 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGoverning AI Forgetting: Auditing for Machine Unlearning Compliance
Feb 16, 2026Despite legal mandates for the right to be forgotten, AI operators routinely fail to comply with data deletion requests. While machine unlearning (MU) provides a technical solution to remove personal data's influence from trained models, ensuring compliance remains challenging due to the fundamental gap between MU's technical feasibility and regulatory implementation. In this paper, we introduce the first economic framework for auditing MU compliance, by integrating certified unlearning theory with regulatory enforcement. We first characterize MU's inherent verification uncertainty using a hypothesis-testing interpretation of certified unlearning to derive the auditor's detection capability, and then propose a game-theoretic model to capture the strategic interactions between the auditor and the operator. A key technical challenge arises from MU-specific nonlinearities inherent in the model utility and the detection probability, which create complex strategic couplings that traditional auditing frameworks do not address and that also preclude closed-form solutions. We address this by transforming the complex bivariate nonlinear fixed-point problem into a tractable univariate auxiliary problem, enabling us to decouple the system and establish the equilibrium existence, uniqueness, and structural properties without relying on explicit solutions. Counterintuitively, our analysis reveals that the auditor can optimally reduce the inspection intensity as deletion requests increase, since the operator's weakened unlearning makes non-compliance easier to detect. This is consistent with recent auditing reductions in China despite growing deletion requests. Moreover, we prove that although undisclosed auditing offers informational advantages for the auditor, it paradoxically reduces the regulatory cost-effectiveness relative to disclosed auditing.
Provable In-Context Learning of Nonlinear Regression with Transformers
Jul 28, 2025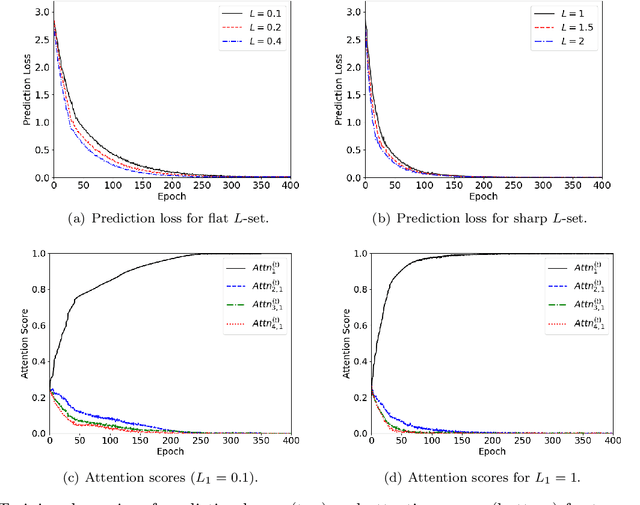
The transformer architecture, which processes sequences of input tokens to produce outputs for query tokens, has revolutionized numerous areas of machine learning. A defining feature of transformers is their ability to perform previously unseen tasks using task-specific prompts without updating parameters, a phenomenon known as in-context learning (ICL). Recent research has actively explored the training dynamics behind ICL, with much of the focus on relatively simple tasks such as linear regression and binary classification. To advance the theoretical understanding of ICL, this paper investigates more complex nonlinear regression tasks, aiming to uncover how transformers acquire in-context learning capabilities in these settings. We analyze the stage-wise dynamics of attention during training: attention scores between a query token and its target features grow rapidly in the early phase, then gradually converge to one, while attention to irrelevant features decays more slowly and exhibits oscillatory behavior. Our analysis introduces new proof techniques that explicitly characterize how the nature of general non-degenerate L-Lipschitz task functions affects attention weights. Specifically, we identify that the Lipschitz constant L of nonlinear function classes as a key factor governing the convergence dynamics of transformers in ICL. Leveraging these insights, for two distinct regimes depending on whether L is below or above a threshold, we derive different time bounds to guarantee near-zero prediction error. Notably, despite the convergence time depending on the underlying task functions, we prove that query tokens consistently attend to prompt tokens with highly relevant features at convergence, demonstrating the ICL capability of transformers for unseen functions.
Competitive Multi-armed Bandit Games for Resource Sharing
Mar 26, 2025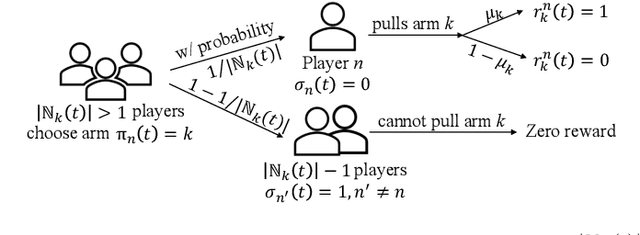
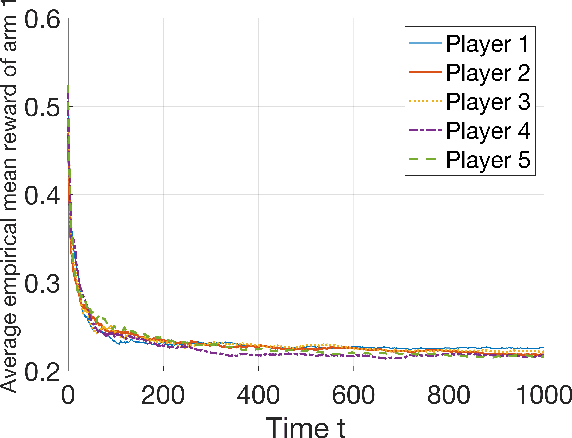
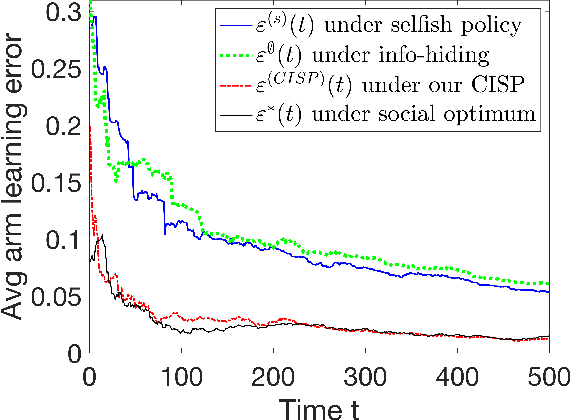
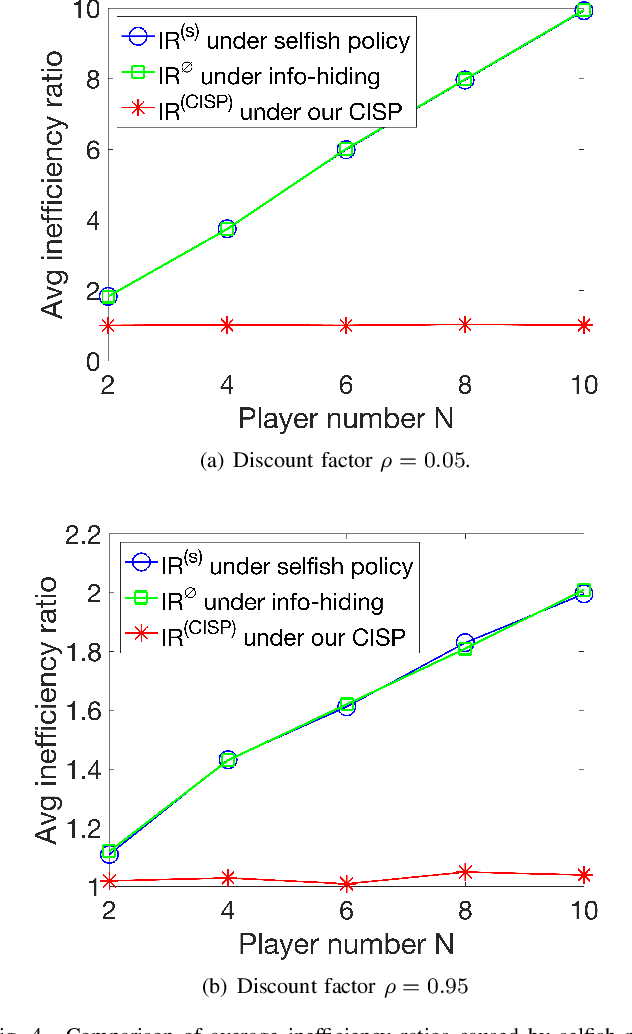
In modern resource-sharing systems, multiple agents access limited resources with unknown stochastic conditions to perform tasks. When multiple agents access the same resource (arm) simultaneously, they compete for successful usage, leading to contention and reduced rewards. This motivates our study of competitive multi-armed bandit (CMAB) games. In this paper, we study a new N-player K-arm competitive MAB game, where non-myopic players (agents) compete with each other to form diverse private estimations of unknown arms over time. Their possible collisions on same arms and time-varying nature of arm rewards make the policy analysis more involved than existing studies for myopic players. We explicitly analyze the threshold-based structures of social optimum and existing selfish policy, showing that the latter causes prolonged convergence time $\Omega(\frac{K}{\eta^2}\ln({\frac{KN}{\delta}}))$, while socially optimal policy with coordinated communication reduces it to $\mathcal{O}(\frac{K}{N\eta^2}\ln{(\frac{K}{\delta})})$. Based on the comparison, we prove that the competition among selfish players for the best arm can result in an infinite price of anarchy (PoA), indicating an arbitrarily large efficiency loss compared to social optimum. We further prove that no informational (non-monetary) mechanism (including Bayesian persuasion) can reduce the infinite PoA, as the strategic misreporting by non-myopic players undermines such approaches. To address this, we propose a Combined Informational and Side-Payment (CISP) mechanism, which provides socially optimal arm recommendations with proper informational and monetary incentives to players according to their time-varying private beliefs. Our CISP mechanism keeps ex-post budget balanced for social planner and ensures truthful reporting from players, achieving the minimum PoA=1 and same convergence time as social optimum.
Truthful mechanisms for linear bandit games with private contexts
Jan 07, 2025The contextual bandit problem, where agents arrive sequentially with personal contexts and the system adapts its arm allocation decisions accordingly, has recently garnered increasing attention for enabling more personalized outcomes. However, in many healthcare and recommendation applications, agents have private profiles and may misreport their contexts to gain from the system. For example, in adaptive clinical trials, where hospitals sequentially recruit volunteers to test multiple new treatments and adjust plans based on volunteers' reported profiles such as symptoms and interim data, participants may misreport severe side effects like allergy and nausea to avoid perceived suboptimal treatments. We are the first to study this issue of private context misreporting in a stochastic contextual bandit game between the system and non-repeated agents. We show that traditional low-regret algorithms, such as UCB family algorithms and Thompson sampling, fail to ensure truthful reporting and can result in linear regret in the worst case, while traditional truthful algorithms like explore-then-commit (ETC) and $\epsilon$-greedy algorithm incur sublinear but high regret. We propose a mechanism that uses a linear program to ensure truthfulness while minimizing deviation from Thompson sampling, yielding an $O(\ln T)$ frequentist regret. Our numerical experiments further demonstrate strong performance in multiple contexts and across other distribution families.
To Analyze and Regulate Human-in-the-loop Learning for Congestion Games
Jan 06, 2025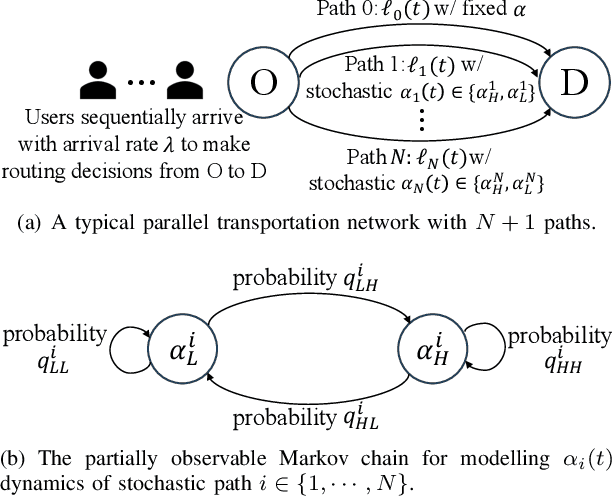
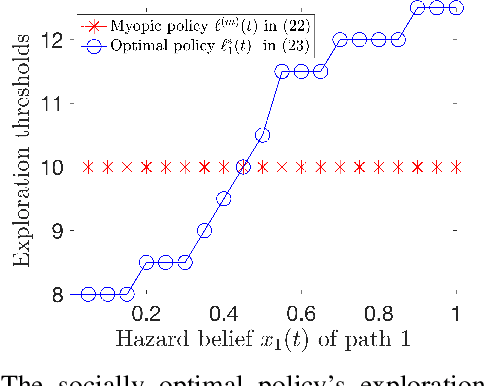
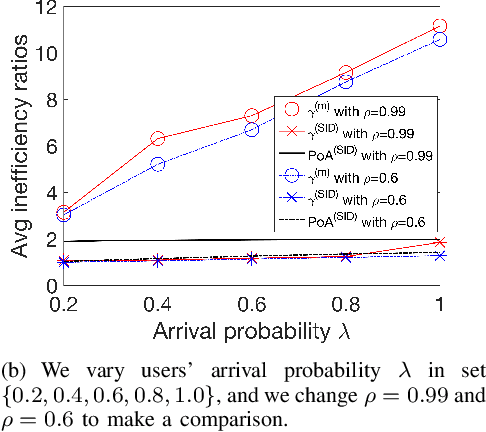

In congestion games, selfish users behave myopically to crowd to the shortest paths, and the social planner designs mechanisms to regulate such selfish routing through information or payment incentives. However, such mechanism design requires the knowledge of time-varying traffic conditions and it is the users themselves to learn and report past road experiences to the social planner (e.g., Waze or Google Maps). When congestion games meet mobile crowdsourcing, it is critical to incentivize selfish users to explore non-shortest paths in the best exploitation-exploration trade-off. First, we consider a simple but fundamental parallel routing network with one deterministic path and multiple stochastic paths for users with an average arrival probability $\lambda$. We prove that the current myopic routing policy (widely used in Waze and Google Maps) misses both exploration (when strong hazard belief) and exploitation (when weak hazard belief) as compared to the social optimum. Due to the myopic policy's under-exploration, we prove that the caused price of anarchy (PoA) is larger than \(\frac{1}{1-\rho^{\frac{1}{\lambda}}}\), which can be arbitrarily large as discount factor \(\rho\rightarrow1\). To mitigate such huge efficiency loss, we propose a novel selective information disclosure (SID) mechanism: we only reveal the latest traffic information to users when they intend to over-explore stochastic paths upon arrival, while hiding such information when they want to under-explore. We prove that our mechanism successfully reduces PoA to be less than~\(2\). Besides the parallel routing network, we further extend our mechanism and PoA results to any linear path graphs with multiple intermediate nodes.
Online Learning from Strategic Human Feedback in LLM Fine-Tuning
Dec 24, 2024Reinforcement learning from human feedback (RLHF) has become an essential step in fine-tuning large language models (LLMs) to align them with human preferences. However, human labelers are selfish and have diverse preferences. They may strategically misreport their online feedback to influence the system's aggregation towards their own preferences. Current practice simply averages labelers' feedback per time and fails to identify the most accurate human labeler, leading to linear regret $\mathcal{O}(T)$ for $T$ time slots. To our best knowledge, we are the first to study online learning mechanisms against strategic human labelers in the LLM fine-tuning process. We formulate a new dynamic Bayesian game and dynamically adjust human labelers' weights in the preference aggregation, ensuring their truthful feedback and sublinear regret $\mathcal{O}(T^{1/2})$. Simulation results demonstrate our mechanism's great advantages over the existing benchmark schemes.
Algorithm Design for Continual Learning in IoT Networks
Dec 24, 2024

Continual learning (CL) is a new online learning technique over sequentially generated streaming data from different tasks, aiming to maintain a small forgetting loss on previously-learned tasks. Existing work focuses on reducing the forgetting loss under a given task sequence. However, if similar tasks continuously appear to the end time, the forgetting loss is still huge on prior distinct tasks. In practical IoT networks, an autonomous vehicle to sample data and learn different tasks can route and alter the order of task pattern at increased travelling cost. To our best knowledge, we are the first to study how to opportunistically route the testing object and alter the task sequence in CL. We formulate a new optimization problem and prove it NP-hard. We propose a polynomial-time algorithm to achieve approximation ratios of $\frac{3}{2}$ for underparameterized case and $\frac{3}{2} + r^{1-T}$ for overparameterized case, respectively, where $r:=1-\frac{n}{m}$ is a parameter of feature number $m$ and sample number $n$ and $T$ is the task number. Simulation results verify our algorithm's close-to-optimum performance.
Theory of Mixture-of-Experts for Mobile Edge Computing
Dec 20, 2024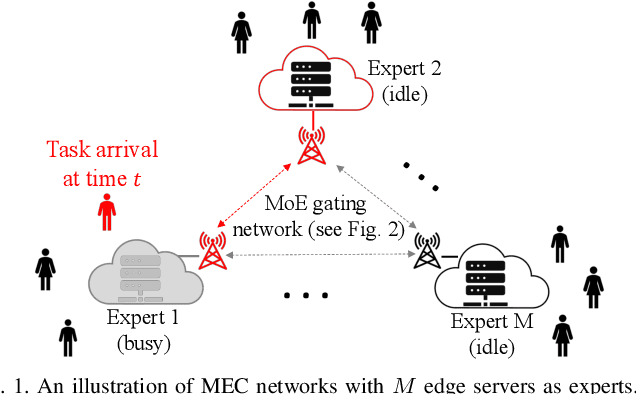
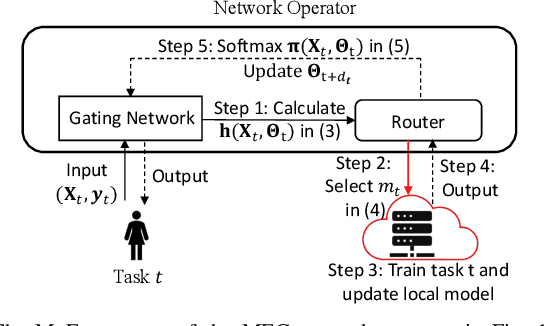
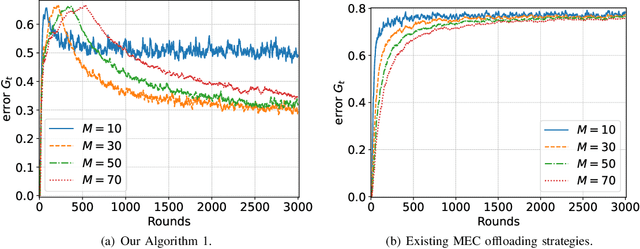
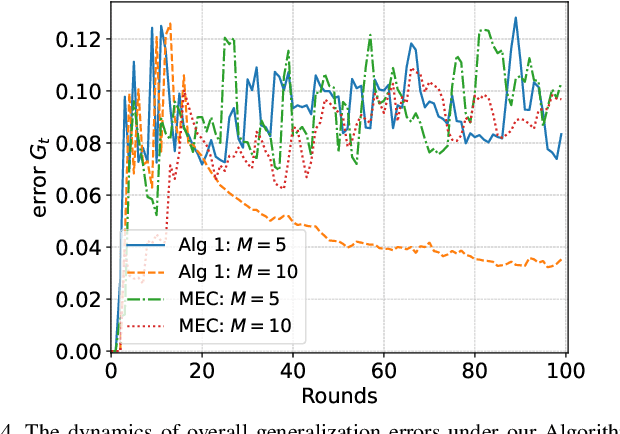
In mobile edge computing (MEC) networks, mobile users generate diverse machine learning tasks dynamically over time. These tasks are typically offloaded to the nearest available edge server, by considering communication and computational efficiency. However, its operation does not ensure that each server specializes in a specific type of tasks and leads to severe overfitting or catastrophic forgetting of previous tasks. To improve the continual learning (CL) performance of online tasks, we are the first to introduce mixture-of-experts (MoE) theory in MEC networks and save MEC operation from the increasing generalization error over time. Our MoE theory treats each MEC server as an expert and dynamically adapts to changes in server availability by considering data transfer and computation time. Unlike existing MoE models designed for offline tasks, ours is tailored for handling continuous streams of tasks in the MEC environment. We introduce an adaptive gating network in MEC to adaptively identify and route newly arrived tasks of unknown data distributions to available experts, enabling each expert to specialize in a specific type of tasks upon convergence. We derived the minimum number of experts required to match each task with a specialized, available expert. Our MoE approach consistently reduces the overall generalization error over time, unlike the traditional MEC approach. Interestingly, when the number of experts is sufficient to ensure convergence, adding more experts delays the convergence time and worsens the generalization error. Finally, we perform extensive experiments on real datasets in deep neural networks (DNNs) to verify our theoretical results.
ROSS:RObust decentralized Stochastic learning based on Shapley values
Nov 01, 2024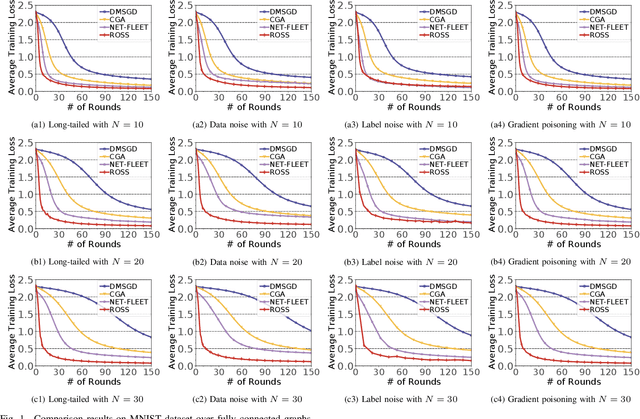
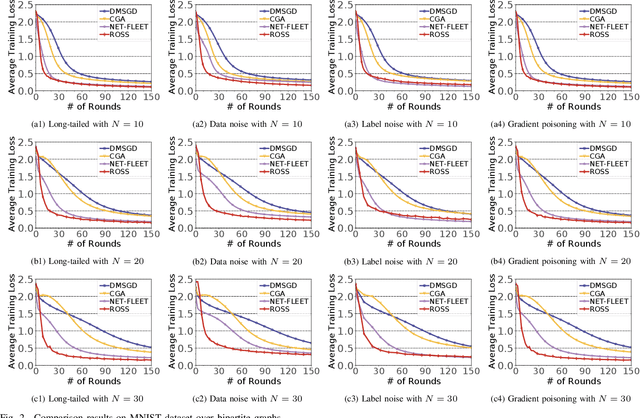
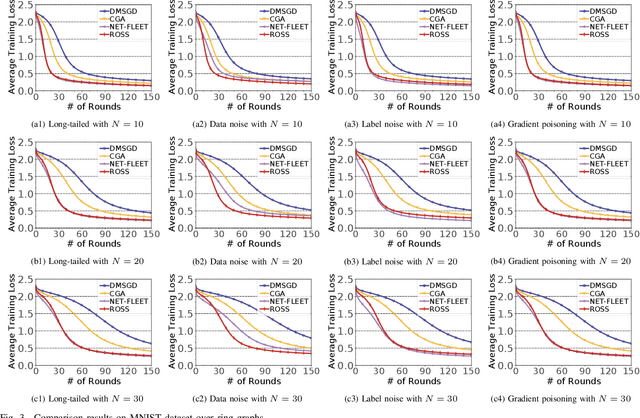
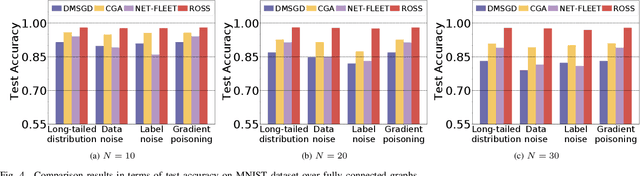
In the paradigm of decentralized learning, a group of agents collaborate to learn a global model using a distributed dataset without a central server; nevertheless, it is severely challenged by the heterogeneity of the data distribution across the agents. For example, the data may be distributed non-independently and identically, and even be noised or poisoned. To address these data challenges, we propose ROSS, a novel robust decentralized stochastic learning algorithm based on Shapley values, in this paper. Specifically, in each round, each agent aggregates the cross-gradient information from its neighbors, i.e., the derivatives of its local model with respect to the datasets of its neighbors, to update its local model in a momentum like manner, while we innovate in weighting the derivatives according to their contributions measured by Shapley values. We perform solid theoretical analysis to reveal the linear convergence speedup of our ROSS algorithm. We also verify the efficacy of our algorithm through extensive experiments on public datasets. Our results demonstrate that, in face of the above variety of data challenges, our ROSS algorithm have oblivious advantages over existing state-of-the-art proposals in terms of both convergence and prediction accuracy.
Theory on Mixture-of-Experts in Continual Learning
Jun 24, 2024



Continual learning (CL) has garnered significant attention because of its ability to adapt to new tasks that arrive over time. Catastrophic forgetting (of old tasks) has been identified as a major issue in CL, as the model adapts to new tasks. The Mixture-of-Experts (MoE) model has recently been shown to effectively mitigate catastrophic forgetting in CL, by employing a gating network to sparsify and distribute diverse tasks among multiple experts. However, there is a lack of theoretical analysis of MoE and its impact on the learning performance in CL. This paper provides the first theoretical results to characterize the impact of MoE in CL via the lens of overparameterized linear regression tasks. We establish the benefit of MoE over a single expert by proving that the MoE model can diversify its experts to specialize in different tasks, while its router learns to select the right expert for each task and balance the loads across all experts. Our study further suggests an intriguing fact that the MoE in CL needs to terminate the update of the gating network after sufficient training rounds to attain system convergence, which is not needed in the existing MoE studies that do not consider the continual task arrival. Furthermore, we provide explicit expressions for the expected forgetting and overall generalization error to characterize the benefit of MoE in the learning performance in CL. Interestingly, adding more experts requires additional rounds before convergence, which may not enhance the learning performance. Finally, we conduct experiments on both synthetic and real datasets to extend these insights from linear models to deep neural networks (DNNs), which also shed light on the practical algorithm design for MoE in CL.