 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLuminance Component Analysis for Exposure Correction
Nov 25, 2024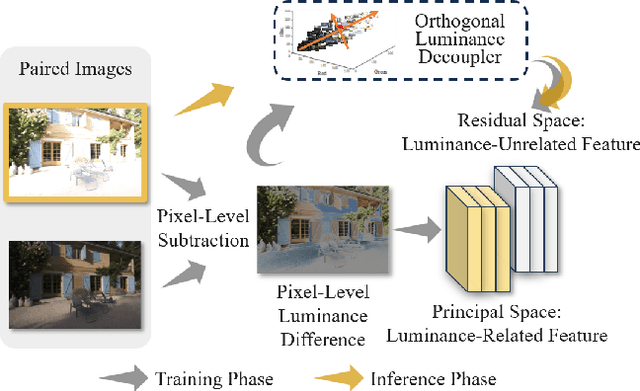

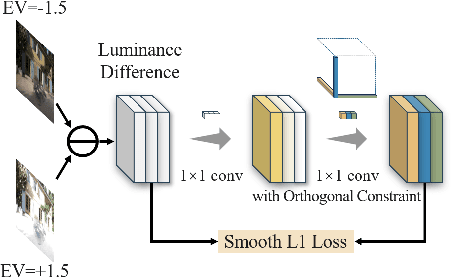

Exposure correction methods aim to adjust the luminance while maintaining other luminance-unrelated information. However, current exposure correction methods have difficulty in fully separating luminance-related and luminance-unrelated components, leading to distortions in color, loss of detail, and requiring extra restoration procedures. Inspired by principal component analysis (PCA), this paper proposes an exposure correction method called luminance component analysis (LCA). LCA applies the orthogonal constraint to a U-Net structure to decouple luminance-related and luminance-unrelated features. With decoupled luminance-related features, LCA adjusts only the luminance-related components while keeping the luminance-unrelated components unchanged. To optimize the orthogonal constraint problem, LCA employs a geometric optimization algorithm, which converts the constrained problem in Euclidean space to an unconstrained problem in orthogonal Stiefel manifolds. Extensive experiments show that LCA can decouple the luminance feature from the RGB color space. Moreover, LCA achieves the best PSNR (21.33) and SSIM (0.88) in the exposure correction dataset with 28.72 FPS.
Object Preserving Siamese Network for Single Object Tracking on Point Clouds
Jan 28, 2023



Obviously, the object is the key factor of the 3D single object tracking (SOT) task. However, previous Siamese-based trackers overlook the negative effects brought by randomly dropped object points during backbone sampling, which hinder trackers to predict accurate bounding boxes (BBoxes). Exploring an approach that seeks to maximize the preservation of object points and their object-aware features is of particular significance. Motivated by this, we propose an Object Preserving Siamese Network (OPSNet), which can significantly maintain object integrity and boost tracking performance. Firstly, the object highlighting module enhances the object-aware features and extracts discriminative features from template and search area. Then, the object-preserved sampling selects object candidates to obtain object-preserved search area seeds and drop the background points that contribute less to tracking. Finally, the object localization network precisely locates 3D BBoxes based on the object-preserved search area seeds. Extensive experiments demonstrate our method outperforms the state-of-the-art performance (9.4% and 2.5% success gain on KITTI and Waymo Open Dataset respectively).
Dynamic Background Reconstruction via Transformer for Infrared Small Target Detection
Jan 11, 2023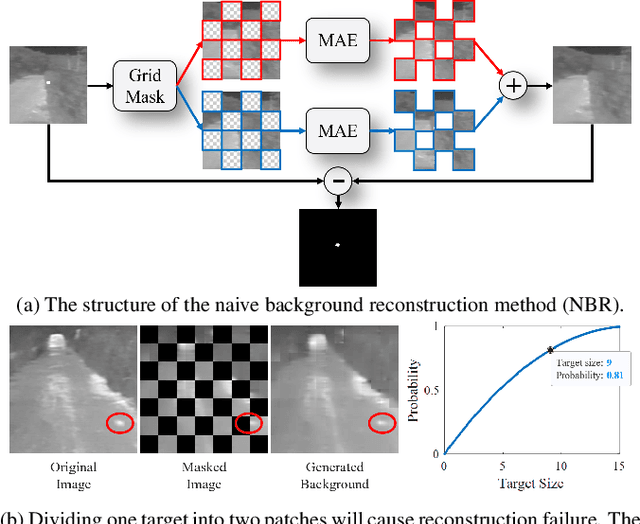
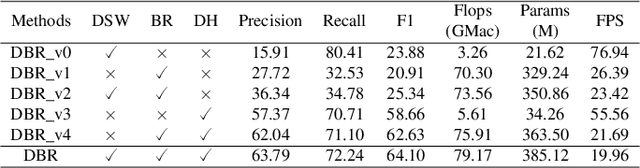
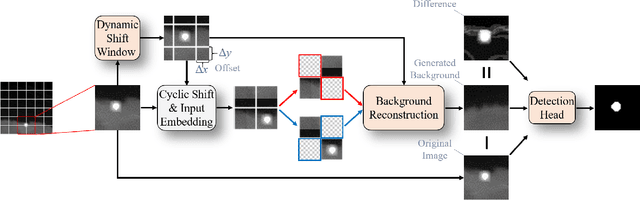
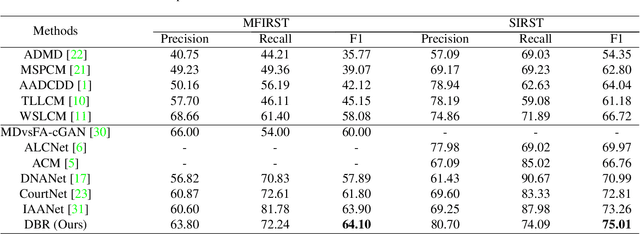
Infrared small target detection (ISTD) under complex backgrounds is a difficult problem, for the differences between targets and backgrounds are not easy to distinguish. Background reconstruction is one of the methods to deal with this problem. This paper proposes an ISTD method based on background reconstruction called Dynamic Background Reconstruction (DBR). DBR consists of three modules: a dynamic shift window module (DSW), a background reconstruction module (BR), and a detection head (DH). BR takes advantage of Vision Transformers in reconstructing missing patches and adopts a grid masking strategy with a masking ratio of 50\% to reconstruct clean backgrounds without targets. To avoid dividing one target into two neighboring patches, resulting in reconstructing failure, DSW is performed before input embedding. DSW calculates offsets, according to which infrared images dynamically shift. To reduce False Positive (FP) cases caused by regarding reconstruction errors as targets, DH utilizes a structure of densely connected Transformer to further improve the detection performance. Experimental results show that DBR achieves the best F1-score on the two ISTD datasets, MFIRST (64.10\%) and SIRST (75.01\%).
CourtNet for Infrared Small-Target Detection
Sep 28, 2022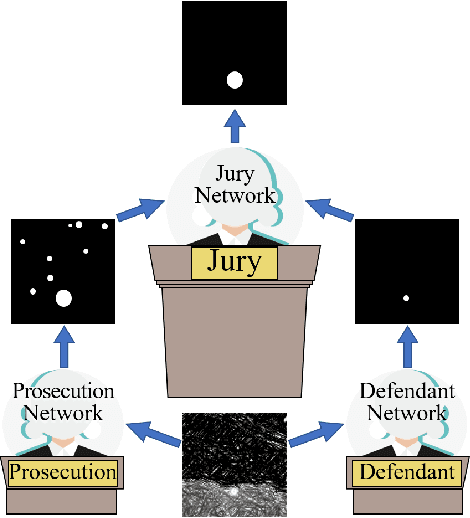
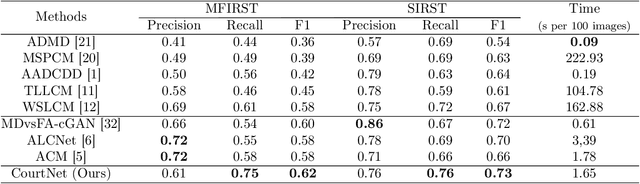
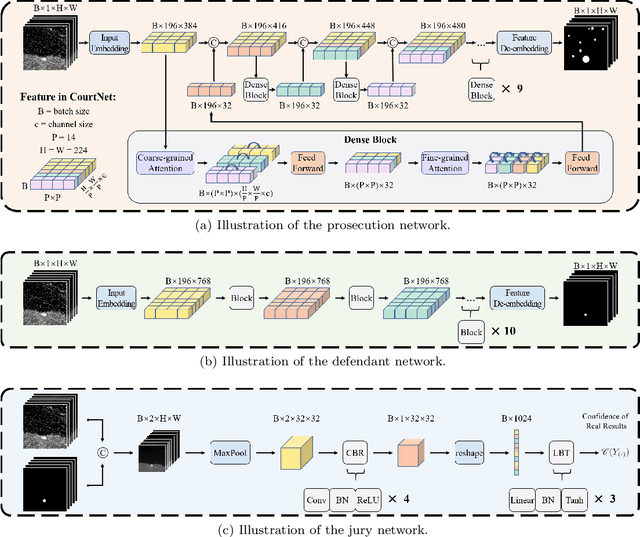

Infrared small-target detection (ISTD) is an important computer vision task. ISTD aims at separating small targets from complex background clutter. The infrared radiation decays over distances, making the targets highly dim and prone to confusion with the background clutter, which makes the detector challenging to balance the precision and recall rate. To deal with this difficulty, this paper proposes a neural-network-based ISTD method called CourtNet, which has three sub-networks: the prosecution network is designed for improving the recall rate; the defendant network is devoted to increasing the precision rate; the jury network weights their results to adaptively balance the precision and recall rate. Furthermore, the prosecution network utilizes a densely connected transformer structure, which can prevent small targets from disappearing in the network forward propagation. In addition, a fine-grained attention module is adopted to accurately locate the small targets. Experimental results show that CourtNet achieves the best F1-score on the two ISTD datasets, MFIRST (0.62) and SIRST (0.73).
DRPN: Making CNN Dynamically Handle Scale Variation
Dec 21, 2021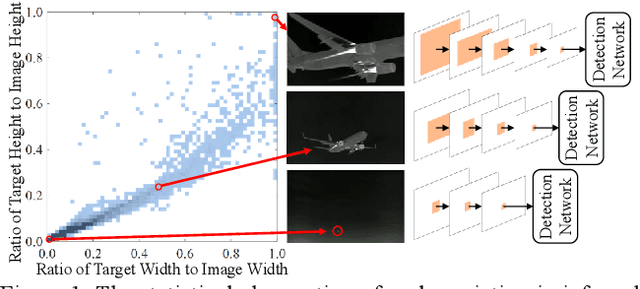

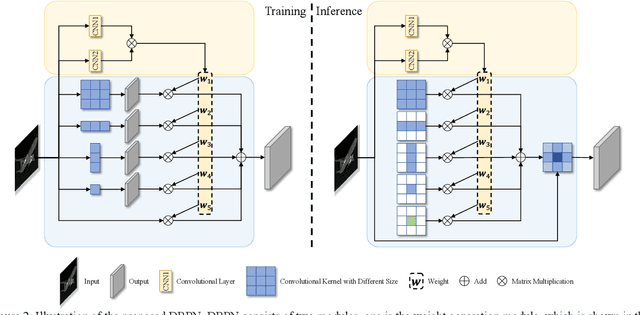
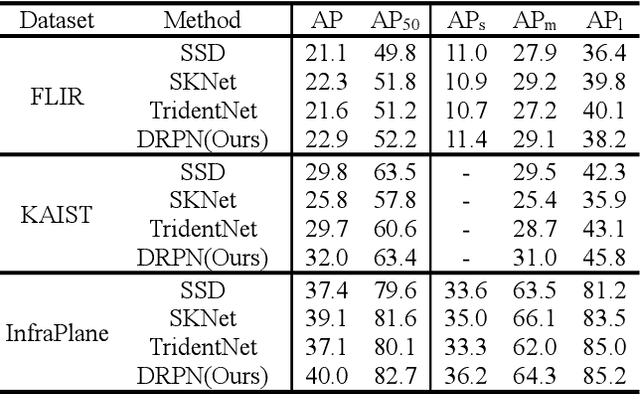
Based on our observations of infrared targets, serious scale variation along within sequence frames has high-frequently occurred. In this paper, we propose a dynamic re-parameterization network (DRPN) to deal with the scale variation and balance the detection precision between small targets and large targets in infrared datasets. DRPN adopts the multiple branches with different sizes of convolution kernels and the dynamic convolution strategy. Multiple branches with different sizes of convolution kernels have different sizes of receptive fields. Dynamic convolution strategy makes DRPN adaptively weight multiple branches. DRPN can dynamically adjust the receptive field according to the scale variation of the target. Besides, in order to maintain effective inference in the test phase, the multi-branch structure is further converted to a single-branch structure via the re-parameterization technique after training. Extensive experiments on FLIR, KAIST, and InfraPlane datasets demonstrate the effectiveness of our proposed DRPN. The experimental results show that detectors using the proposed DRPN as the basic structure rather than SKNet or TridentNet obtained the best performances.
Dynamic Fusion Network for RGBT Tracking
Sep 16, 2021
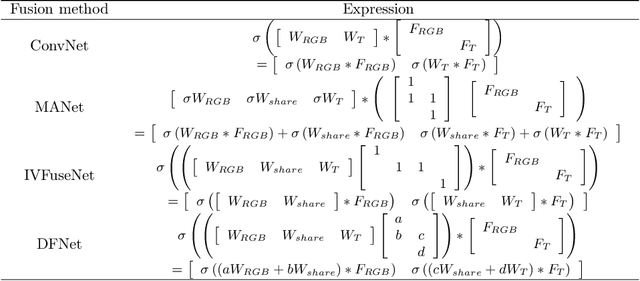


For both visible and infrared images have their own advantages and disadvantages, RGBT tracking has attracted more and more attention. The key points of RGBT tracking lie in feature extraction and feature fusion of visible and infrared images. Current RGBT tracking methods mostly pay attention to both individual features (features extracted from images of a single camera) and common features (features extracted and fused from an RGB camera and a thermal camera), while pay less attention to the different and dynamic contributions of individual features and common features for different sequences of registered image pairs. This paper proposes a novel RGBT tracking method, called Dynamic Fusion Network (DFNet), which adopts a two-stream structure, in which two non-shared convolution kernels are employed in each layer to extract individual features. Besides, DFNet has shared convolution kernels for each layer to extract common features. Non-shared convolution kernels and shared convolution kernels are adaptively weighted and summed according to different image pairs, so that DFNet can deal with different contributions for different sequences. DFNet has a fast speed, which is 28.658 FPS. The experimental results show that when DFNet only increases the Mult-Adds of 0.02% than the non-shared-convolution-kernel-based fusion method, Precision Rate (PR) and Success Rate (SR) reach 88.1% and 71.9% respectively.
Attention-based Context Aggregation Network for Monocular Depth Estimation
Jan 29, 2019
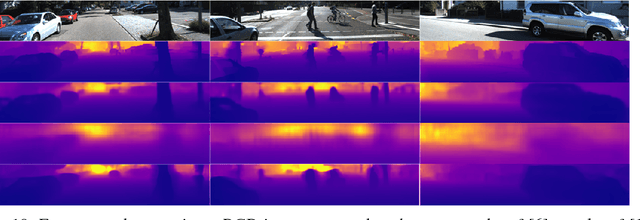


Depth estimation is a traditional computer vision task, which plays a crucial role in understanding 3D scene geometry. Recently, deep-convolutional-neural-networks based methods have achieved promising results in the monocular depth estimation field. Specifically, the framework that combines the multi-scale features extracted by the dilated convolution based block (atrous spatial pyramid pooling, ASPP) has gained the significant improvement in the dense labeling task. However, the discretized and predefined dilation rates cannot capture the continuous context information that differs in diverse scenes and easily introduce the grid artifacts in depth estimation. In this paper, we propose an attention-based context aggregation network (ACAN) to tackle these difficulties. Based on the self-attention model, ACAN adaptively learns the task-specific similarities between pixels to model the context information. First, we recast the monocular depth estimation as a dense labeling multi-class classification problem. Then we propose a soft ordinal inference to transform the predicted probabilities to continuous depth values, which can reduce the discretization error (about 1% decrease in RMSE). Second, the proposed ACAN aggregates both the image-level and pixel-level context information for depth estimation, where the former expresses the statistical characteristic of the whole image and the latter extracts the long-range spatial dependencies for each pixel. Third, for further reducing the inconsistency between the RGB image and depth map, we construct an attention loss to minimize their information entropy. We evaluate on public monocular depth-estimation benchmark datasets (including NYU Depth V2, KITTI). The experiments demonstrate the superiority of our proposed ACAN and achieve the competitive results with the state of the arts.