 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised Patch-GAN with Targeted Patch Ranking for Fine-Grained Novelty Detection in Medical Imaging
Jan 29, 2025



Detecting novel anomalies in medical imaging is challenging due to the limited availability of labeled data for rare abnormalities, which often display high variability and subtlety. This challenge is further compounded when small abnormal regions are embedded within larger normal areas, as whole-image predictions frequently overlook these subtle deviations. To address these issues, we propose an unsupervised Patch-GAN framework designed to detect and localize anomalies by capturing both local detail and global structure. Our framework first reconstructs masked images to learn fine-grained, normal-specific features, allowing for enhanced sensitivity to minor deviations from normality. By dividing these reconstructed images into patches and assessing the authenticity of each patch, our approach identifies anomalies at a more granular level, overcoming the limitations of whole-image evaluation. Additionally, a patch-ranking mechanism prioritizes regions with higher abnormal scores, reinforcing the alignment between local patch discrepancies and the global image context. Experimental results on the ISIC 2016 skin lesion and BraTS 2019 brain tumor datasets validate our framework's effectiveness, achieving AUCs of 95.79% and 96.05%, respectively, and outperforming three state-of-the-art baselines.
Luminance Component Analysis for Exposure Correction
Nov 25, 2024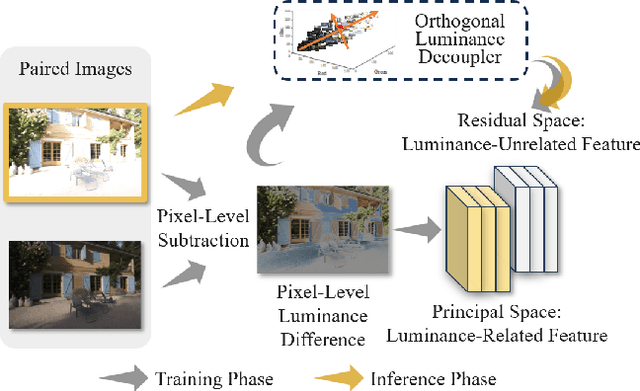

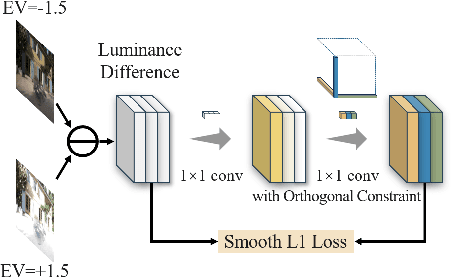

Exposure correction methods aim to adjust the luminance while maintaining other luminance-unrelated information. However, current exposure correction methods have difficulty in fully separating luminance-related and luminance-unrelated components, leading to distortions in color, loss of detail, and requiring extra restoration procedures. Inspired by principal component analysis (PCA), this paper proposes an exposure correction method called luminance component analysis (LCA). LCA applies the orthogonal constraint to a U-Net structure to decouple luminance-related and luminance-unrelated features. With decoupled luminance-related features, LCA adjusts only the luminance-related components while keeping the luminance-unrelated components unchanged. To optimize the orthogonal constraint problem, LCA employs a geometric optimization algorithm, which converts the constrained problem in Euclidean space to an unconstrained problem in orthogonal Stiefel manifolds. Extensive experiments show that LCA can decouple the luminance feature from the RGB color space. Moreover, LCA achieves the best PSNR (21.33) and SSIM (0.88) in the exposure correction dataset with 28.72 FPS.
CapHDR2IR: Caption-Driven Transfer from Visible Light to Infrared Domain
Nov 25, 2024
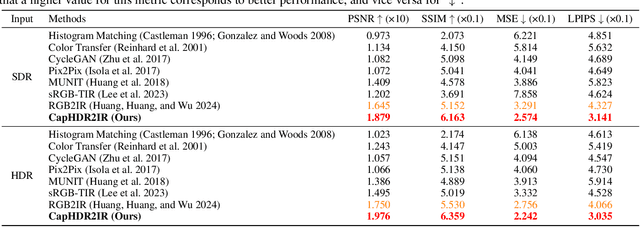

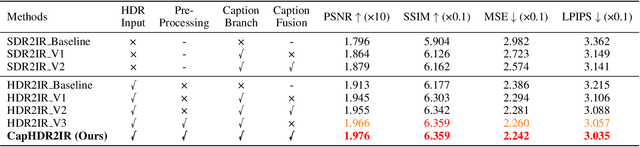
Infrared (IR) imaging offers advantages in several fields due to its unique ability of capturing content in extreme light conditions. However, the demanding hardware requirements of high-resolution IR sensors limit its widespread application. As an alternative, visible light can be used to synthesize IR images but this causes a loss of fidelity in image details and introduces inconsistencies due to lack of contextual awareness of the scene. This stems from a combination of using visible light with a standard dynamic range, especially under extreme lighting, and a lack of contextual awareness can result in pseudo-thermal-crossover artifacts. This occurs when multiple objects with similar temperatures appear indistinguishable in the training data, further exacerbating the loss of fidelity. To solve this challenge, this paper proposes CapHDR2IR, a novel framework incorporating vision-language models using high dynamic range (HDR) images as inputs to generate IR images. HDR images capture a wider range of luminance variations, ensuring reliable IR image generation in different light conditions. Additionally, a dense caption branch integrates semantic understanding, resulting in more meaningful and discernible IR outputs. Extensive experiments on the HDRT dataset show that the proposed CapHDR2IR achieves state-of-the-art performance compared with existing general domain transfer methods and those tailored for visible-to-infrared image translation.
HDRT: Infrared Capture for HDR Imaging
Jun 08, 2024
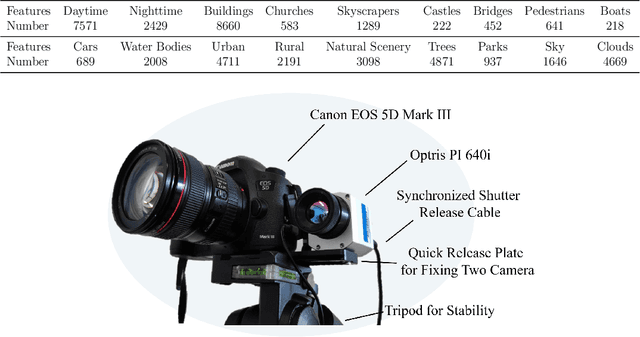
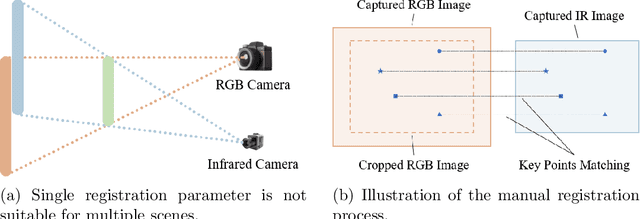
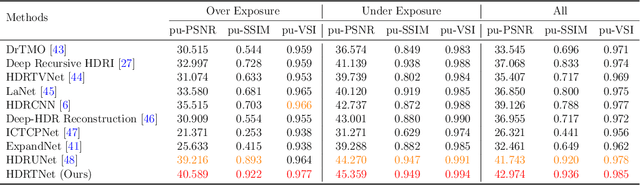
Capturing real world lighting is a long standing challenge in imaging and most practical methods acquire High Dynamic Range (HDR) images by either fusing multiple exposures, or boosting the dynamic range of Standard Dynamic Range (SDR) images. Multiple exposure capture is problematic as it requires longer capture times which can often lead to ghosting problems. The main alternative, inverse tone mapping is an ill-defined problem that is especially challenging as single captured exposures usually contain clipped and quantized values, and are therefore missing substantial amounts of content. To alleviate this, we propose a new approach, High Dynamic Range Thermal (HDRT), for HDR acquisition using a separate, commonly available, thermal infrared (IR) sensor. We propose a novel deep neural method (HDRTNet) which combines IR and SDR content to generate HDR images. HDRTNet learns to exploit IR features linked to the RGB image and the IR-specific parameters are subsequently used in a dual branch method that fuses features at shallow layers. This produces an HDR image that is significantly superior to that generated using naive fusion approaches. To validate our method, we have created the first HDR and thermal dataset, and performed extensive experiments comparing HDRTNet with the state-of-the-art. We show substantial quantitative and qualitative quality improvements on both over- and under-exposed images, showing that our approach is robust to capturing in multiple different lighting conditions.
ODCR: Orthogonal Decoupling Contrastive Regularization for Unpaired Image Dehazing
Apr 27, 2024



Unpaired image dehazing (UID) holds significant research importance due to the challenges in acquiring haze/clear image pairs with identical backgrounds. This paper proposes a novel method for UID named Orthogonal Decoupling Contrastive Regularization (ODCR). Our method is grounded in the assumption that an image consists of both haze-related features, which influence the degree of haze, and haze-unrelated features, such as texture and semantic information. ODCR aims to ensure that the haze-related features of the dehazing result closely resemble those of the clear image, while the haze-unrelated features align with the input hazy image. To accomplish the motivation, Orthogonal MLPs optimized geometrically on the Stiefel manifold are proposed, which can project image features into an orthogonal space, thereby reducing the relevance between different features. Furthermore, a task-driven Depth-wise Feature Classifier (DWFC) is proposed, which assigns weights to the orthogonal features based on the contribution of each channel's feature in predicting whether the feature source is hazy or clear in a self-supervised fashion. Finally, a Weighted PatchNCE (WPNCE) loss is introduced to achieve the pulling of haze-related features in the output image toward those of clear images, while bringing haze-unrelated features close to those of the hazy input. Extensive experiments demonstrate the superior performance of our ODCR method on UID.
DFR-Net: Density Feature Refinement Network for Image Dehazing Utilizing Haze Density Difference
Jul 26, 2023



In image dehazing task, haze density is a key feature and affects the performance of dehazing methods. However, some of the existing methods lack a comparative image to measure densities, and others create intermediate results but lack the exploitation of their density differences, which can facilitate perception of density. To address these deficiencies, we propose a density-aware dehazing method named Density Feature Refinement Network (DFR-Net) that extracts haze density features from density differences and leverages density differences to refine density features. In DFR-Net, we first generate a proposal image that has lower overall density than the hazy input, bringing in global density differences. Additionally, the dehazing residual of the proposal image reflects the level of dehazing performance and provides local density differences that indicate localized hard dehazing or high density areas. Subsequently, we introduce a Global Branch (GB) and a Local Branch (LB) to achieve density-awareness. In GB, we use Siamese networks for feature extraction of hazy inputs and proposal images, and we propose a Global Density Feature Refinement (GDFR) module that can refine features by pushing features with different global densities further away. In LB, we explore local density features from the dehazing residuals between hazy inputs and proposal images and introduce an Intermediate Dehazing Residual Feedforward (IDRF) module to update local features and pull them closer to clear image features. Sufficient experiments demonstrate that the proposed method achieves results beyond the state-of-the-art methods on various datasets.
FoSp: Focus and Separation Network for Early Smoke Segmentation
Jun 07, 2023


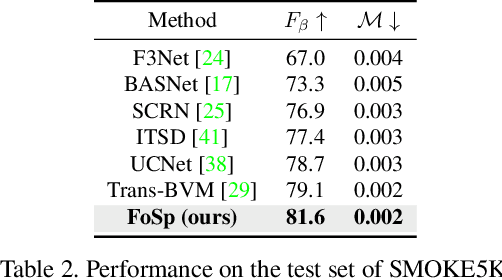
Early smoke segmentation (ESS) enables the accurate identification of smoke sources, facilitating the prompt extinguishing of fires and preventing large-scale gas leaks. But ESS poses greater challenges than conventional object and regular smoke segmentation due to its small scale and transparent appearance, which can result in high miss detection rate and low precision. To address these issues, a Focus and Separation Network (FoSp) is proposed. We first introduce a Focus module employing bidirectional cascade which guides low-resolution and high-resolution features towards mid-resolution to locate and determine the scope of smoke, reducing the miss detection rate. Next, we propose a Separation module that separates smoke images into a pure smoke foreground and a smoke-free background, enhancing the contrast between smoke and background fundamentally, improving segmentation precision. Finally, a Domain Fusion module is developed to integrate the distinctive features of the two modules which can balance recall and precision to achieve high F_beta. Futhermore, to promote the development of ESS, we introduce a high-quality real-world dataset called SmokeSeg, which contains more small and transparent smoke than the existing datasets. Experimental results show that our model achieves the best performance on three available datasets: SYN70K (mIoU: 83.00%), SMOKE5K (F_beta: 81.6%) and SmokeSeg (F_beta: 72.05%). Especially, our FoSp outperforms SegFormer by 7.71% (F_beta) for early smoke segmentation on SmokeSeg.
Object Preserving Siamese Network for Single Object Tracking on Point Clouds
Jan 28, 2023



Obviously, the object is the key factor of the 3D single object tracking (SOT) task. However, previous Siamese-based trackers overlook the negative effects brought by randomly dropped object points during backbone sampling, which hinder trackers to predict accurate bounding boxes (BBoxes). Exploring an approach that seeks to maximize the preservation of object points and their object-aware features is of particular significance. Motivated by this, we propose an Object Preserving Siamese Network (OPSNet), which can significantly maintain object integrity and boost tracking performance. Firstly, the object highlighting module enhances the object-aware features and extracts discriminative features from template and search area. Then, the object-preserved sampling selects object candidates to obtain object-preserved search area seeds and drop the background points that contribute less to tracking. Finally, the object localization network precisely locates 3D BBoxes based on the object-preserved search area seeds. Extensive experiments demonstrate our method outperforms the state-of-the-art performance (9.4% and 2.5% success gain on KITTI and Waymo Open Dataset respectively).
Dynamic Background Reconstruction via Transformer for Infrared Small Target Detection
Jan 11, 2023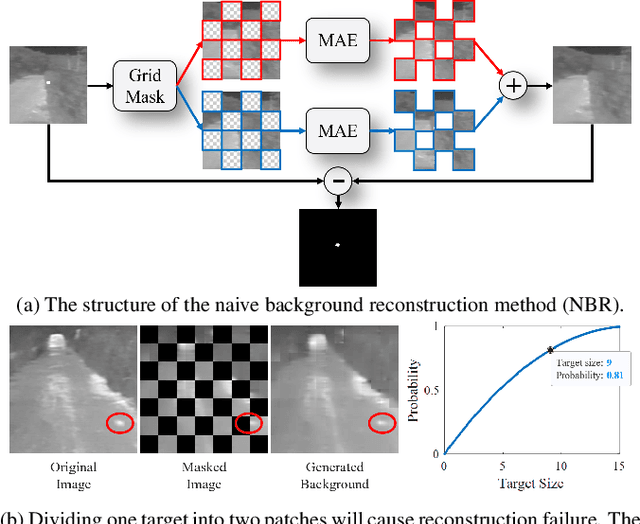
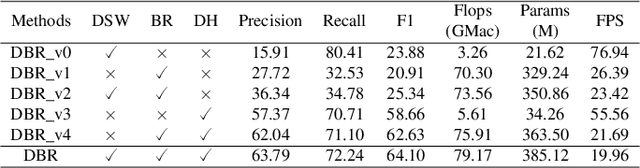
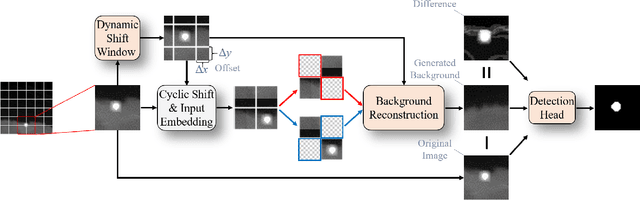
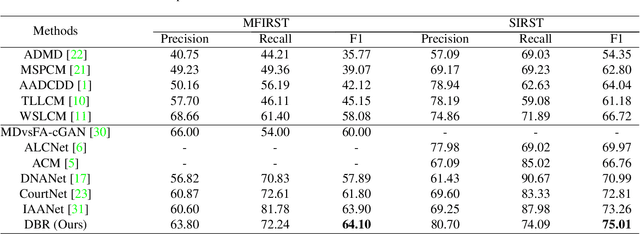
Infrared small target detection (ISTD) under complex backgrounds is a difficult problem, for the differences between targets and backgrounds are not easy to distinguish. Background reconstruction is one of the methods to deal with this problem. This paper proposes an ISTD method based on background reconstruction called Dynamic Background Reconstruction (DBR). DBR consists of three modules: a dynamic shift window module (DSW), a background reconstruction module (BR), and a detection head (DH). BR takes advantage of Vision Transformers in reconstructing missing patches and adopts a grid masking strategy with a masking ratio of 50\% to reconstruct clean backgrounds without targets. To avoid dividing one target into two neighboring patches, resulting in reconstructing failure, DSW is performed before input embedding. DSW calculates offsets, according to which infrared images dynamically shift. To reduce False Positive (FP) cases caused by regarding reconstruction errors as targets, DH utilizes a structure of densely connected Transformer to further improve the detection performance. Experimental results show that DBR achieves the best F1-score on the two ISTD datasets, MFIRST (64.10\%) and SIRST (75.01\%).
CourtNet for Infrared Small-Target Detection
Sep 28, 2022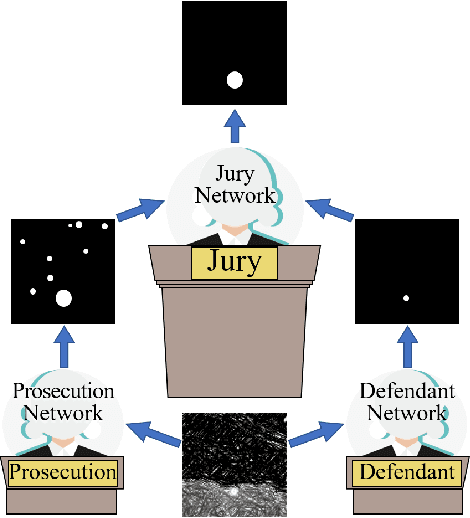
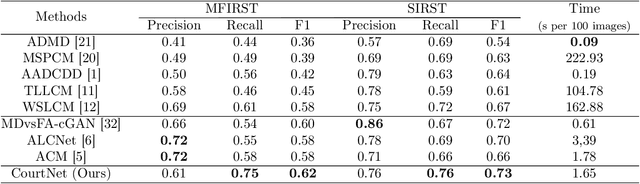
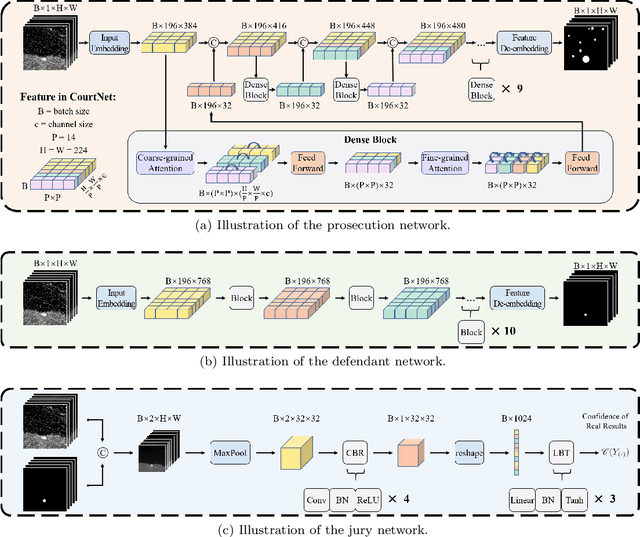

Infrared small-target detection (ISTD) is an important computer vision task. ISTD aims at separating small targets from complex background clutter. The infrared radiation decays over distances, making the targets highly dim and prone to confusion with the background clutter, which makes the detector challenging to balance the precision and recall rate. To deal with this difficulty, this paper proposes a neural-network-based ISTD method called CourtNet, which has three sub-networks: the prosecution network is designed for improving the recall rate; the defendant network is devoted to increasing the precision rate; the jury network weights their results to adaptively balance the precision and recall rate. Furthermore, the prosecution network utilizes a densely connected transformer structure, which can prevent small targets from disappearing in the network forward propagation. In addition, a fine-grained attention module is adopted to accurately locate the small targets. Experimental results show that CourtNet achieves the best F1-score on the two ISTD datasets, MFIRST (0.62) and SIRST (0.73).