 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFastStair: Learning to Run Up Stairs with Humanoid Robots
Jan 15, 2026Running up stairs is effortless for humans but remains extremely challenging for humanoid robots due to the simultaneous requirements of high agility and strict stability. Model-free reinforcement learning (RL) can generate dynamic locomotion, yet implicit stability rewards and heavy reliance on task-specific reward shaping tend to result in unsafe behaviors, especially on stairs; conversely, model-based foothold planners encode contact feasibility and stability structure, but enforcing their hard constraints often induces conservative motion that limits speed. We present FastStair, a planner-guided, multi-stage learning framework that reconciles these complementary strengths to achieve fast and stable stair ascent. FastStair integrates a parallel model-based foothold planner into the RL training loop to bias exploration toward dynamically feasible contacts and to pretrain a safety-focused base policy. To mitigate planner-induced conservatism and the discrepancy between low- and high-speed action distributions, the base policy was fine-tuned into speed-specialized experts and then integrated via Low-Rank Adaptation (LoRA) to enable smooth operation across the full commanded-speed range. We deploy the resulting controller on the Oli humanoid robot, achieving stable stair ascent at commanded speeds up to 1.65 m/s and traversing a 33-step spiral staircase (17 cm rise per step) in 12 s, demonstrating robust high-speed performance on long staircases. Notably, the proposed approach served as the champion solution in the Canton Tower Robot Run Up Competition.
Gait-Adaptive Perceptive Humanoid Locomotion with Real-Time Under-Base Terrain Reconstruction
Dec 08, 2025For full-size humanoid robots, even with recent advances in reinforcement learning-based control, achieving reliable locomotion on complex terrains, such as long staircases, remains challenging. In such settings, limited perception, ambiguous terrain cues, and insufficient adaptation of gait timing can cause even a single misplaced or mistimed step to result in rapid loss of balance. We introduce a perceptive locomotion framework that merges terrain sensing, gait regulation, and whole-body control into a single reinforcement learning policy. A downward-facing depth camera mounted under the base observes the support region around the feet, and a compact U-Net reconstructs a dense egocentric height map from each frame in real time, operating at the same frequency as the control loop. The perceptual height map, together with proprioceptive observations, is processed by a unified policy that produces joint commands and a global stepping-phase signal, allowing gait timing and whole-body posture to be adapted jointly to the commanded motion and local terrain geometry. We further adopt a single-stage successive teacher-student training scheme for efficient policy learning and knowledge transfer. Experiments conducted on a 31-DoF, 1.65 m humanoid robot demonstrate robust locomotion in both simulation and real-world settings, including forward and backward stair ascent and descent, as well as crossing a 46 cm gap. Project Page:https://ga-phl.github.io/
Representation Understanding via Activation Maximization
Aug 10, 2025Understanding internal feature representations of deep neural networks (DNNs) is a fundamental step toward model interpretability. Inspired by neuroscience methods that probe biological neurons using visual stimuli, recent deep learning studies have employed Activation Maximization (AM) to synthesize inputs that elicit strong responses from artificial neurons. In this work, we propose a unified feature visualization framework applicable to both Convolutional Neural Networks (CNNs) and Vision Transformers (ViTs). Unlike prior efforts that predominantly focus on the last output-layer neurons in CNNs, we extend feature visualization to intermediate layers as well, offering deeper insights into the hierarchical structure of learned feature representations. Furthermore, we investigate how activation maximization can be leveraged to generate adversarial examples, revealing potential vulnerabilities and decision boundaries of DNNs. Our experiments demonstrate the effectiveness of our approach in both traditional CNNs and modern ViT, highlighting its generalizability and interpretive value.
Revisiting Data Attribution for Influence Functions
Aug 10, 2025The goal of data attribution is to trace the model's predictions through the learning algorithm and back to its training data. thereby identifying the most influential training samples and understanding how the model's behavior leads to particular predictions. Understanding how individual training examples influence a model's predictions is fundamental for machine learning interpretability, data debugging, and model accountability. Influence functions, originating from robust statistics, offer an efficient, first-order approximation to estimate the impact of marginally upweighting or removing a data point on a model's learned parameters and its subsequent predictions, without the need for expensive retraining. This paper comprehensively reviews the data attribution capability of influence functions in deep learning. We discuss their theoretical foundations, recent algorithmic advances for efficient inverse-Hessian-vector product estimation, and evaluate their effectiveness for data attribution and mislabel detection. Finally, highlighting current challenges and promising directions for unleashing the huge potential of influence functions in large-scale, real-world deep learning scenarios.
Extract-and-Abstract: Unifying Extractive and Abstractive Summarization within Single Encoder-Decoder Framework
Sep 18, 2024



Extract-then-Abstract is a naturally coherent paradigm to conduct abstractive summarization with the help of salient information identified by the extractive model. Previous works that adopt this paradigm train the extractor and abstractor separately and introduce extra parameters to highlight the extracted salients to the abstractor, which results in error accumulation and additional training costs. In this paper, we first introduce a parameter-free highlight method into the encoder-decoder framework: replacing the encoder attention mask with a saliency mask in the cross-attention module to force the decoder to focus only on salient parts of the input. A preliminary analysis compares different highlight methods, demonstrating the effectiveness of our saliency mask. We further propose the novel extract-and-abstract paradigm, ExtAbs, which jointly and seamlessly performs Extractive and Abstractive summarization tasks within single encoder-decoder model to reduce error accumulation. In ExtAbs, the vanilla encoder is augmented to extract salients, and the vanilla decoder is modified with the proposed saliency mask to generate summaries. Built upon BART and PEGASUS, experiments on three datasets show that ExtAbs can achieve superior performance than baselines on the extractive task and performs comparable, or even better than the vanilla models on the abstractive task.
Noise-Free Explanation for Driving Action Prediction
Jul 08, 2024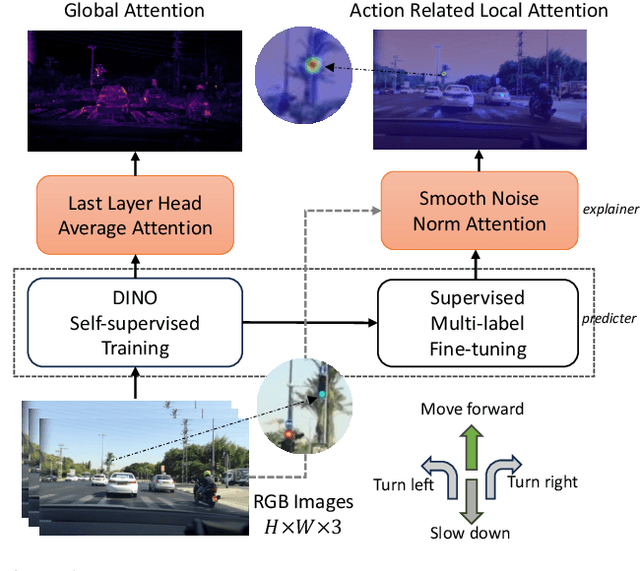

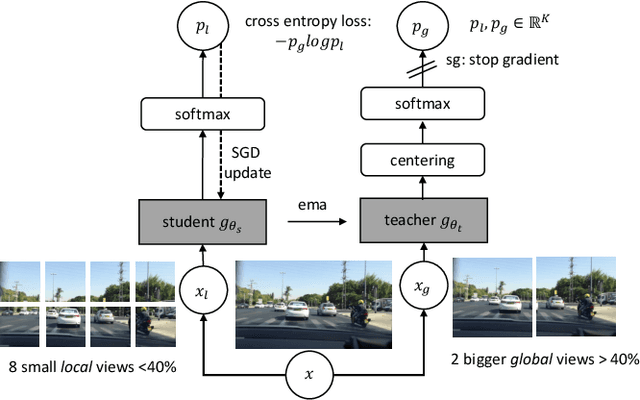
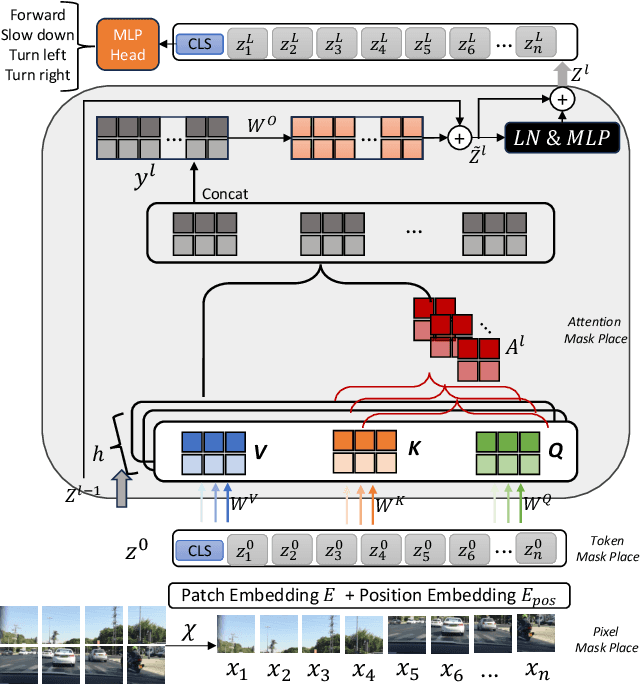
Although attention mechanisms have achieved considerable progress in Transformer-based architectures across various Artificial Intelligence (AI) domains, their inner workings remain to be explored. Existing explainable methods have different emphases but are rather one-sided. They primarily analyse the attention mechanisms or gradient-based attribution while neglecting the magnitudes of input feature values or the skip-connection module. Moreover, they inevitably bring spurious noisy pixel attributions unrelated to the model's decision, hindering humans' trust in the spotted visualization result. Hence, we propose an easy-to-implement but effective way to remedy this flaw: Smooth Noise Norm Attention (SNNA). We weigh the attention by the norm of the transformed value vector and guide the label-specific signal with the attention gradient, then randomly sample the input perturbations and average the corresponding gradients to produce noise-free attribution. Instead of evaluating the explanation method on the binary or multi-class classification tasks like in previous works, we explore the more complex multi-label classification scenario in this work, i.e., the driving action prediction task, and trained a model for it specifically. Both qualitative and quantitative evaluation results show the superiority of SNNA compared to other SOTA attention-based explainable methods in generating a clearer visual explanation map and ranking the input pixel importance.
When NOMA Meets AIGC: Enhanced Wireless Federated Learning
Jun 16, 2024Wireless federated learning (WFL) enables devices to collaboratively train a global model via local model training, uploading and aggregating. However, WFL faces the data scarcity/heterogeneity problem (i.e., data are limited and unevenly distributed among devices) that degrades the learning performance. In this regard, artificial intelligence generated content (AIGC) can synthesize various types of data to compensate for the insufficient local data. Nevertheless, downloading synthetic data or uploading local models iteratively takes a lot of time, especially for a large amount of devices. To address this issue, we propose to leverage non-orthogonal multiple access (NOMA) to achieve efficient synthetic data and local model transmission. This paper is the first to combine AIGC and NOMA with WFL to maximally enhance the learning performance. For the proposed NOMA+AIGC-enhanced WFL, the problem of jointly optimizing the synthetic data distribution, two-way communication and computation resource allocation to minimize the global learning error is investigated. The problem belongs to NP-hard mixed integer nonlinear programming, whose optimal solution is intractable to find. We first employ the block coordinate descent method to decouple the complicated-coupled variables, and then resort to our analytical method to derive an efficient low-complexity local optimal solution with partial closed-form results. Extensive simulations validate the superiority of the proposed scheme compared to the existing and benchmark schemes such as the frequency/time division multiple access based AIGC-enhanced schemes.
Fair Computation Offloading for RSMA-Assisted Mobile Edge Computing Networks
Jun 16, 2024



Rate splitting multiple access (RSMA) provides a flexible transmission framework that can be applied in mobile edge computing (MEC) systems. However, the research work on RSMA-assisted MEC systems is still at the infancy and many design issues remain unsolved, such as the MEC server and channel allocation problem in general multi-server and multi-channel scenarios as well as the user fairness issues. In this regard, we study an RSMA-assisted MEC system with multiple MEC servers, channels and devices, and consider the fairness among devices. A max-min fairness computation offloading problem to maximize the minimum computation offloading rate is investigated. Since the problem is difficult to solve optimally, we develop an efficient algorithm to obtain a suboptimal solution. Particularly, the time allocation and the computing frequency allocation are derived as closed-form functions of the transmit power allocation and the successive interference cancellation (SIC) decoding order, while the SIC decoding order is obtained heuristically, and the bisection search and the successive convex approximation methods are employed to optimize the transmit power allocation. For the MEC server and channel allocation problem, we transform it into a hypergraph matching problem and solve it by matching theory. Simulation results demonstrate that the proposed RSMA-assisted MEC system outperforms current MEC systems under various system setups.
Power Optimization for Integrated Active and Passive Sensing in DFRC Systems
Feb 17, 2024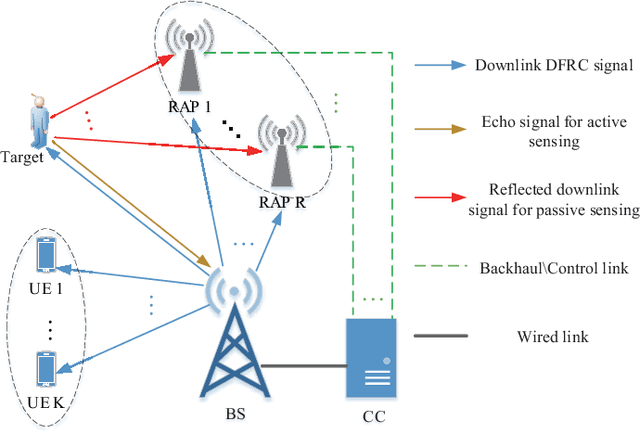


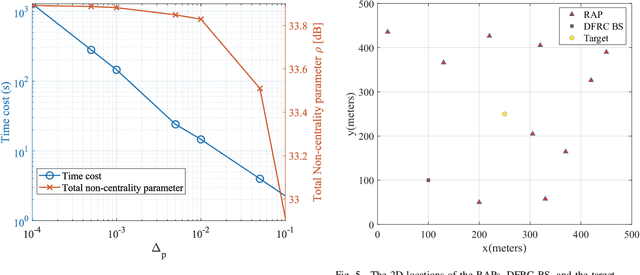
Most existing works on dual-function radar-communication (DFRC) systems mainly focus on active sensing, but ignore passive sensing. To leverage multi-static sensing capability, we explore integrated active and passive sensing (IAPS) in DFRC systems to remedy sensing performance. The multi-antenna base station (BS) is responsible for communication and active sensing by transmitting signals to user equipments while detecting a target according to echo signals. In contrast, passive sensing is performed at the receive access points (RAPs). We consider both the cases where the capacity of the backhaul links between the RAPs and BS is unlimited or limited and adopt different fusion strategies. Specifically, when the backhaul capacity is unlimited, the BS and RAPs transfer sensing signals they have received to the central controller (CC) for signal fusion. The CC processes the signals and leverages the generalized likelihood ratio test detector to determine the present of a target. However, when the backhaul capacity is limited, each RAP, as well as the BS, makes decisions independently and sends its binary inference results to the CC for result fusion via voting aggregation. Then, aiming at maximize the target detection probability under communication quality of service constraints, two power optimization algorithms are proposed. Finally, numerical simulations demonstrate that the sensing performance in case of unlimited backhaul capacity is much better than that in case of limited backhaul capacity. Moreover, it implied that the proposed IAPS scheme outperforms only-passive and only-active sensing schemes, especially in unlimited capacity case.
LIPEx -- Locally Interpretable Probabilistic Explanations -- To Look Beyond The True Class
Oct 07, 2023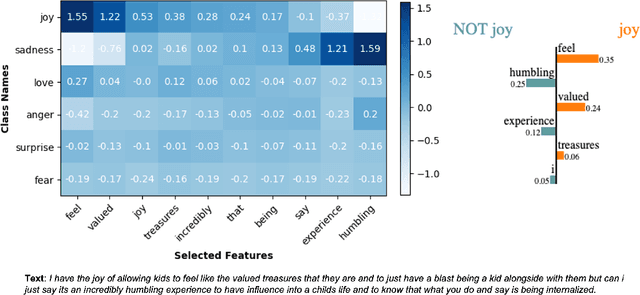
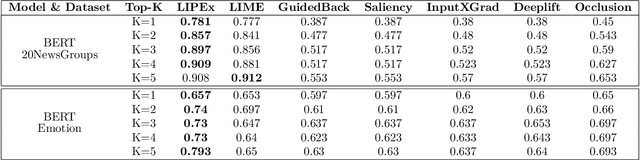
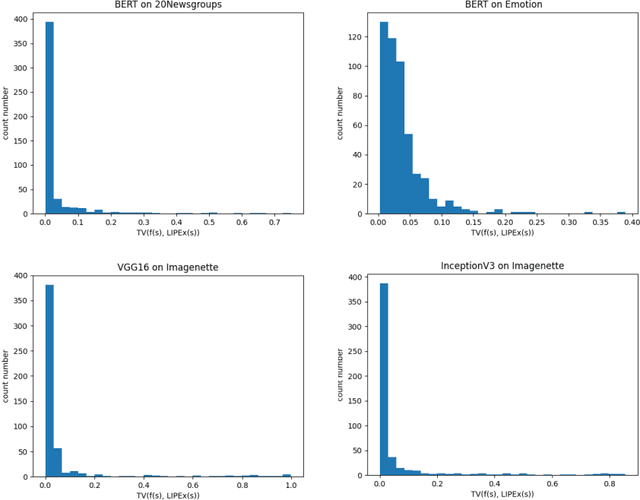

In this work, we instantiate a novel perturbation-based multi-class explanation framework, LIPEx (Locally Interpretable Probabilistic Explanation). We demonstrate that LIPEx not only locally replicates the probability distributions output by the widely used complex classification models but also provides insight into how every feature deemed to be important affects the prediction probability for each of the possible classes. We achieve this by defining the explanation as a matrix obtained via regression with respect to the Hellinger distance in the space of probability distributions. Ablation tests on text and image data, show that LIPEx-guided removal of important features from the data causes more change in predictions for the underlying model than similar tests on other saliency-based or feature importance-based XAI methods. It is also shown that compared to LIME, LIPEx is much more data efficient in terms of the number of perturbations needed for reliable evaluation of the explanation.