 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating the Impact of Weather-Induced Sensor Occlusion on BEVFusion for 3D Object Detection
Nov 06, 2025Accurate 3D object detection is essential for automated vehicles to navigate safely in complex real-world environments. Bird's Eye View (BEV) representations, which project multi-sensor data into a top-down spatial format, have emerged as a powerful approach for robust perception. Although BEV-based fusion architectures have demonstrated strong performance through multimodal integration, the effects of sensor occlusions, caused by environmental conditions such as fog, haze, or physical obstructions, on 3D detection accuracy remain underexplored. In this work, we investigate the impact of occlusions on both camera and Light Detection and Ranging (LiDAR) outputs using the BEVFusion architecture, evaluated on the nuScenes dataset. Detection performance is measured using mean Average Precision (mAP) and the nuScenes Detection Score (NDS). Our results show that moderate camera occlusions lead to a 41.3% drop in mAP (from 35.6% to 20.9%) when detection is based only on the camera. On the other hand, LiDAR sharply drops in performance only under heavy occlusion, with mAP falling by 47.3% (from 64.7% to 34.1%), with a severe impact on long-range detection. In fused settings, the effect depends on which sensor is occluded: occluding the camera leads to a minor 4.1% drop (from 68.5% to 65.7%), while occluding LiDAR results in a larger 26.8% drop (to 50.1%), revealing the model's stronger reliance on LiDAR for the task of 3D object detection. Our results highlight the need for future research into occlusion-aware evaluation methods and improved sensor fusion techniques that can maintain detection accuracy in the presence of partial sensor failure or degradation due to adverse environmental conditions.
A Target-based Multi-LiDAR Multi-Camera Extrinsic Calibration System
Jul 22, 2025Extrinsic Calibration represents the cornerstone of autonomous driving. Its accuracy plays a crucial role in the perception pipeline, as any errors can have implications for the safety of the vehicle. Modern sensor systems collect different types of data from the environment, making it harder to align the data. To this end, we propose a target-based extrinsic calibration system tailored for a multi-LiDAR and multi-camera sensor suite. This system enables cross-calibration between LiDARs and cameras with limited prior knowledge using a custom ChArUco board and a tailored nonlinear optimization method. We test the system with real-world data gathered in a warehouse. Results demonstrated the effectiveness of the proposed method, highlighting the feasibility of a unique pipeline tailored for various types of sensors.
Robustness Requirement Coverage using a Situation Coverage Approach for Vision-based AI Systems
Jul 17, 2025AI-based robots and vehicles are expected to operate safely in complex and dynamic environments, even in the presence of component degradation. In such systems, perception relies on sensors such as cameras to capture environmental data, which is then processed by AI models to support decision-making. However, degradation in sensor performance directly impacts input data quality and can impair AI inference. Specifying safety requirements for all possible sensor degradation scenarios leads to unmanageable complexity and inevitable gaps. In this position paper, we present a novel framework that integrates camera noise factor identification with situation coverage analysis to systematically elicit robustness-related safety requirements for AI-based perception systems. We focus specifically on camera degradation in the automotive domain. Building on an existing framework for identifying degradation modes, we propose involving domain, sensor, and safety experts, and incorporating Operational Design Domain specifications to extend the degradation model by incorporating noise factors relevant to AI performance. Situation coverage analysis is then applied to identify representative operational contexts. This work marks an initial step toward integrating noise factor analysis and situational coverage to support principled formulation and completeness assessment of robustness requirements for camera-based AI perception.
REHEARSE-3D: A Multi-modal Emulated Rain Dataset for 3D Point Cloud De-raining
Apr 30, 2025
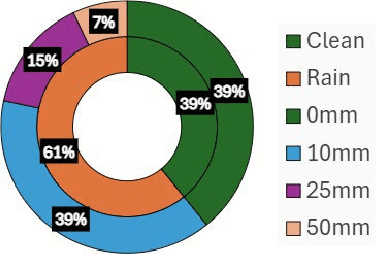
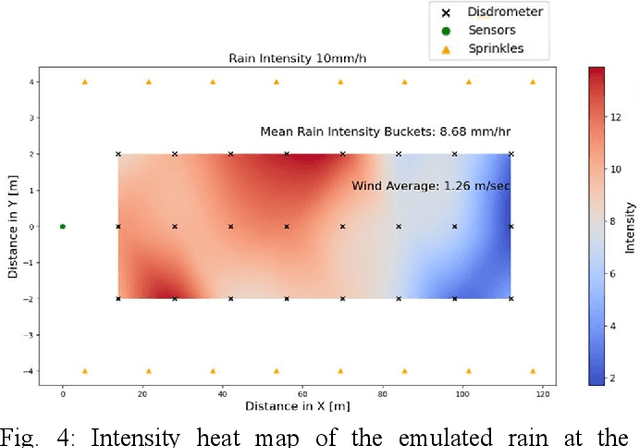
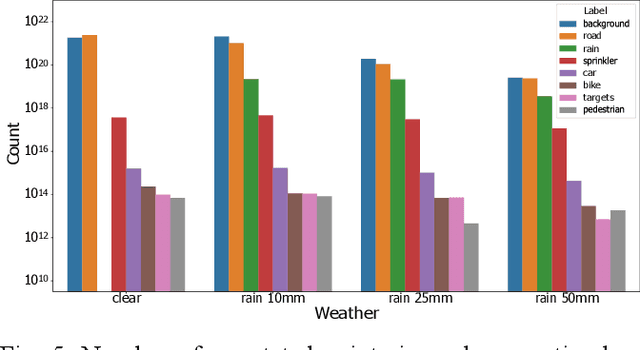
Sensor degradation poses a significant challenge in autonomous driving. During heavy rainfall, the interference from raindrops can adversely affect the quality of LiDAR point clouds, resulting in, for instance, inaccurate point measurements. This, in turn, can potentially lead to safety concerns if autonomous driving systems are not weather-aware, i.e., if they are unable to discern such changes. In this study, we release a new, large-scale, multi-modal emulated rain dataset, REHEARSE-3D, to promote research advancements in 3D point cloud de-raining. Distinct from the most relevant competitors, our dataset is unique in several respects. First, it is the largest point-wise annotated dataset, and second, it is the only one with high-resolution LiDAR data (LiDAR-256) enriched with 4D Radar point clouds logged in both daytime and nighttime conditions in a controlled weather environment. Furthermore, REHEARSE-3D involves rain-characteristic information, which is of significant value not only for sensor noise modeling but also for analyzing the impact of weather at a point level. Leveraging REHEARSE-3D, we benchmark raindrop detection and removal in fused LiDAR and 4D Radar point clouds. Our comprehensive study further evaluates the performance of various statistical and deep-learning models. Upon publication, the dataset and benchmark models will be made publicly available at: https://sporsho.github.io/REHEARSE3D.
Exploring Generative AI for Sim2Real in Driving Data Synthesis
Apr 14, 2024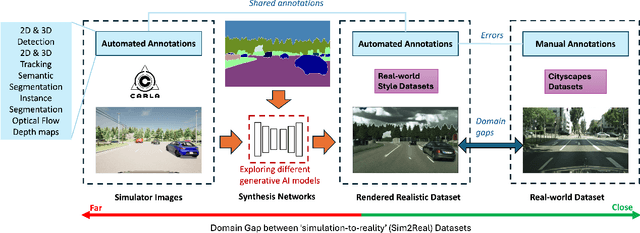



Datasets are essential for training and testing vehicle perception algorithms. However, the collection and annotation of real-world images is time-consuming and expensive. Driving simulators offer a solution by automatically generating various driving scenarios with corresponding annotations, but the simulation-to-reality (Sim2Real) domain gap remains a challenge. While most of the Generative Artificial Intelligence (AI) follows the de facto Generative Adversarial Nets (GANs)-based methods, the recent emerging diffusion probabilistic models have not been fully explored in mitigating Sim2Real challenges for driving data synthesis. To explore the performance, this paper applied three different generative AI methods to leverage semantic label maps from a driving simulator as a bridge for the creation of realistic datasets. A comparative analysis of these methods is presented from the perspective of image quality and perception. New synthetic datasets, which include driving images and auto-generated high-quality annotations, are produced with low costs and high scene variability. The experimental results show that although GAN-based methods are adept at generating high-quality images when provided with manually annotated labels, ControlNet produces synthetic datasets with fewer artefacts and more structural fidelity when using simulator-generated labels. This suggests that the diffusion-based approach may provide improved stability and an alternative method for addressing Sim2Real challenges.
Taming Transformers for Realistic Lidar Point Cloud Generation
Apr 08, 2024



Diffusion Models (DMs) have achieved State-Of-The-Art (SOTA) results in the Lidar point cloud generation task, benefiting from their stable training and iterative refinement during sampling. However, DMs often fail to realistically model Lidar raydrop noise due to their inherent denoising process. To retain the strength of iterative sampling while enhancing the generation of raydrop noise, we introduce LidarGRIT, a generative model that uses auto-regressive transformers to iteratively sample the range images in the latent space rather than image space. Furthermore, LidarGRIT utilises VQ-VAE to separately decode range images and raydrop masks. Our results show that LidarGRIT achieves superior performance compared to SOTA models on KITTI-360 and KITTI odometry datasets. Code available at:https://github.com/hamedhaghighi/LidarGRIT.
Benchmarking the Robustness of Panoptic Segmentation for Automated Driving
Feb 23, 2024
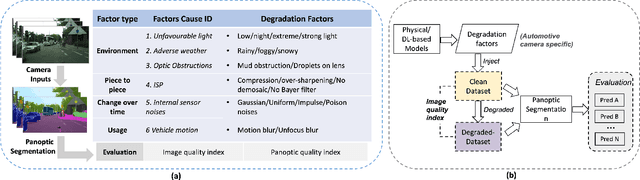


Precise situational awareness is required for the safe decision-making of assisted and automated driving (AAD) functions. Panoptic segmentation is a promising perception technique to identify and categorise objects, impending hazards, and driveable space at a pixel level. While segmentation quality is generally associated with the quality of the camera data, a comprehensive understanding and modelling of this relationship are paramount for AAD system designers. Motivated by such a need, this work proposes a unifying pipeline to assess the robustness of panoptic segmentation models for AAD, correlating it with traditional image quality. The first step of the proposed pipeline involves generating degraded camera data that reflects real-world noise factors. To this end, 19 noise factors have been identified and implemented with 3 severity levels. Of these factors, this work proposes novel models for unfavourable light and snow. After applying the degradation models, three state-of-the-art CNN- and vision transformers (ViT)-based panoptic segmentation networks are used to analyse their robustness. The variations of the segmentation performance are then correlated to 8 selected image quality metrics. This research reveals that: 1) certain specific noise factors produce the highest impact on panoptic segmentation, i.e. droplets on lens and Gaussian noise; 2) the ViT-based panoptic segmentation backbones show better robustness to the considered noise factors; 3) some image quality metrics (i.e. LPIPS and CW-SSIM) correlate strongly with panoptic segmentation performance and therefore they can be used as predictive metrics for network performance.
Contrastive Learning-Based Framework for Sim-to-Real Mapping of Lidar Point Clouds in Autonomous Driving Systems
Dec 25, 2023



Perception sensor models are essential elements of automotive simulation environments; they also serve as powerful tools for creating synthetic datasets to train deep learning-based perception models. Developing realistic perception sensor models poses a significant challenge due to the large gap between simulated sensor data and real-world sensor outputs, known as the sim-to-real gap. To address this problem, learning-based models have emerged as promising solutions in recent years, with unparalleled potential to map low-fidelity simulated sensor data into highly realistic outputs. Motivated by this potential, this paper focuses on sim-to-real mapping of Lidar point clouds, a widely used perception sensor in automated driving systems. We introduce a novel Contrastive-Learning-based Sim-to-Real mapping framework, namely CLS2R, inspired by the recent advancements in image-to-image translation techniques. The proposed CLS2R framework employs a lossless representation of Lidar point clouds, considering all essential Lidar attributes such as depth, reflectance, and raydrop. We extensively evaluate the proposed framework, comparing it with state-of-the-art image-to-image translation methods using a diverse range of metrics to assess realness, faithfulness, and the impact on the performance of a downstream task. Our results show that CLS2R demonstrates superior performance across nearly all metrics. Source code is available at https://github.com/hamedhaghighi/CLS2R.git.