 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAmplitude-Phase-Frequency Block Modulation for OFDM-ISAC with SI-Free PAPR Reduction and Pilotless Sensing
Jun 18, 2026Orthogonal Frequency Division Multiplexing (OFDM)-based integrated sensing and communication systems demand a unified waveform that simultaneously supports reliable data transmission, low peak-to-average power ratio (PAPR), and accurate channel sensing. Existing approaches multiplex communication and sensing across separate time or frequency resources, or rely on dedicated pilots for channel estimation, limiting system flexibility and increasing overhead. This paper proposes an amplitude-phase-frequency block modulation (APFBM) scheme for OFDM that achieves waveform-level integration of communication and sensing without resource partitioning. Information symbols are represented on the Stokes sphere and mapped to energy-normalized Jones vectors through an unambiguous rule that establishes a deterministic phase reference per block. This mapping exposes a commonphase degree of freedom inherent in the signal structure. At the transmitter, a grouped phase optimization algorithm exploits this structural freedom to reduce the PAPR without side information (SI). At the receiver, the same deterministic phase structure enables a Viterbi-based maximum-likelihood (ML) sequence detection algorithm that jointly recovers the optimization phases and estimates the block-wise channel amplitude and phase. No dedicated sensing pilots are required, as the sensing observables are extracted directly from the communication waveform. Closed-form error-rate and sensing-accuracy expressions are derived. Numerical simulations and over-the-air measurements on a software-defined radio link confirm effective PAPR reduction, accurate channel sensing, reliable phase recovery, and stable channel state information reconstruction. The proposed scheme trades a moderate reduction in spectral efficiency for a unified waveform design that simultaneously delivers SI-free PAPR reduction and pilotless sensing.
Towards Semantic-based Agent Communication Networks: Vision, Technologies, and Challenges
Mar 25, 2026The International Telecommunication Union (ITU) identifies "Artificial Intelligence (AI) and Communication" as one of six key usage scenarios for 6G. Agentic AI, characterized by its ca-pabilities in multi-modal environmental sensing, complex task coordination, and continuous self-optimization, is anticipated to drive the evolution toward agent-based communication net-works. Semantic communication (SemCom), in turn, has emerged as a transformative paradigm that offers task-oriented efficiency, enhanced reliability in complex environments, and dynamic adaptation in resource allocation. However, comprehensive reviews that trace their technologi-cal evolution in the contexts of agent communications remain scarce. Addressing this gap, this paper systematically explores the role of semantics in agent communication networks. We first propose a novel architecture for semantic-based agent communication networks, structured into three layers, four entities, and four stages. Three wireless agent network layers define the logical structure and organization of entity interactions: the intention extraction and understanding layer, the semantic encoding and processing layer, and the distributed autonomy and collabora-tion layer. Across these layers, four AI agent entities, namely embodied agents, communication agents, network agents, and application agents, coexist and perform distinct tasks. Furthermore, four operational stages of semantic-enhanced agentic AI systems, namely perception, memory, reasoning, and action, form a cognitive cycle guiding agent behavior. Based on the proposed architecture, we provide a comprehensive review of the state-of-the-art on how semantics en-hance agent communication networks. Finally, we identify key challenges and present potential solutions to offer directional guidance for future research in this emerging field.
Hyperspectral Smoke Segmentation via Mixture of Prototypes
Feb 11, 2026Smoke segmentation is critical for wildfire management and industrial safety applications. Traditional visible-light-based methods face limitations due to insufficient spectral information, particularly struggling with cloud interference and semi-transparent smoke regions. To address these challenges, we introduce hyperspectral imaging for smoke segmentation and present the first hyperspectral smoke segmentation dataset (HSSDataset) with carefully annotated samples collected from over 18,000 frames across 20 real-world scenarios using a Many-to-One annotations protocol. However, different spectral bands exhibit varying discriminative capabilities across spatial regions, necessitating adaptive band weighting strategies. We decompose this into three technical challenges: spectral interaction contamination, limited spectral pattern modeling, and complex weighting router problems. We propose a mixture of prototypes (MoP) network with: (1) Band split for spectral isolation, (2) Prototype-based spectral representation for diverse patterns, and (3) Dual-level router for adaptive spatial-aware band weighting. We further construct a multispectral dataset (MSSDataset) with RGB-infrared images. Extensive experiments validate superior performance across both hyperspectral and multispectral modalities, establishing a new paradigm for spectral-based smoke segmentation.
Device Association and Resource Allocation for Hierarchical Split Federated Learning in Space-Air-Ground Integrated Network
Jan 20, 20266G facilitates deployment of Federated Learning (FL) in the Space-Air-Ground Integrated Network (SAGIN), yet FL confronts challenges such as resource constrained and unbalanced data distribution. To address these issues, this paper proposes a Hierarchical Split Federated Learning (HSFL) framework and derives its upper bound of loss function. To minimize the weighted sum of training loss and latency, we formulate a joint optimization problem that integrates device association, model split layer selection, and resource allocation. We decompose the original problem into several subproblems, where an iterative optimization algorithm for device association and resource allocation based on brute-force split point search is proposed. Simulation results demonstrate that the proposed algorithm can effectively balance training efficiency and model accuracy for FL in SAGIN.
Phishing Email Detection Using Large Language Models
Dec 14, 2025Email phishing is one of the most prevalent and globally consequential vectors of cyber intrusion. As systems increasingly deploy Large Language Models (LLMs) applications, these systems face evolving phishing email threats that exploit their fundamental architectures. Current LLMs require substantial hardening before deployment in email security systems, particularly against coordinated multi-vector attacks that exploit architectural vulnerabilities. This paper proposes LLMPEA, an LLM-based framework to detect phishing email attacks across multiple attack vectors, including prompt injection, text refinement, and multilingual attacks. We evaluate three frontier LLMs (e.g., GPT-4o, Claude Sonnet 4, and Grok-3) and comprehensive prompting design to assess their feasibility, robustness, and limitations against phishing email attacks. Our empirical analysis reveals that LLMs can detect the phishing email over 90% accuracy while we also highlight that LLM-based phishing email detection systems could be exploited by adversarial attack, prompt injection, and multilingual attacks. Our findings provide critical insights for LLM-based phishing detection in real-world settings where attackers exploit multiple vulnerabilities in combination.
Decoding Neighborhood Environments with Large Language Models
May 13, 2025Neighborhood environments include physical and environmental conditions such as housing quality, roads, and sidewalks, which significantly influence human health and well-being. Traditional methods for assessing these environments, including field surveys and geographic information systems (GIS), are resource-intensive and challenging to evaluate neighborhood environments at scale. Although machine learning offers potential for automated analysis, the laborious process of labeling training data and the lack of accessible models hinder scalability. This study explores the feasibility of large language models (LLMs) such as ChatGPT and Gemini as tools for decoding neighborhood environments (e.g., sidewalk and powerline) at scale. We train a robust YOLOv11-based model, which achieves an average accuracy of 99.13% in detecting six environmental indicators, including streetlight, sidewalk, powerline, apartment, single-lane road, and multilane road. We then evaluate four LLMs, including ChatGPT, Gemini, Claude, and Grok, to assess their feasibility, robustness, and limitations in identifying these indicators, with a focus on the impact of prompting strategies and fine-tuning. We apply majority voting with the top three LLMs to achieve over 88% accuracy, which demonstrates LLMs could be a useful tool to decode the neighborhood environment without any training effort.
Luminance Component Analysis for Exposure Correction
Nov 25, 2024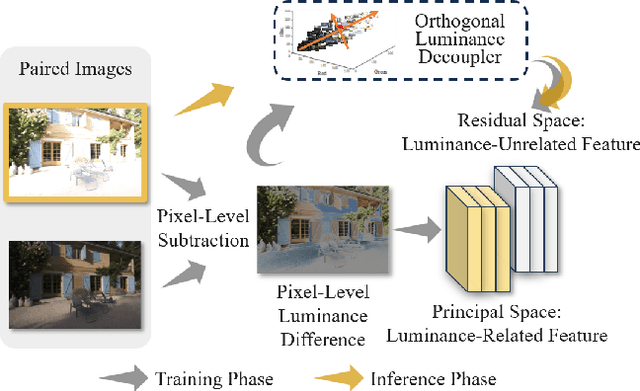

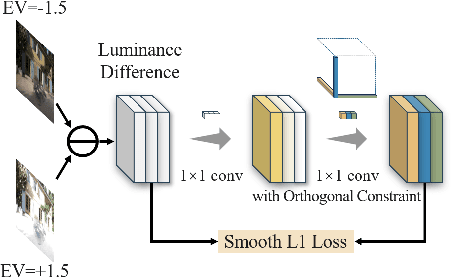

Exposure correction methods aim to adjust the luminance while maintaining other luminance-unrelated information. However, current exposure correction methods have difficulty in fully separating luminance-related and luminance-unrelated components, leading to distortions in color, loss of detail, and requiring extra restoration procedures. Inspired by principal component analysis (PCA), this paper proposes an exposure correction method called luminance component analysis (LCA). LCA applies the orthogonal constraint to a U-Net structure to decouple luminance-related and luminance-unrelated features. With decoupled luminance-related features, LCA adjusts only the luminance-related components while keeping the luminance-unrelated components unchanged. To optimize the orthogonal constraint problem, LCA employs a geometric optimization algorithm, which converts the constrained problem in Euclidean space to an unconstrained problem in orthogonal Stiefel manifolds. Extensive experiments show that LCA can decouple the luminance feature from the RGB color space. Moreover, LCA achieves the best PSNR (21.33) and SSIM (0.88) in the exposure correction dataset with 28.72 FPS.
CapHDR2IR: Caption-Driven Transfer from Visible Light to Infrared Domain
Nov 25, 2024
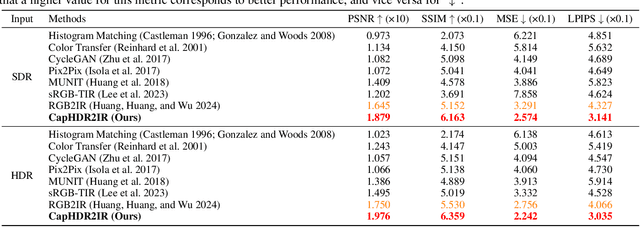

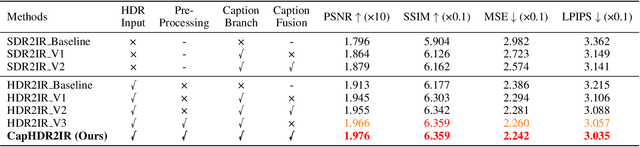
Infrared (IR) imaging offers advantages in several fields due to its unique ability of capturing content in extreme light conditions. However, the demanding hardware requirements of high-resolution IR sensors limit its widespread application. As an alternative, visible light can be used to synthesize IR images but this causes a loss of fidelity in image details and introduces inconsistencies due to lack of contextual awareness of the scene. This stems from a combination of using visible light with a standard dynamic range, especially under extreme lighting, and a lack of contextual awareness can result in pseudo-thermal-crossover artifacts. This occurs when multiple objects with similar temperatures appear indistinguishable in the training data, further exacerbating the loss of fidelity. To solve this challenge, this paper proposes CapHDR2IR, a novel framework incorporating vision-language models using high dynamic range (HDR) images as inputs to generate IR images. HDR images capture a wider range of luminance variations, ensuring reliable IR image generation in different light conditions. Additionally, a dense caption branch integrates semantic understanding, resulting in more meaningful and discernible IR outputs. Extensive experiments on the HDRT dataset show that the proposed CapHDR2IR achieves state-of-the-art performance compared with existing general domain transfer methods and those tailored for visible-to-infrared image translation.
Fair Computation Offloading for RSMA-Assisted Mobile Edge Computing Networks
Jun 16, 2024



Rate splitting multiple access (RSMA) provides a flexible transmission framework that can be applied in mobile edge computing (MEC) systems. However, the research work on RSMA-assisted MEC systems is still at the infancy and many design issues remain unsolved, such as the MEC server and channel allocation problem in general multi-server and multi-channel scenarios as well as the user fairness issues. In this regard, we study an RSMA-assisted MEC system with multiple MEC servers, channels and devices, and consider the fairness among devices. A max-min fairness computation offloading problem to maximize the minimum computation offloading rate is investigated. Since the problem is difficult to solve optimally, we develop an efficient algorithm to obtain a suboptimal solution. Particularly, the time allocation and the computing frequency allocation are derived as closed-form functions of the transmit power allocation and the successive interference cancellation (SIC) decoding order, while the SIC decoding order is obtained heuristically, and the bisection search and the successive convex approximation methods are employed to optimize the transmit power allocation. For the MEC server and channel allocation problem, we transform it into a hypergraph matching problem and solve it by matching theory. Simulation results demonstrate that the proposed RSMA-assisted MEC system outperforms current MEC systems under various system setups.
HDRT: Infrared Capture for HDR Imaging
Jun 08, 2024
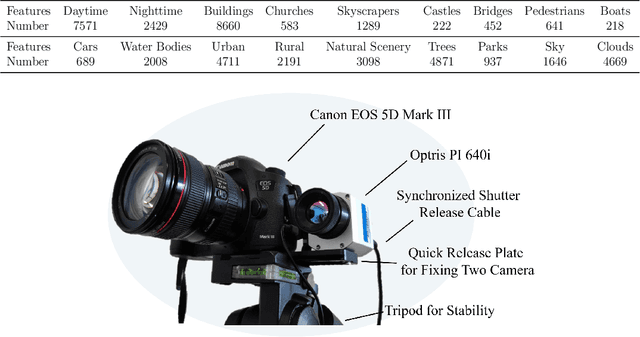
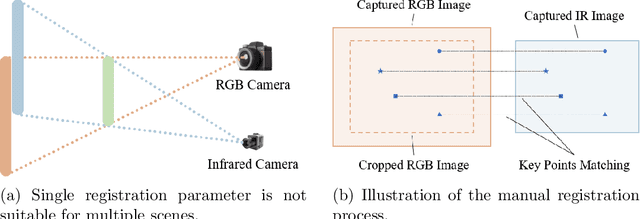
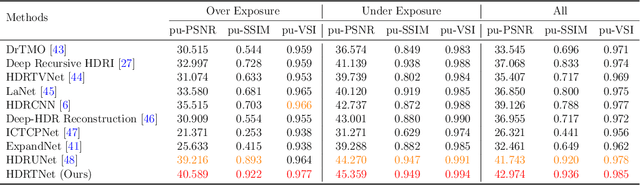
Capturing real world lighting is a long standing challenge in imaging and most practical methods acquire High Dynamic Range (HDR) images by either fusing multiple exposures, or boosting the dynamic range of Standard Dynamic Range (SDR) images. Multiple exposure capture is problematic as it requires longer capture times which can often lead to ghosting problems. The main alternative, inverse tone mapping is an ill-defined problem that is especially challenging as single captured exposures usually contain clipped and quantized values, and are therefore missing substantial amounts of content. To alleviate this, we propose a new approach, High Dynamic Range Thermal (HDRT), for HDR acquisition using a separate, commonly available, thermal infrared (IR) sensor. We propose a novel deep neural method (HDRTNet) which combines IR and SDR content to generate HDR images. HDRTNet learns to exploit IR features linked to the RGB image and the IR-specific parameters are subsequently used in a dual branch method that fuses features at shallow layers. This produces an HDR image that is significantly superior to that generated using naive fusion approaches. To validate our method, we have created the first HDR and thermal dataset, and performed extensive experiments comparing HDRTNet with the state-of-the-art. We show substantial quantitative and qualitative quality improvements on both over- and under-exposed images, showing that our approach is robust to capturing in multiple different lighting conditions.