 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJoint Action Language Modelling for Transparent Policy Execution
Apr 14, 2025



An agent's intention often remains hidden behind the black-box nature of embodied policies. Communication using natural language statements that describe the next action can provide transparency towards the agent's behavior. We aim to insert transparent behavior directly into the learning process, by transforming the problem of policy learning into a language generation problem and combining it with traditional autoregressive modelling. The resulting model produces transparent natural language statements followed by tokens representing the specific actions to solve long-horizon tasks in the Language-Table environment. Following previous work, the model is able to learn to produce a policy represented by special discretized tokens in an autoregressive manner. We place special emphasis on investigating the relationship between predicting actions and producing high-quality language for a transparent agent. We find that in many cases both the quality of the action trajectory and the transparent statement increase when they are generated simultaneously.
Attributes-aware Visual Emotion Representation Learning
Apr 09, 2025



Visual emotion analysis or recognition has gained considerable attention due to the growing interest in understanding how images can convey rich semantics and evoke emotions in human perception. However, visual emotion analysis poses distinctive challenges compared to traditional vision tasks, especially due to the intricate relationship between general visual features and the different affective states they evoke, known as the affective gap. Researchers have used deep representation learning methods to address this challenge of extracting generalized features from entire images. However, most existing methods overlook the importance of specific emotional attributes such as brightness, colorfulness, scene understanding, and facial expressions. Through this paper, we introduce A4Net, a deep representation network to bridge the affective gap by leveraging four key attributes: brightness (Attribute 1), colorfulness (Attribute 2), scene context (Attribute 3), and facial expressions (Attribute 4). By fusing and jointly training all aspects of attribute recognition and visual emotion analysis, A4Net aims to provide a better insight into emotional content in images. Experimental results show the effectiveness of A4Net, showcasing competitive performance compared to state-of-the-art methods across diverse visual emotion datasets. Furthermore, visualizations of activation maps generated by A4Net offer insights into its ability to generalize across different visual emotion datasets.
From Concrete to Abstract: A Multimodal Generative Approach to Abstract Concept Learning
Oct 03, 2024



Understanding and manipulating concrete and abstract concepts is fundamental to human intelligence. Yet, they remain challenging for artificial agents. This paper introduces a multimodal generative approach to high order abstract concept learning, which integrates visual and categorical linguistic information from concrete ones. Our model initially grounds subordinate level concrete concepts, combines them to form basic level concepts, and finally abstracts to superordinate level concepts via the grounding of basic-level concepts. We evaluate the model language learning ability through language-to-visual and visual-to-language tests with high order abstract concepts. Experimental results demonstrate the proficiency of the model in both language understanding and language naming tasks.
Noise-Free Explanation for Driving Action Prediction
Jul 08, 2024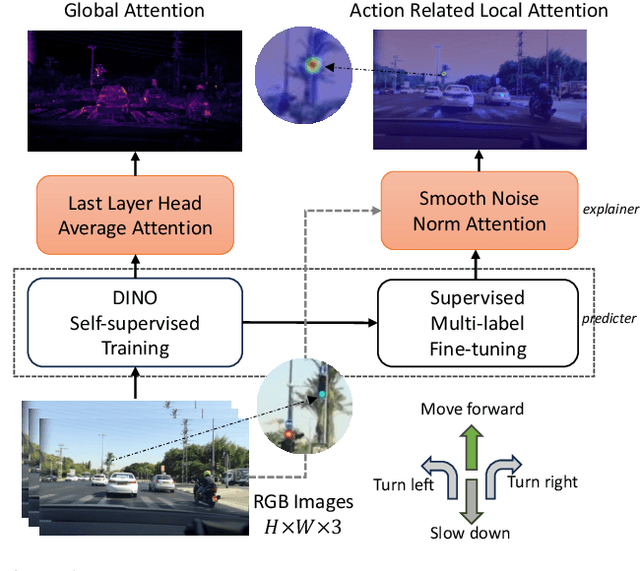

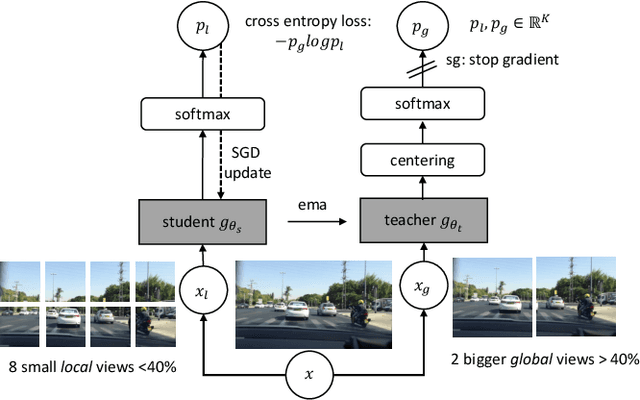
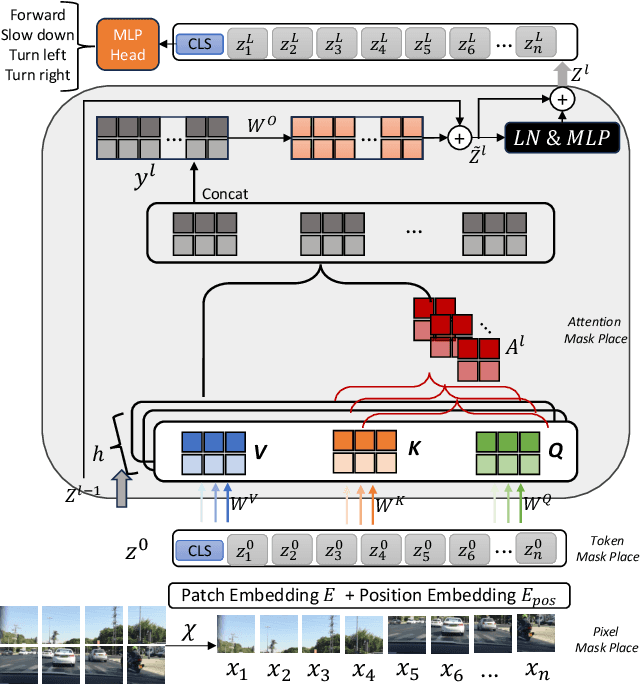
Although attention mechanisms have achieved considerable progress in Transformer-based architectures across various Artificial Intelligence (AI) domains, their inner workings remain to be explored. Existing explainable methods have different emphases but are rather one-sided. They primarily analyse the attention mechanisms or gradient-based attribution while neglecting the magnitudes of input feature values or the skip-connection module. Moreover, they inevitably bring spurious noisy pixel attributions unrelated to the model's decision, hindering humans' trust in the spotted visualization result. Hence, we propose an easy-to-implement but effective way to remedy this flaw: Smooth Noise Norm Attention (SNNA). We weigh the attention by the norm of the transformed value vector and guide the label-specific signal with the attention gradient, then randomly sample the input perturbations and average the corresponding gradients to produce noise-free attribution. Instead of evaluating the explanation method on the binary or multi-class classification tasks like in previous works, we explore the more complex multi-label classification scenario in this work, i.e., the driving action prediction task, and trained a model for it specifically. Both qualitative and quantitative evaluation results show the superiority of SNNA compared to other SOTA attention-based explainable methods in generating a clearer visual explanation map and ranking the input pixel importance.