 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynamic Tsetlin Machine Accelerators for On-Chip Training at the Edge using FPGAs
Apr 28, 2025The increased demand for data privacy and security in machine learning (ML) applications has put impetus on effective edge training on Internet-of-Things (IoT) nodes. Edge training aims to leverage speed, energy efficiency and adaptability within the resource constraints of the nodes. Deploying and training Deep Neural Networks (DNNs)-based models at the edge, although accurate, posit significant challenges from the back-propagation algorithm's complexity, bit precision trade-offs, and heterogeneity of DNN layers. This paper presents a Dynamic Tsetlin Machine (DTM) training accelerator as an alternative to DNN implementations. DTM utilizes logic-based on-chip inference with finite-state automata-driven learning within the same Field Programmable Gate Array (FPGA) package. Underpinned on the Vanilla and Coalesced Tsetlin Machine algorithms, the dynamic aspect of the accelerator design allows for a run-time reconfiguration targeting different datasets, model architectures, and model sizes without resynthesis. This makes the DTM suitable for targeting multivariate sensor-based edge tasks. Compared to DNNs, DTM trains with fewer multiply-accumulates, devoid of derivative computation. It is a data-centric ML algorithm that learns by aligning Tsetlin automata with input data to form logical propositions enabling efficient Look-up-Table (LUT) mapping and frugal Block RAM usage in FPGA training implementations. The proposed accelerator offers 2.54x more Giga operations per second per Watt (GOP/s per W) and uses 6x less power than the next-best comparable design.
CapHDR2IR: Caption-Driven Transfer from Visible Light to Infrared Domain
Nov 25, 2024
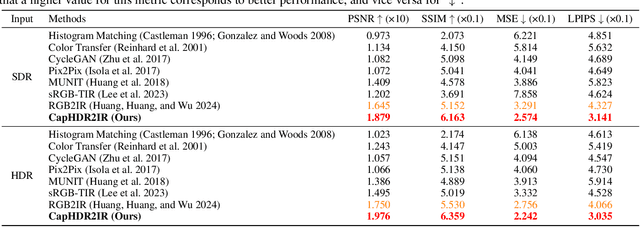

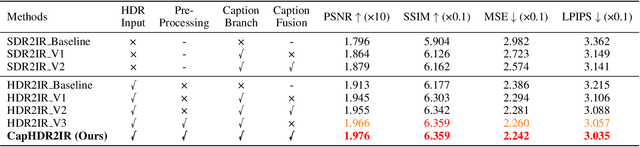
Infrared (IR) imaging offers advantages in several fields due to its unique ability of capturing content in extreme light conditions. However, the demanding hardware requirements of high-resolution IR sensors limit its widespread application. As an alternative, visible light can be used to synthesize IR images but this causes a loss of fidelity in image details and introduces inconsistencies due to lack of contextual awareness of the scene. This stems from a combination of using visible light with a standard dynamic range, especially under extreme lighting, and a lack of contextual awareness can result in pseudo-thermal-crossover artifacts. This occurs when multiple objects with similar temperatures appear indistinguishable in the training data, further exacerbating the loss of fidelity. To solve this challenge, this paper proposes CapHDR2IR, a novel framework incorporating vision-language models using high dynamic range (HDR) images as inputs to generate IR images. HDR images capture a wider range of luminance variations, ensuring reliable IR image generation in different light conditions. Additionally, a dense caption branch integrates semantic understanding, resulting in more meaningful and discernible IR outputs. Extensive experiments on the HDRT dataset show that the proposed CapHDR2IR achieves state-of-the-art performance compared with existing general domain transfer methods and those tailored for visible-to-infrared image translation.
Deep Intra-Image Contrastive Learning for Weakly Supervised One-Step Person Search
Feb 09, 2023Weakly supervised person search aims to perform joint pedestrian detection and re-identification (re-id) with only person bounding-box annotations. Recently, the idea of contrastive learning is initially applied to weakly supervised person search, where two common contrast strategies are memory-based contrast and intra-image contrast. We argue that current intra-image contrast is shallow, which suffers from spatial-level and occlusion-level variance. In this paper, we present a novel deep intra-image contrastive learning using a Siamese network. Two key modules are spatial-invariant contrast (SIC) and occlusion-invariant contrast (OIC). SIC performs many-to-one contrasts between two branches of Siamese network and dense prediction contrasts in one branch of Siamese network. With these many-to-one and dense contrasts, SIC tends to learn discriminative scale-invariant and location-invariant features to solve spatial-level variance. OIC enhances feature consistency with the masking strategy to learn occlusion-invariant features. Extensive experiments are performed on two person search datasets CUHK-SYSU and PRW, respectively. Our method achieves a state-of-the-art performance among weakly supervised one-step person search approaches. We hope that our simple intra-image contrastive learning can provide more paradigms on weakly supervised person search. The source code is available at \url{https://github.com/jiabeiwangTJU/DICL}.
Memory-Efficient CNN Accelerator Based on Interlayer Feature Map Compression
Oct 12, 2021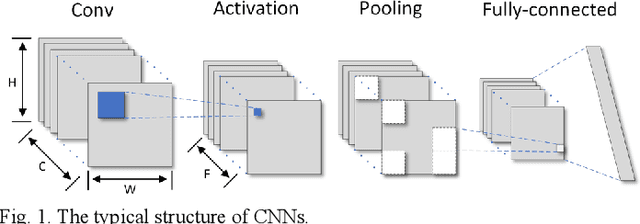
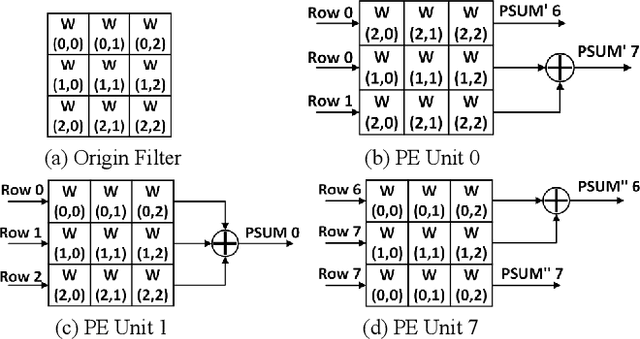
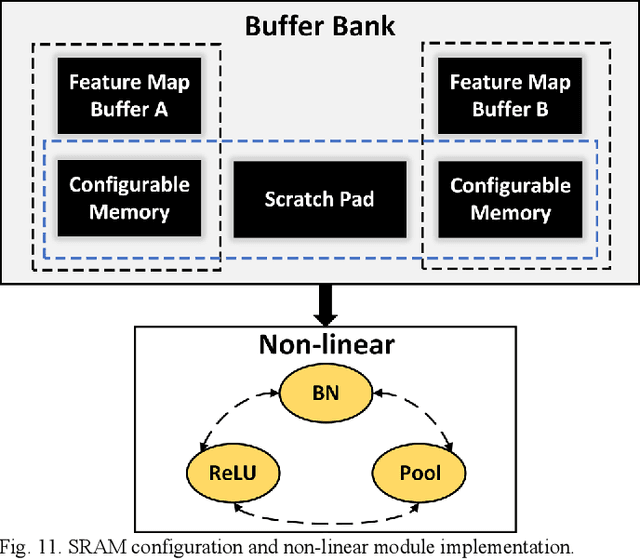
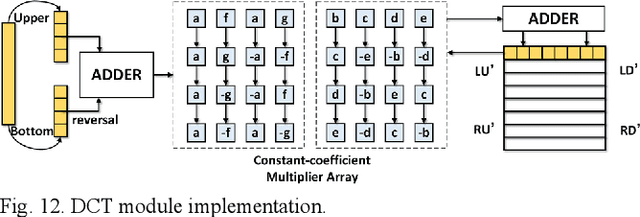
Existing deep convolutional neural networks (CNNs) generate massive interlayer feature data during network inference. To maintain real-time processing in embedded systems, large on-chip memory is required to buffer the interlayer feature maps. In this paper, we propose an efficient hardware accelerator with an interlayer feature compression technique to significantly reduce the required on-chip memory size and off-chip memory access bandwidth. The accelerator compresses interlayer feature maps through transforming the stored data into frequency domain using hardware-implemented 8x8 discrete cosine transform (DCT). The high-frequency components are removed after the DCT through quantization. Sparse matrix compression is utilized to further compress the interlayer feature maps. The on-chip memory allocation scheme is designed to support dynamic configuration of the feature map buffer size and scratch pad size according to different network-layer requirements. The hardware accelerator combines compression, decompression, and CNN acceleration into one computing stream, achieving minimal compressing and processing delay. A prototype accelerator is implemented on an FPGA platform and also synthesized in TSMC 28-nm COMS technology. It achieves 403GOPS peak throughput and 1.4x~3.3x interlayer feature map reduction by adding light hardware area overhead, making it a promising hardware accelerator for intelligent IoT devices.