 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBridging the Communication Gap: Artificial Agents Learning Sign Language through Imitation
Jun 14, 2024



Artificial agents, particularly humanoid robots, interact with their environment, objects, and people using cameras, actuators, and physical presence. Their communication methods are often pre-programmed, limiting their actions and interactions. Our research explores acquiring non-verbal communication skills through learning from demonstrations, with potential applications in sign language comprehension and expression. In particular, we focus on imitation learning for artificial agents, exemplified by teaching a simulated humanoid American Sign Language. We use computer vision and deep learning to extract information from videos, and reinforcement learning to enable the agent to replicate observed actions. Compared to other methods, our approach eliminates the need for additional hardware to acquire information. We demonstrate how the combination of these different techniques offers a viable way to learn sign language. Our methodology successfully teaches 5 different signs involving the upper body (i.e., arms and hands). This research paves the way for advanced communication skills in artificial agents.
HandMime: Sign Language Fingerspelling Acquisition via Imitation Learning
Sep 12, 2022
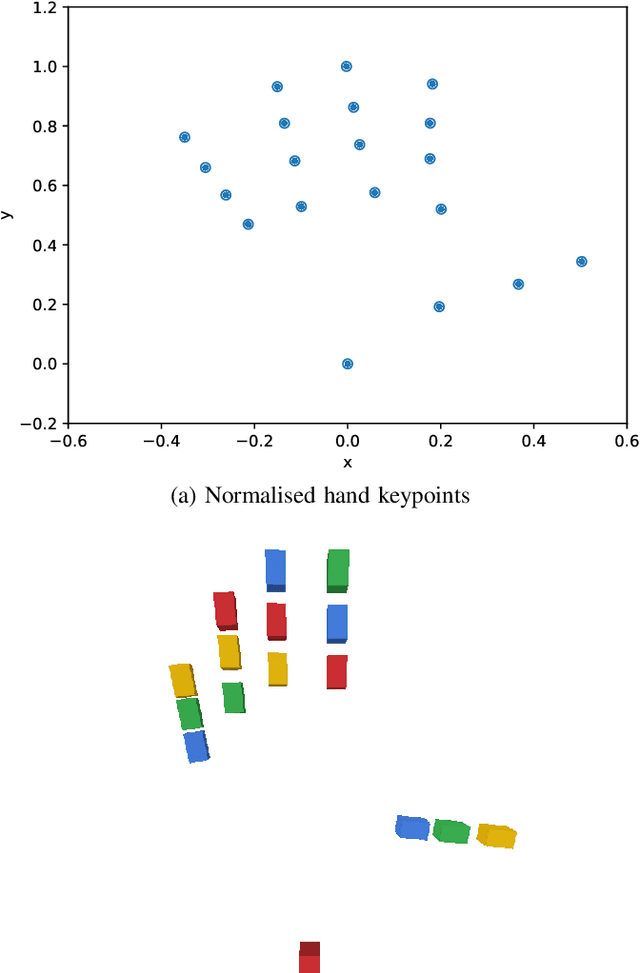
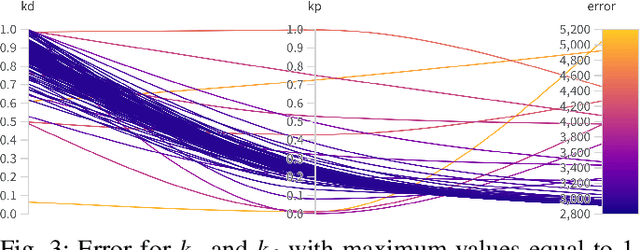
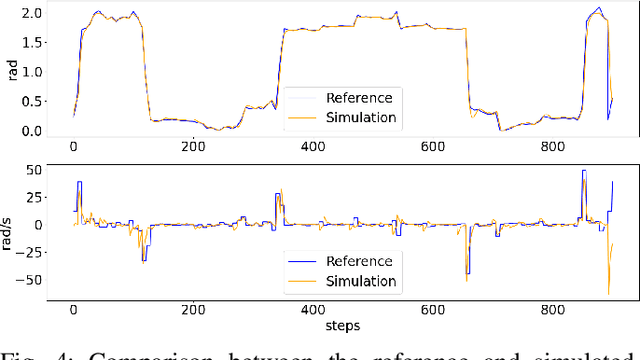
Learning fine-grained movements is among the most challenging topics in robotics. This holds true especially for robotic hands. Robotic sign language acquisition or, more specifically, fingerspelling sign language acquisition in robots can be considered a specific instance of such challenge. In this paper, we propose an approach for learning dexterous motor imitation from videos examples, without the use of any additional information. We build an URDF model of a robotic hand with a single actuator for each joint. By leveraging pre-trained deep vision models, we extract the 3D pose of the hand from RGB videos. Then, using state-of-the-art reinforcement learning algorithms for motion imitation (namely, proximal policy optimisation), we train a policy to reproduce the movement extracted from the demonstrations. We identify the best set of hyperparameters to perform imitation based on a reference motion. Additionally, we demonstrate the ability of our approach to generalise over 6 different fingerspelled letters.
WLASL-LEX: a Dataset for Recognising Phonological Properties in American Sign Language
Mar 11, 2022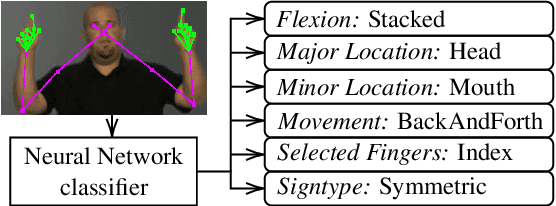
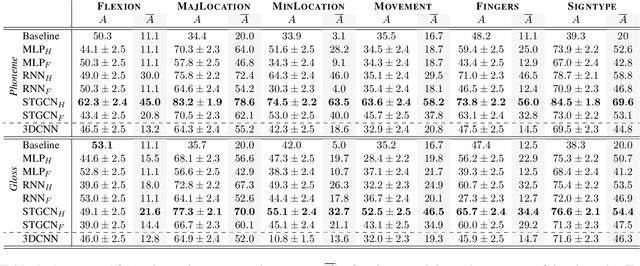

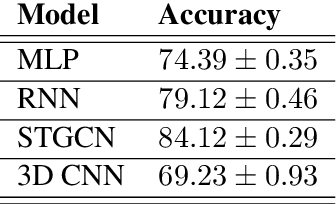
Signed Language Processing (SLP) concerns the automated processing of signed languages, the main means of communication of Deaf and hearing impaired individuals. SLP features many different tasks, ranging from sign recognition to translation and production of signed speech, but has been overlooked by the NLP community thus far. In this paper, we bring to attention the task of modelling the phonology of sign languages. We leverage existing resources to construct a large-scale dataset of American Sign Language signs annotated with six different phonological properties. We then conduct an extensive empirical study to investigate whether data-driven end-to-end and feature-based approaches can be optimised to automatically recognise these properties. We find that, despite the inherent challenges of the task, graph-based neural networks that operate over skeleton features extracted from raw videos are able to succeed at the task to a varying degree. Most importantly, we show that this performance pertains even on signs unobserved during training.
Phonology Recognition in American Sign Language
Oct 01, 2021



Inspired by recent developments in natural language processing, we propose a novel approach to sign language processing based on phonological properties validated by American Sign Language users. By taking advantage of datasets composed of phonological data and people speaking sign language, we use a pretrained deep model based on mesh reconstruction to extract the 3D coordinates of the signers keypoints. Then, we train standard statistical and deep machine learning models in order to assign phonological classes to each temporal sequence of coordinates. Our paper introduces the idea of exploiting the phonological properties manually assigned by sign language users to classify videos of people performing signs by regressing a 3D mesh. We establish a new baseline for this problem based on the statistical distribution of 725 different signs. Our best-performing models achieve a micro-averaged F1-score of 58% for the major location class and 70% for the sign type using statistical and deep learning algorithms, compared to their corresponding baselines of 35% and 39%.
ChoiceNet: CNN learning through choice of multiple feature map representations
Apr 20, 2019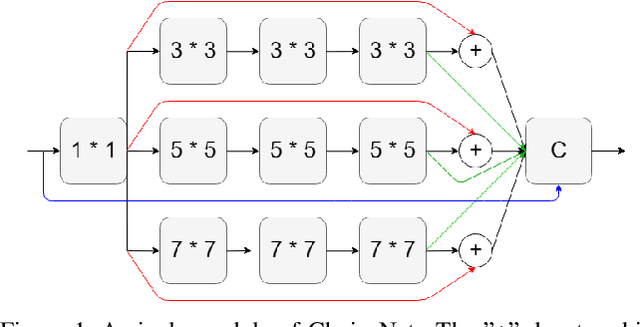
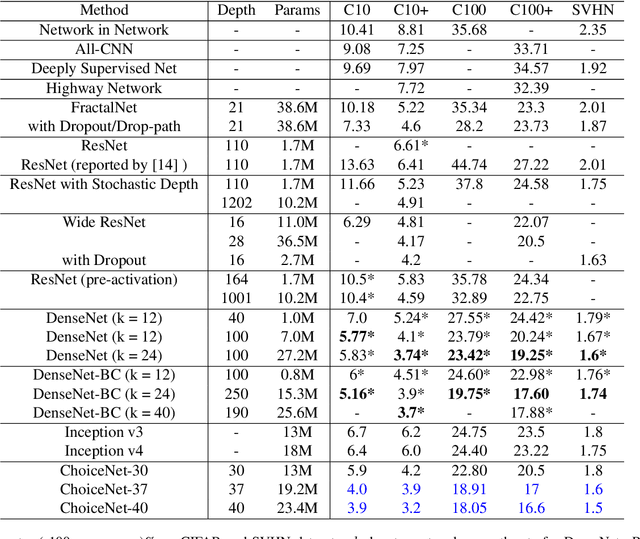
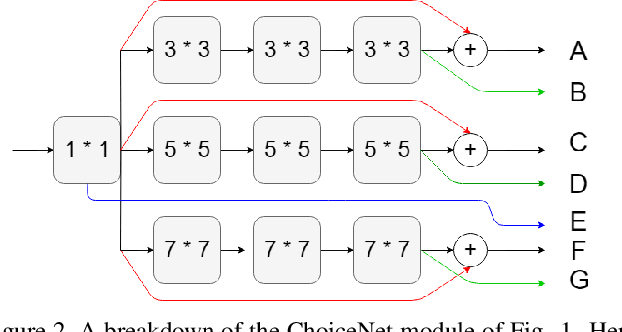
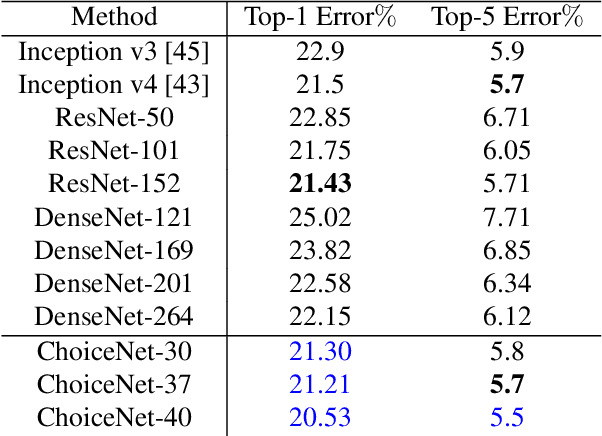
We introduce a new architecture called ChoiceNet where each layer of the network is highly connected with skip connections and channelwise concatenations. This enables the network to alleviate the problem of vanishing gradients, reduces the number of parameters without sacrificing performance, and encourages feature reuse. We evaluate our proposed architecture on three benchmark datasetsforobjectrecognitiontasks(CIFAR-10,CIFAR100, SVHN) and on a semantic segmentation dataset (CamVid).