 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDriveCtrl: Conditioned Sim-to-Real Driving Video Generation
May 14, 2026Large-scale labelled driving video data is essential for training autonomous driving systems. Although simulation offers scalable and fully annotated data, the domain gap between synthetic and real-world driving videos significantly limits its utility for downstream deployment. Existing video generation methods are not well-suited for this task, as they fail to simultaneously preserve scene structure, object dynamics, temporal consistency, and visual realism, all of which are critical for maintaining annotation validity in generated data. In this paper, we present DriveCtrl, a depth-conditioned controllable sim-to-real video generation framework for realistic driving video synthesis. Built upon a pretrained video foundation model, DriveCtrl introduces a structure-aware adapter that enables depth-guided generation while preserving the scene layout and motion patterns of the source simulation, producing temporally coherent driving videos that remain aligned with the original simulated sequences. We further introduce a scalable data generation pipeline that transforms simulator videos into realistic driving footage matching the visual style of a target real-world dataset. The pipeline supports three conditioning signals: structural depth, reference-dataset style, and text prompts, while preserving frame-level annotations for downstream perception tasks. To better assess this task, we propose a driving-domain-specific knowledge-informed evaluation metric called Driving Video Realism Score (DVRS) that assesses the realism of generated videos. Experiments demonstrate that DriveCtrl consistently outperforms the base model and competing alternatives in realism, temporal quality, and perception task performance, substantially narrowing the sim-to-real gap for driving video generation.
Luminance Component Analysis for Exposure Correction
Nov 25, 2024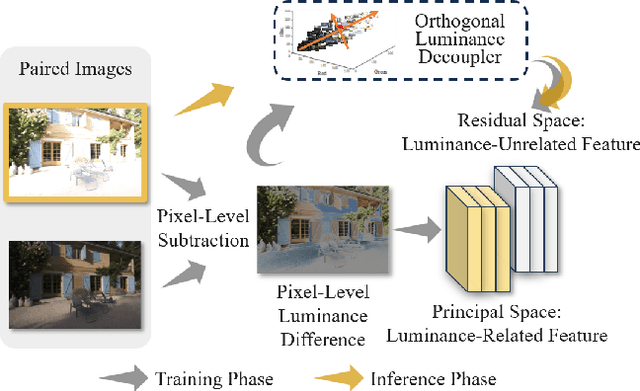

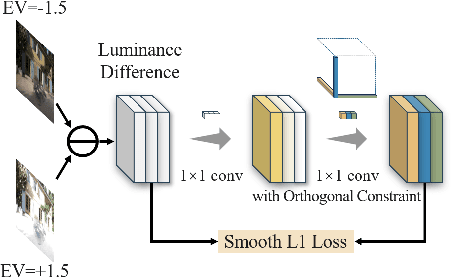

Exposure correction methods aim to adjust the luminance while maintaining other luminance-unrelated information. However, current exposure correction methods have difficulty in fully separating luminance-related and luminance-unrelated components, leading to distortions in color, loss of detail, and requiring extra restoration procedures. Inspired by principal component analysis (PCA), this paper proposes an exposure correction method called luminance component analysis (LCA). LCA applies the orthogonal constraint to a U-Net structure to decouple luminance-related and luminance-unrelated features. With decoupled luminance-related features, LCA adjusts only the luminance-related components while keeping the luminance-unrelated components unchanged. To optimize the orthogonal constraint problem, LCA employs a geometric optimization algorithm, which converts the constrained problem in Euclidean space to an unconstrained problem in orthogonal Stiefel manifolds. Extensive experiments show that LCA can decouple the luminance feature from the RGB color space. Moreover, LCA achieves the best PSNR (21.33) and SSIM (0.88) in the exposure correction dataset with 28.72 FPS.
CapHDR2IR: Caption-Driven Transfer from Visible Light to Infrared Domain
Nov 25, 2024
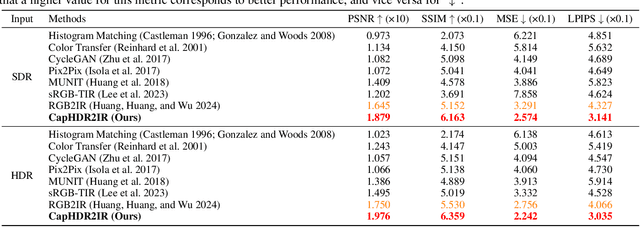

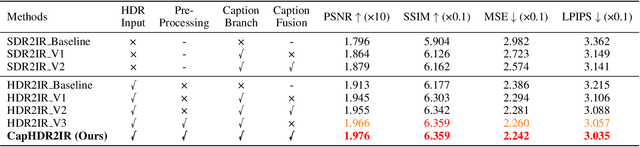
Infrared (IR) imaging offers advantages in several fields due to its unique ability of capturing content in extreme light conditions. However, the demanding hardware requirements of high-resolution IR sensors limit its widespread application. As an alternative, visible light can be used to synthesize IR images but this causes a loss of fidelity in image details and introduces inconsistencies due to lack of contextual awareness of the scene. This stems from a combination of using visible light with a standard dynamic range, especially under extreme lighting, and a lack of contextual awareness can result in pseudo-thermal-crossover artifacts. This occurs when multiple objects with similar temperatures appear indistinguishable in the training data, further exacerbating the loss of fidelity. To solve this challenge, this paper proposes CapHDR2IR, a novel framework incorporating vision-language models using high dynamic range (HDR) images as inputs to generate IR images. HDR images capture a wider range of luminance variations, ensuring reliable IR image generation in different light conditions. Additionally, a dense caption branch integrates semantic understanding, resulting in more meaningful and discernible IR outputs. Extensive experiments on the HDRT dataset show that the proposed CapHDR2IR achieves state-of-the-art performance compared with existing general domain transfer methods and those tailored for visible-to-infrared image translation.
HDRT: Infrared Capture for HDR Imaging
Jun 08, 2024
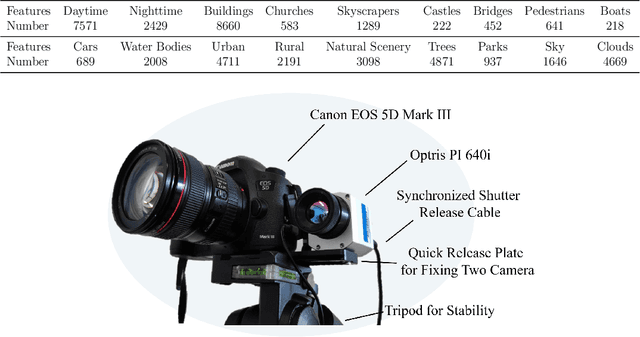
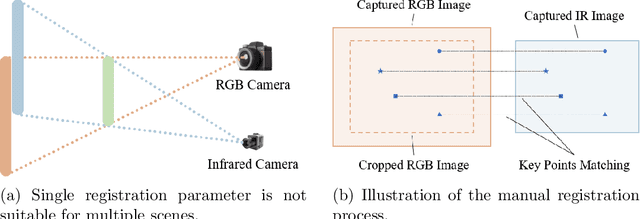
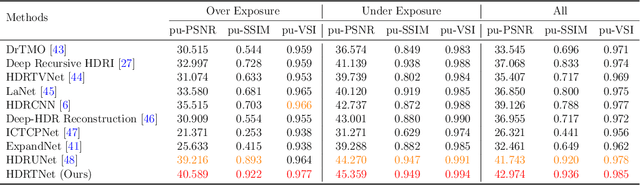
Capturing real world lighting is a long standing challenge in imaging and most practical methods acquire High Dynamic Range (HDR) images by either fusing multiple exposures, or boosting the dynamic range of Standard Dynamic Range (SDR) images. Multiple exposure capture is problematic as it requires longer capture times which can often lead to ghosting problems. The main alternative, inverse tone mapping is an ill-defined problem that is especially challenging as single captured exposures usually contain clipped and quantized values, and are therefore missing substantial amounts of content. To alleviate this, we propose a new approach, High Dynamic Range Thermal (HDRT), for HDR acquisition using a separate, commonly available, thermal infrared (IR) sensor. We propose a novel deep neural method (HDRTNet) which combines IR and SDR content to generate HDR images. HDRTNet learns to exploit IR features linked to the RGB image and the IR-specific parameters are subsequently used in a dual branch method that fuses features at shallow layers. This produces an HDR image that is significantly superior to that generated using naive fusion approaches. To validate our method, we have created the first HDR and thermal dataset, and performed extensive experiments comparing HDRTNet with the state-of-the-art. We show substantial quantitative and qualitative quality improvements on both over- and under-exposed images, showing that our approach is robust to capturing in multiple different lighting conditions.
Semantic Aware Diffusion Inverse Tone Mapping
May 24, 2024



The range of real-world scene luminance is larger than the capture capability of many digital camera sensors which leads to details being lost in captured images, most typically in bright regions. Inverse tone mapping attempts to boost these captured Standard Dynamic Range (SDR) images back to High Dynamic Range (HDR) by creating a mapping that linearizes the well exposed values from the SDR image, and provides a luminance boost to the clipped content. However, in most cases, the details in the clipped regions cannot be recovered or estimated. In this paper, we present a novel inverse tone mapping approach for mapping SDR images to HDR that generates lost details in clipped regions through a semantic-aware diffusion based inpainting approach. Our method proposes two major contributions - first, we propose to use a semantic graph to guide SDR diffusion based inpainting in masked regions in a saturated image. Second, drawing inspiration from traditional HDR imaging and bracketing methods, we propose a principled formulation to lift the SDR inpainted regions to HDR that is compatible with generative inpainting methods. Results show that our method demonstrates superior performance across different datasets on objective metrics, and subjective experiments show that the proposed method matches (and in most cases outperforms) state-of-art inverse tone mapping operators in terms of objective metrics and outperforms them for visual fidelity.
Exploring Generative AI for Sim2Real in Driving Data Synthesis
Apr 14, 2024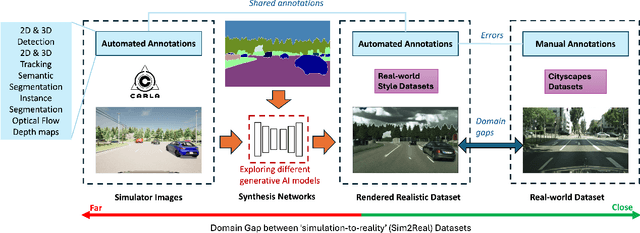



Datasets are essential for training and testing vehicle perception algorithms. However, the collection and annotation of real-world images is time-consuming and expensive. Driving simulators offer a solution by automatically generating various driving scenarios with corresponding annotations, but the simulation-to-reality (Sim2Real) domain gap remains a challenge. While most of the Generative Artificial Intelligence (AI) follows the de facto Generative Adversarial Nets (GANs)-based methods, the recent emerging diffusion probabilistic models have not been fully explored in mitigating Sim2Real challenges for driving data synthesis. To explore the performance, this paper applied three different generative AI methods to leverage semantic label maps from a driving simulator as a bridge for the creation of realistic datasets. A comparative analysis of these methods is presented from the perspective of image quality and perception. New synthetic datasets, which include driving images and auto-generated high-quality annotations, are produced with low costs and high scene variability. The experimental results show that although GAN-based methods are adept at generating high-quality images when provided with manually annotated labels, ControlNet produces synthetic datasets with fewer artefacts and more structural fidelity when using simulator-generated labels. This suggests that the diffusion-based approach may provide improved stability and an alternative method for addressing Sim2Real challenges.
Deep Dynamic Cloud Lighting
Apr 18, 2023



Sky illumination is a core source of lighting in rendering, and a substantial amount of work has been developed to simulate lighting from clear skies. However, in reality, clouds substantially alter the appearance of the sky and subsequently change the scene's illumination. While there have been recent advances in developing sky models which include clouds, these all neglect cloud movement which is a crucial component of cloudy sky appearance. In any sort of video or interactive environment, it can be expected that clouds will move, sometimes quite substantially in a short period of time. Our work proposes a solution to this which enables whole-sky dynamic cloud synthesis for the first time. We achieve this by proposing a multi-timescale sky appearance model which learns to predict the sky illumination over various timescales, and can be used to add dynamism to previous static, cloudy sky lighting approaches.
Unsupervised HDR Imaging: What Can Be Learned from a Single 8-bit Video?
Feb 11, 2022



Recently, Deep Learning-based methods for inverse tone-mapping standard dynamic range (SDR) images to obtain high dynamic range (HDR) images have become very popular. These methods manage to fill over-exposed areas convincingly both in terms of details and dynamic range. Typically, these methods, to be effective, need to learn from large datasets and to transfer this knowledge to the network weights. In this work, we tackle this problem from a completely different perspective. What can we learn from a single SDR video? With the presented zero-shot approach, we show that, in many cases, a single SDR video is sufficient to be able to generate an HDR video of the same quality or better than other state-of-the-art methods.
Deep HDR Hallucination for Inverse Tone Mapping
Jun 17, 2021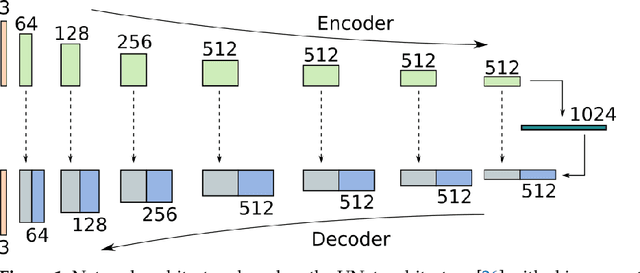

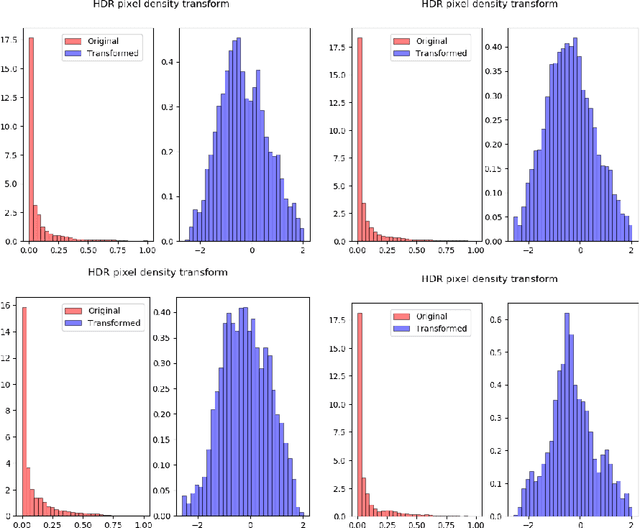

Inverse Tone Mapping (ITM) methods attempt to reconstruct High Dynamic Range (HDR) information from Low Dynamic Range (LDR) image content. The dynamic range of well-exposed areas must be expanded and any missing information due to over/under-exposure must be recovered (hallucinated). The majority of methods focus on the former and are relatively successful, while most attempts on the latter are not of sufficient quality, even ones based on Convolutional Neural Networks (CNNs). A major factor for the reduced inpainting quality in some works is the choice of loss function. Work based on Generative Adversarial Networks (GANs) shows promising results for image synthesis and LDR inpainting, suggesting that GAN losses can improve inverse tone mapping results. This work presents a GAN-based method that hallucinates missing information from badly exposed areas in LDR images and compares its efficacy with alternative variations. The proposed method is quantitatively competitive with state-of-the-art inverse tone mapping methods, providing good dynamic range expansion for well-exposed areas and plausible hallucinations for saturated and under-exposed areas. A density-based normalisation method, targeted for HDR content, is also proposed, as well as an HDR data augmentation method targeted for HDR hallucination.
Spectrally Consistent UNet for High Fidelity Image Transformations
Apr 22, 2020

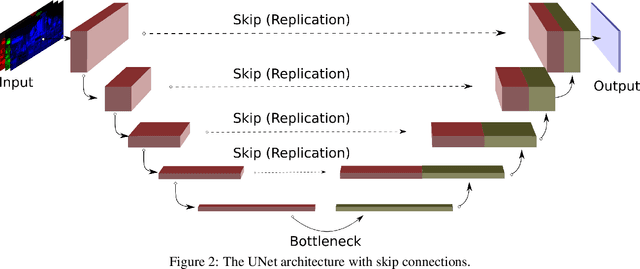

Convolutional Neural Networks (CNNs) are the current de-facto approach used for many imaging tasks due to their high learning capacity as well as their architectural qualities. The ubiquitous UNet architecture provides an efficient and multi-scale solution that combines local and global information. Despite the success of UNet architectures, the use of upsampling layers can cause checkerboard artefacts or blurring. In this work, a method for assessing the structural biases of UNets and the effects these have on the outputs is presented, characterising their impact in the Fourier domain. A new upsampling module is then proposed, based on a novel generalisation of the Guided Image Filter, that provides spectrally consistent outputs when used in a UNet architecture, forming the Guided UNet (GUNet). The GUNet architecture is evaluated quantitatively and qualitatively in an example application of dynamic range expansion for high dynamic range imaging. The proposed method provides higher fidelity results, while executing faster and consuming less memory than other dedicated architectures that avoid upsampling.