 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGrounding Hierarchical Vision-Language-Action Models Through Explicit Language-Action Alignment
Apr 07, 2026Achieving robot transparency is a critical step toward effective human-robot collaboration. To be transparent, a robot's natural language communication must be consistent with its actions and explicitly grounded in the task and environment. Existing hierarchical Vision-Language-Action (VLA) models can generate language (e.g., through chain-of-thought) and low-level actions. However, current work does not consider explicit alignment between these modalities during training. To address this crucial gap, we propose a novel training framework that explicitly grounds hierarchical VLA sub-task descriptions with respect to the visual observation and action space. Our framework uses a contrastive model to assess the alignment between generated language and corresponding action trajectories. This contrastive model enables direct ranking of different language-trajectory pairs based on their alignment, allowing us to refine the grounding of our hierarchical VLA through offline preference learning. We apply our framework to the LanguageTable dataset, a benchmark dataset of human language-annotated trajectories, and provide critical insights into multimodal grounding representations, all while establishing a strong baseline that achieves performance comparable to fully supervised fine-tuning and minimizing the need for costly data annotations.
Hierarchical, Interpretable, Label-Free Concept Bottleneck Model
Apr 02, 2026Concept Bottleneck Models (CBMs) introduce interpretability to black-box deep learning models by predicting labels through human-understandable concepts. However, unlike humans, who identify objects at different levels of abstraction using both general and specific features, existing CBMs operate at a single semantic level in both concept and label space. We propose HIL-CBM, a Hierarchical Interpretable Label-Free Concept Bottleneck Model that extends CBMs into a hierarchical framework to enhance interpretability by more closely mirroring the human cognitive process. HIL-CBM enables classification and explanation across multiple semantic levels without requiring relational concept annotations. HIL-CBM aligns the abstraction level of concept-based explanations with that of model predictions, progressing from abstract to concrete. This is achieved by (i) introducing a gradient-based visual consistency loss that encourages abstraction layers to focus on similar spatial regions, and (ii) training dual classification heads, each operating on feature concepts at different abstraction levels. Experiments on benchmark datasets demonstrate that HIL-CBM outperforms state-of-the-art sparse CBMs in classification accuracy. Human evaluations further show that HIL-CBM provides more interpretable and accurate explanations, while maintaining a hierarchical and label-free approach to feature concepts.
Fake or Real, Can Robots Tell? Evaluating Embodied Vision-Language Models on Real and 3D-Printed Objects
Jun 24, 2025Robotic scene understanding increasingly relies on vision-language models (VLMs) to generate natural language descriptions of the environment. In this work, we present a comparative study of captioning strategies for tabletop scenes captured by a robotic arm equipped with an RGB camera. The robot collects images of objects from multiple viewpoints, and we evaluate several models that generate scene descriptions. We compare the performance of various captioning models, like BLIP and VLMs. Our experiments examine the trade-offs between single-view and multi-view captioning, and difference between recognising real-world and 3D printed objects. We quantitatively evaluate object identification accuracy, completeness, and naturalness of the generated captions. Results show that VLMs can be used in robotic settings where common objects need to be recognised, but fail to generalise to novel representations. Our findings provide practical insights into deploying foundation models for embodied agents in real-world settings.
From Concrete to Abstract: A Multimodal Generative Approach to Abstract Concept Learning
Oct 03, 2024



Understanding and manipulating concrete and abstract concepts is fundamental to human intelligence. Yet, they remain challenging for artificial agents. This paper introduces a multimodal generative approach to high order abstract concept learning, which integrates visual and categorical linguistic information from concrete ones. Our model initially grounds subordinate level concrete concepts, combines them to form basic level concepts, and finally abstracts to superordinate level concepts via the grounding of basic-level concepts. We evaluate the model language learning ability through language-to-visual and visual-to-language tests with high order abstract concepts. Experimental results demonstrate the proficiency of the model in both language understanding and language naming tasks.
Bridging the Communication Gap: Artificial Agents Learning Sign Language through Imitation
Jun 14, 2024



Artificial agents, particularly humanoid robots, interact with their environment, objects, and people using cameras, actuators, and physical presence. Their communication methods are often pre-programmed, limiting their actions and interactions. Our research explores acquiring non-verbal communication skills through learning from demonstrations, with potential applications in sign language comprehension and expression. In particular, we focus on imitation learning for artificial agents, exemplified by teaching a simulated humanoid American Sign Language. We use computer vision and deep learning to extract information from videos, and reinforcement learning to enable the agent to replicate observed actions. Compared to other methods, our approach eliminates the need for additional hardware to acquire information. We demonstrate how the combination of these different techniques offers a viable way to learn sign language. Our methodology successfully teaches 5 different signs involving the upper body (i.e., arms and hands). This research paves the way for advanced communication skills in artificial agents.
HandMime: Sign Language Fingerspelling Acquisition via Imitation Learning
Sep 12, 2022
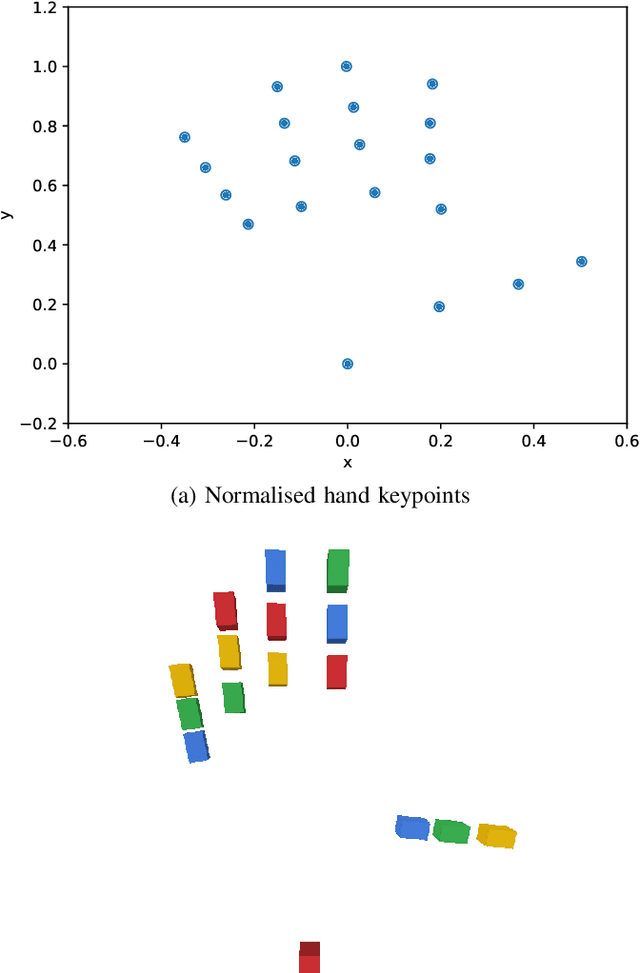
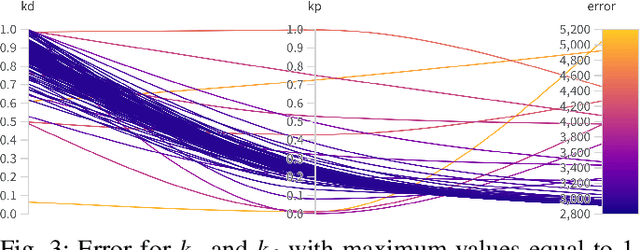
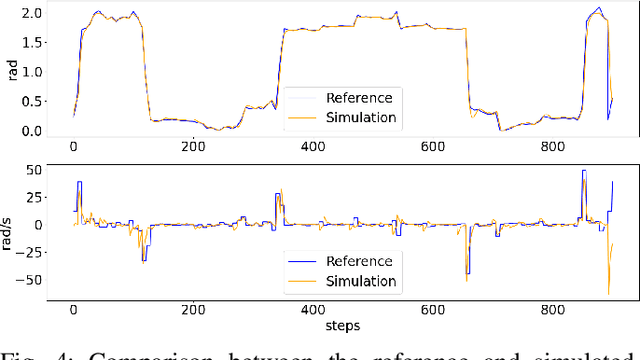
Learning fine-grained movements is among the most challenging topics in robotics. This holds true especially for robotic hands. Robotic sign language acquisition or, more specifically, fingerspelling sign language acquisition in robots can be considered a specific instance of such challenge. In this paper, we propose an approach for learning dexterous motor imitation from videos examples, without the use of any additional information. We build an URDF model of a robotic hand with a single actuator for each joint. By leveraging pre-trained deep vision models, we extract the 3D pose of the hand from RGB videos. Then, using state-of-the-art reinforcement learning algorithms for motion imitation (namely, proximal policy optimisation), we train a policy to reproduce the movement extracted from the demonstrations. We identify the best set of hyperparameters to perform imitation based on a reference motion. Additionally, we demonstrate the ability of our approach to generalise over 6 different fingerspelled letters.
WLASL-LEX: a Dataset for Recognising Phonological Properties in American Sign Language
Mar 11, 2022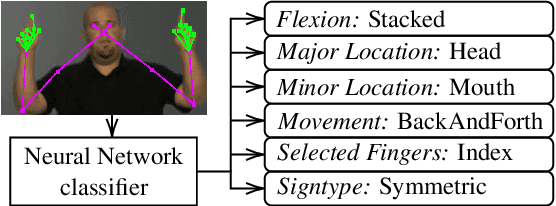
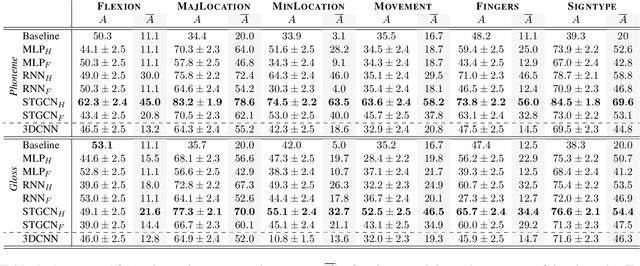

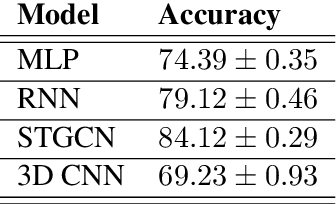
Signed Language Processing (SLP) concerns the automated processing of signed languages, the main means of communication of Deaf and hearing impaired individuals. SLP features many different tasks, ranging from sign recognition to translation and production of signed speech, but has been overlooked by the NLP community thus far. In this paper, we bring to attention the task of modelling the phonology of sign languages. We leverage existing resources to construct a large-scale dataset of American Sign Language signs annotated with six different phonological properties. We then conduct an extensive empirical study to investigate whether data-driven end-to-end and feature-based approaches can be optimised to automatically recognise these properties. We find that, despite the inherent challenges of the task, graph-based neural networks that operate over skeleton features extracted from raw videos are able to succeed at the task to a varying degree. Most importantly, we show that this performance pertains even on signs unobserved during training.
Phonology Recognition in American Sign Language
Oct 01, 2021



Inspired by recent developments in natural language processing, we propose a novel approach to sign language processing based on phonological properties validated by American Sign Language users. By taking advantage of datasets composed of phonological data and people speaking sign language, we use a pretrained deep model based on mesh reconstruction to extract the 3D coordinates of the signers keypoints. Then, we train standard statistical and deep machine learning models in order to assign phonological classes to each temporal sequence of coordinates. Our paper introduces the idea of exploiting the phonological properties manually assigned by sign language users to classify videos of people performing signs by regressing a 3D mesh. We establish a new baseline for this problem based on the statistical distribution of 725 different signs. Our best-performing models achieve a micro-averaged F1-score of 58% for the major location class and 70% for the sign type using statistical and deep learning algorithms, compared to their corresponding baselines of 35% and 39%.
A Machine Learning-based Approach to Detect Threats in Bio-Cyber DNA Storage Systems
Sep 28, 2020

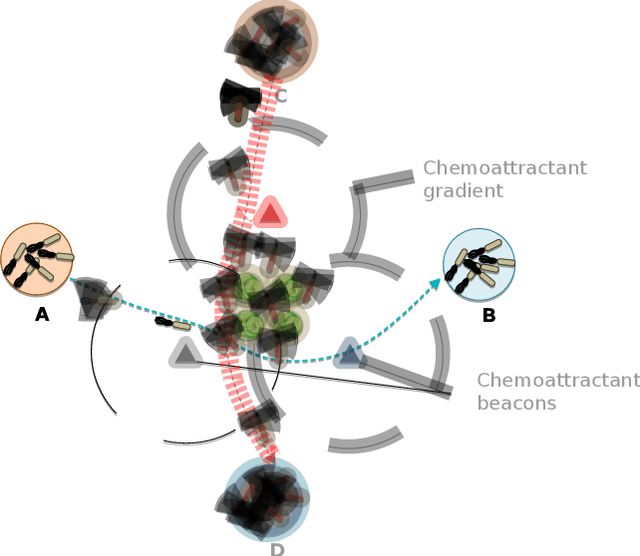
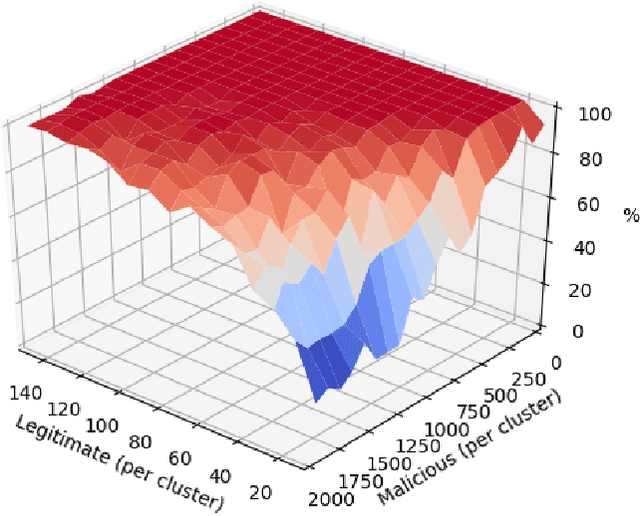
Data storage is one of the main computing issues of this century. Not only storage devices are converging to strict physical limits, but also the amount of data generated by users is growing at an unbelievable rate. To face these challenges, data centres grew constantly over the past decades. However, this growth comes with a price, particularly from the environmental point of view. Among various promising media, DNA is one of the most fascinating candidate. In our previous work, we have proposed an automated archival architecture which uses bioengineered bacteria to store and retrieve data, previously encoded into DNA. This storage technique is one example of how biological media can deliver power-efficient storing solutions. The similarities between these biological media and classical ones can also be a drawback, as malicious parties might replicate traditional attacks on the former archival system, using biological instruments and techniques. In this paper, first we analyse the main characteristics of our storage system and the different types of attacks that could be executed on it. Then, aiming at identifying on-going attacks, we propose and evaluate detection techniques, which rely on traditional metrics and machine learning algorithms. We identify and adapt two suitable metrics for this purpose, namely generalized entropy and information distance. Moreover, our trained models achieve an AUROC over 0.99 and AUPRC over 0.91.