 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePDSL: Privacy-Preserved Decentralized Stochastic Learning with Heterogeneous Data Distribution
Mar 31, 2025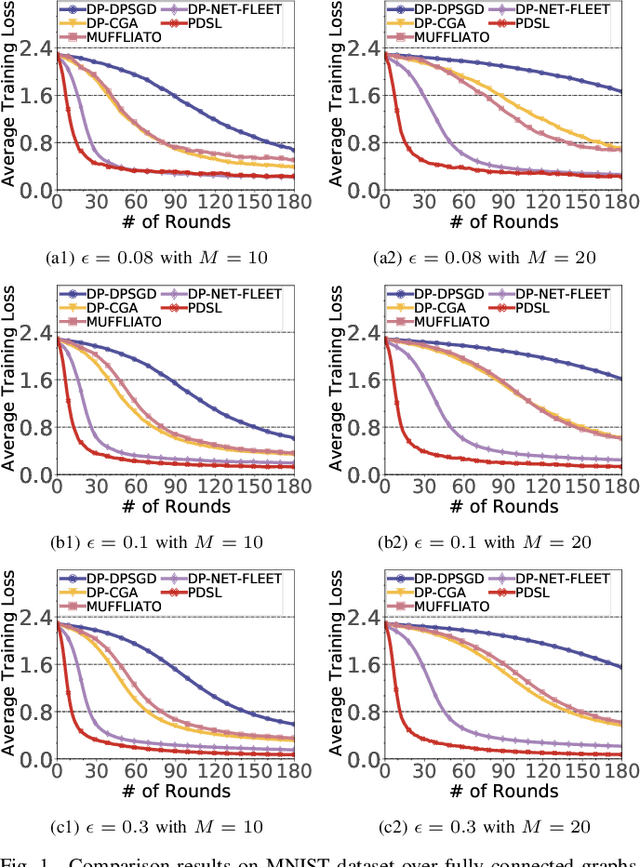
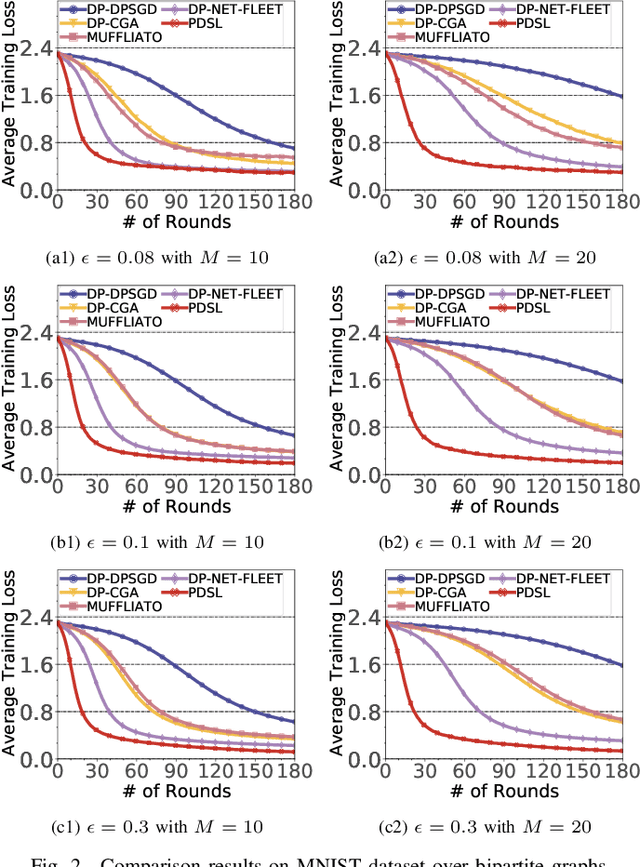
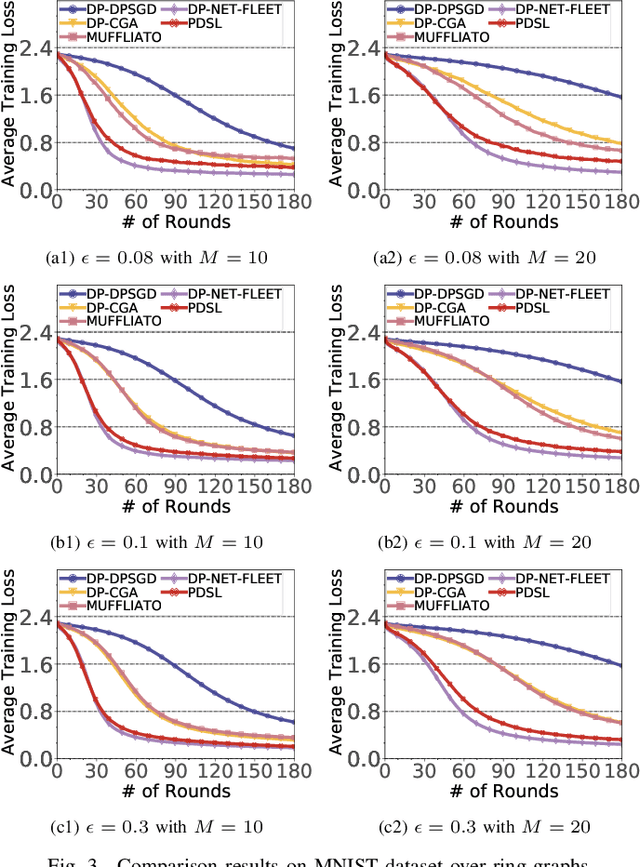
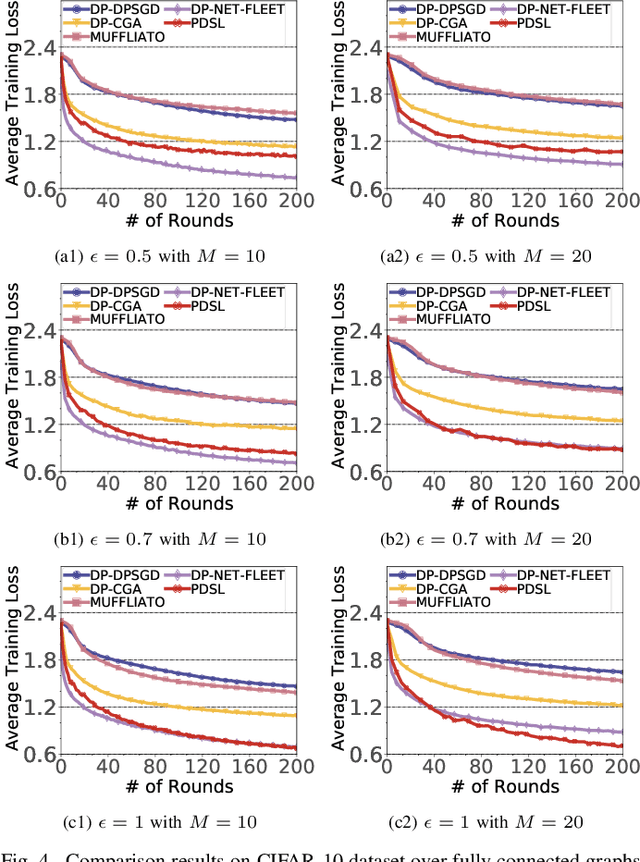
In the paradigm of decentralized learning, a group of agents collaborates to learn a global model using distributed datasets without a central server. However, due to the heterogeneity of the local data across the different agents, learning a robust global model is rather challenging. Moreover, the collaboration of the agents relies on their gradient information exchange, which poses a risk of privacy leakage. In this paper, to address these issues, we propose PDSL, a novel privacy-preserved decentralized stochastic learning algorithm with heterogeneous data distribution. On one hand, we innovate in utilizing the notion of Shapley values such that each agent can precisely measure the contributions of its heterogeneous neighbors to the global learning goal; on the other hand, we leverage the notion of differential privacy to prevent each agent from suffering privacy leakage when it contributes gradient information to its neighbors. We conduct both solid theoretical analysis and extensive experiments to demonstrate the efficacy of our PDSL algorithm in terms of privacy preservation and convergence.
ROSS:RObust decentralized Stochastic learning based on Shapley values
Nov 01, 2024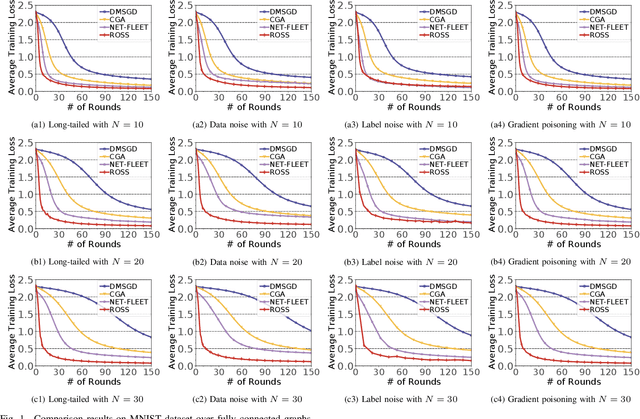
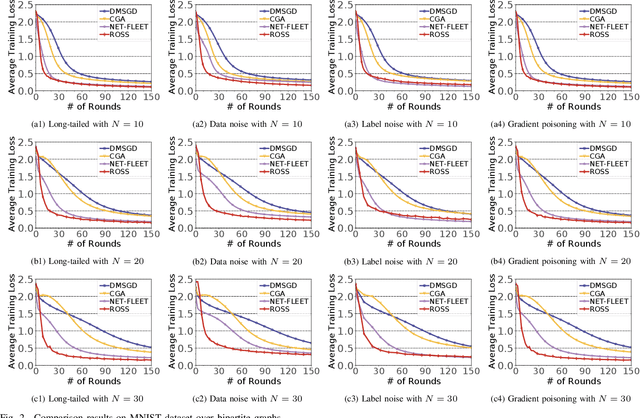
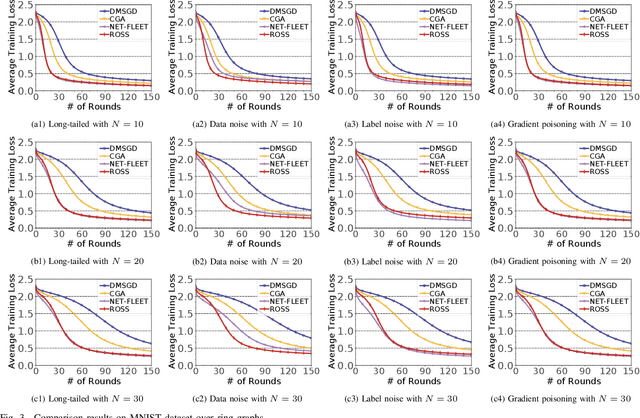
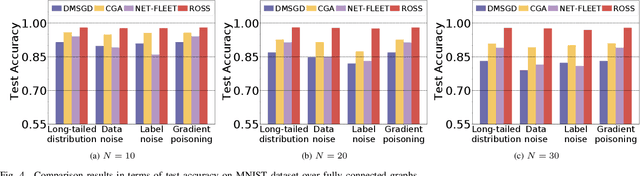
In the paradigm of decentralized learning, a group of agents collaborate to learn a global model using a distributed dataset without a central server; nevertheless, it is severely challenged by the heterogeneity of the data distribution across the agents. For example, the data may be distributed non-independently and identically, and even be noised or poisoned. To address these data challenges, we propose ROSS, a novel robust decentralized stochastic learning algorithm based on Shapley values, in this paper. Specifically, in each round, each agent aggregates the cross-gradient information from its neighbors, i.e., the derivatives of its local model with respect to the datasets of its neighbors, to update its local model in a momentum like manner, while we innovate in weighting the derivatives according to their contributions measured by Shapley values. We perform solid theoretical analysis to reveal the linear convergence speedup of our ROSS algorithm. We also verify the efficacy of our algorithm through extensive experiments on public datasets. Our results demonstrate that, in face of the above variety of data challenges, our ROSS algorithm have oblivious advantages over existing state-of-the-art proposals in terms of both convergence and prediction accuracy.