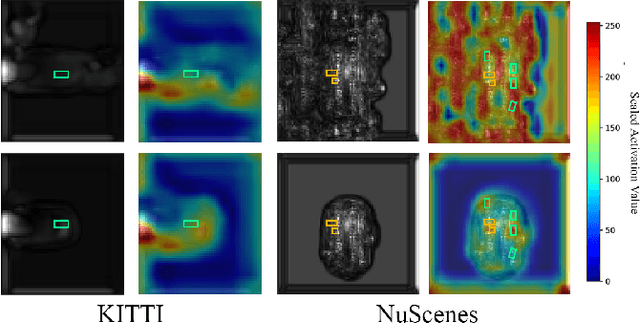
Monitoring the integrity of object detection for errors within the perception module of automated driving systems (ADS) is paramount for ensuring safety. Despite recent advancements in deep neural network (DNN)-based object detectors, their susceptibility to detection errors, particularly in the less-explored realm of 3D object detection, remains a significant concern. State-of-the-art integrity monitoring (also known as introspection) mechanisms in 2D object detection mainly utilise the activation patterns in the final layer of the DNN-based detector's backbone. However, that may not sufficiently address the complexities and sparsity of data in 3D object detection. To this end, we conduct, in this article, an extensive investigation into the effects of activation patterns extracted from various layers of the backbone network for introspecting the operation of 3D object detectors. Through a comparative analysis using Kitti and NuScenes datasets with PointPillars and CenterPoint detectors, we demonstrate that using earlier layers' activation patterns enhances the error detection performance of the integrity monitoring system, yet increases computational complexity. To address the real-time operation requirements in ADS, we also introduce a novel introspection method that combines activation patterns from multiple layers of the detector's backbone and report its performance.
Taming Transformers for Realistic Lidar Point Cloud Generation
Apr 08, 2024



Diffusion Models (DMs) have achieved State-Of-The-Art (SOTA) results in the Lidar point cloud generation task, benefiting from their stable training and iterative refinement during sampling. However, DMs often fail to realistically model Lidar raydrop noise due to their inherent denoising process. To retain the strength of iterative sampling while enhancing the generation of raydrop noise, we introduce LidarGRIT, a generative model that uses auto-regressive transformers to iteratively sample the range images in the latent space rather than image space. Furthermore, LidarGRIT utilises VQ-VAE to separately decode range images and raydrop masks. Our results show that LidarGRIT achieves superior performance compared to SOTA models on KITTI-360 and KITTI odometry datasets. Code available at:https://github.com/hamedhaghighi/LidarGRIT.
Optical Flow Based Detection and Tracking of Moving Objects for Autonomous Vehicles
Mar 26, 2024



Accurate velocity estimation of surrounding moving objects and their trajectories are critical elements of perception systems in Automated/Autonomous Vehicles (AVs) with a direct impact on their safety. These are non-trivial problems due to the diverse types and sizes of such objects and their dynamic and random behaviour. Recent point cloud based solutions often use Iterative Closest Point (ICP) techniques, which are known to have certain limitations. For example, their computational costs are high due to their iterative nature, and their estimation error often deteriorates as the relative velocities of the target objects increase (>2 m/sec). Motivated by such shortcomings, this paper first proposes a novel Detection and Tracking of Moving Objects (DATMO) for AVs based on an optical flow technique, which is proven to be computationally efficient and highly accurate for such problems. \textcolor{black}{This is achieved by representing the driving scenario as a vector field and applying vector calculus theories to ensure spatiotemporal continuity.} We also report the results of a comprehensive performance evaluation of the proposed DATMO technique, carried out in this study using synthetic and real-world data. The results of this study demonstrate the superiority of the proposed technique, compared to the DATMO techniques in the literature, in terms of estimation accuracy and processing time in a wide range of relative velocities of moving objects. Finally, we evaluate and discuss the sensitivity of the estimation error of the proposed DATMO technique to various system and environmental parameters, as well as the relative velocities of the moving objects.
Run-time Introspection of 2D Object Detection in Automated Driving Systems Using Learning Representations
Mar 02, 2024



Reliable detection of various objects and road users in the surrounding environment is crucial for the safe operation of automated driving systems (ADS). Despite recent progresses in developing highly accurate object detectors based on Deep Neural Networks (DNNs), they still remain prone to detection errors, which can lead to fatal consequences in safety-critical applications such as ADS. An effective remedy to this problem is to equip the system with run-time monitoring, named as introspection in the context of autonomous systems. Motivated by this, we introduce a novel introspection solution, which operates at the frame level for DNN-based 2D object detection and leverages neural network activation patterns. The proposed approach pre-processes the neural activation patterns of the object detector's backbone using several different modes. To provide extensive comparative analysis and fair comparison, we also adapt and implement several state-of-the-art (SOTA) introspection mechanisms for error detection in 2D object detection, using one-stage and two-stage object detectors evaluated on KITTI and BDD datasets. We compare the performance of the proposed solution in terms of error detection, adaptability to dataset shift, and, computational and memory resource requirements. Our performance evaluation shows that the proposed introspection solution outperforms SOTA methods, achieving an absolute reduction in the missed error ratio of 9% to 17% in the BDD dataset.
Benchmarking the Robustness of Panoptic Segmentation for Automated Driving
Feb 23, 2024
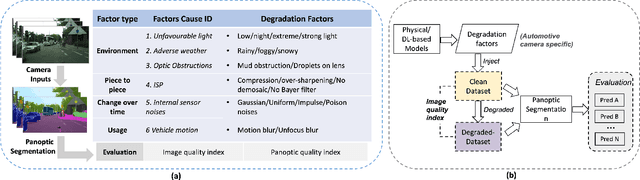


Precise situational awareness is required for the safe decision-making of assisted and automated driving (AAD) functions. Panoptic segmentation is a promising perception technique to identify and categorise objects, impending hazards, and driveable space at a pixel level. While segmentation quality is generally associated with the quality of the camera data, a comprehensive understanding and modelling of this relationship are paramount for AAD system designers. Motivated by such a need, this work proposes a unifying pipeline to assess the robustness of panoptic segmentation models for AAD, correlating it with traditional image quality. The first step of the proposed pipeline involves generating degraded camera data that reflects real-world noise factors. To this end, 19 noise factors have been identified and implemented with 3 severity levels. Of these factors, this work proposes novel models for unfavourable light and snow. After applying the degradation models, three state-of-the-art CNN- and vision transformers (ViT)-based panoptic segmentation networks are used to analyse their robustness. The variations of the segmentation performance are then correlated to 8 selected image quality metrics. This research reveals that: 1) certain specific noise factors produce the highest impact on panoptic segmentation, i.e. droplets on lens and Gaussian noise; 2) the ViT-based panoptic segmentation backbones show better robustness to the considered noise factors; 3) some image quality metrics (i.e. LPIPS and CW-SSIM) correlate strongly with panoptic segmentation performance and therefore they can be used as predictive metrics for network performance.