 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContinuum Robot Modeling with Action Conditioned Flow Matching
May 09, 2026Predicting the shape of tendon driven continuum robots (TDCRs) at steady state from actuation remains challenging due to continuous deformation, complex tendon routing, compliance, friction, and fabrication variability. In this paper, we address this problem as kinematic self modeling conditioned on action. We present a lightweight 3D printed TDCR hardware platform and an RGB-D data collection pipeline with multiple cameras, and we learn a point cloud flow matching model that maps motor actuation states to the robot's settled 3D geometry. The model is trained from randomly sampled quasi static configurations and evaluated on test motor commands within the same TDCR design family and actuation range. We compare against prior 3D deformable object and robot self modeling approaches in both MuJoCo simulation and real hardware experiments. Experiments on simulated 2-, 3-, and 5-module TDCRs and real 2- and 3-module robots show improved shape prediction accuracy under CD and EMD metrics. We further show in simulation that the same conditional formulation generalizes to tip payload as a conditioning input, enabling payload conditioned steady-state shape prediction. These results demonstrate a data driven self modeling framework for quasi static TDCR geometry prediction.
Reconstruction of a 3D wireframe from a single line drawing via generative depth estimation
Apr 15, 2026The conversion of 2D freehand sketches into 3D models remains a pivotal challenge in computer vision, bridging the gap between human creativity and digital fabrication. Traditional line drawing reconstruction relies on brittle symbolic logic, while modern approaches are constrained by rigid parametric modeling, limiting users to predefined CAD primitives. We propose a generative approach by framing reconstruction as a conditional dense depth estimation task. To achieve this, we implement a Latent Diffusion Model (LDM) with a ControlNet-style conditioning framework to resolve the inherent ambiguities of orthographic projections. To support an iterative "sketch-reconstruct-sketch" workflow, we introduce a graph-based BFS masking strategy to simulate partial depth cues. We train and evaluate our approach using a massive dataset of over one million image-depth pairs derived from the ABC Dataset. Our framework demonstrates robust performance across varying shape complexities, providing a scalable pipeline for converting sparse 2D line drawings into dense 3D representations, effectively allowing users to "draw in 3D" without the rigid constraints of traditional CAD.
Evidence of an Emergent "Self" in Continual Robot Learning
Mar 25, 2026A key challenge to understanding self-awareness has been a principled way of quantifying whether an intelligent system has a concept of a "self," and if so how to differentiate the "self" from other cognitive structures. We propose that the "self" can be isolated by seeking the invariant portion of cognitive process that changes relatively little compared to more rapidly acquired cognitive knowledge and skills, because our self is the most persistent aspect of our experiences. We used this principle to analyze the cognitive structure of robots under two conditions: One robot learns a constant task, while a second robot is subjected to continual learning under variable tasks. We find that robots subjected to continual learning develop an invariant subnetwork that is significantly more stable (p < 0.001) compared to the control. We suggest that this principle can offer a window into exploring selfhood in other cognitive AI systems.
Beyond Cropping and Rotation: Automated Evolution of Powerful Task-Specific Augmentations with Generative Models
Feb 03, 2026Data augmentation has long been a cornerstone for reducing overfitting in vision models, with methods like AutoAugment automating the design of task-specific augmentations. Recent advances in generative models, such as conditional diffusion and few-shot NeRFs, offer a new paradigm for data augmentation by synthesizing data with significantly greater diversity and realism. However, unlike traditional augmentations like cropping or rotation, these methods introduce substantial changes that enhance robustness but also risk degrading performance if the augmentations are poorly matched to the task. In this work, we present EvoAug, an automated augmentation learning pipeline, which leverages these generative models alongside an efficient evolutionary algorithm to learn optimal task-specific augmentations. Our pipeline introduces a novel approach to image augmentation that learns stochastic augmentation trees that hierarchically compose augmentations, enabling more structured and adaptive transformations. We demonstrate strong performance across fine-grained classification and few-shot learning tasks. Notably, our pipeline discovers augmentations that align with domain knowledge, even in low-data settings. These results highlight the potential of learned generative augmentations, unlocking new possibilities for robust model training.
Accelerating scientific discovery with the common task framework
Nov 06, 2025Machine learning (ML) and artificial intelligence (AI) algorithms are transforming and empowering the characterization and control of dynamic systems in the engineering, physical, and biological sciences. These emerging modeling paradigms require comparative metrics to evaluate a diverse set of scientific objectives, including forecasting, state reconstruction, generalization, and control, while also considering limited data scenarios and noisy measurements. We introduce a common task framework (CTF) for science and engineering, which features a growing collection of challenge data sets with a diverse set of practical and common objectives. The CTF is a critically enabling technology that has contributed to the rapid advance of ML/AI algorithms in traditional applications such as speech recognition, language processing, and computer vision. There is a critical need for the objective metrics of a CTF to compare the diverse algorithms being rapidly developed and deployed in practice today across science and engineering.
RL-AUX: Reinforcement Learning for Auxiliary Task Generation
Oct 27, 2025Auxiliary Learning (AL) is a special case of Multi-task Learning (MTL) in which a network trains on auxiliary tasks to improve performance on its main task. This technique is used to improve generalization and, ultimately, performance on the network's main task. AL has been demonstrated to improve performance across multiple domains, including navigation, image classification, and natural language processing. One weakness of AL is the need for labeled auxiliary tasks, which can require human effort and domain expertise to generate. Meta Learning techniques have been used to solve this issue by learning an additional auxiliary task generation network that can create helpful tasks for the primary network. The most prominent techniques rely on Bi-Level Optimization, which incurs computational cost and increased code complexity. To avoid the need for Bi-Level Optimization, we present an RL-based approach to dynamically create auxiliary tasks. In this framework, an RL agent is tasked with selecting auxiliary labels for every data point in a training set. The agent is rewarded when their selection improves the performance on the primary task. We also experiment with learning optimal strategies for weighing the auxiliary loss per data point. On the 20-Superclass CIFAR100 problem, our RL approach outperforms human-labeled auxiliary tasks and performs as well as a prominent Bi-Level Optimization technique. Our weight learning approaches significantly outperform all of these benchmarks. For example, a Weight-Aware RL-based approach helps the VGG16 architecture achieve 80.9% test accuracy while the human-labeled auxiliary task setup achieved 75.53%. The goal of this work is to (1) prove that RL is a viable approach to dynamically generate auxiliary tasks and (2) demonstrate that per-sample auxiliary task weights can be learned alongside the auxiliary task labels and can achieve strong results.
Bi-Encoder Contrastive Learning for Fingerprint and Iris Biometrics
Oct 27, 2025There has been a historic assumption that the biometrics of an individual are statistically uncorrelated. We test this assumption by training Bi-Encoder networks on three verification tasks, including fingerprint-to-fingerprint matching, iris-to-iris matching, and cross-modal fingerprint-to-iris matching using 274 subjects with $\sim$100k fingerprints and 7k iris images. We trained ResNet-50 and Vision Transformer backbones in Bi-Encoder architectures such that the contrastive loss between images sampled from the same individual is minimized. The iris ResNet architecture reaches 91 ROC AUC score for iris-to-iris matching, providing clear evidence that the left and right irises of an individual are correlated. Fingerprint models reproduce the positive intra-subject suggested by prior work in this space. This is the first work attempting to use Vision Transformers for this matching. Cross-modal matching rises only slightly above chance, which suggests that more data and a more sophisticated pipeline is needed to obtain compelling results. These findings continue challenge independence assumptions of biometrics and we plan to extend this work to other biometrics in the future. Code available: https://github.com/MatthewSo/bio_fingerprints_iris.
AutoURDF: Unsupervised Robot Modeling from Point Cloud Frames Using Cluster Registration
Dec 07, 2024


Robot description models are essential for simulation and control, yet their creation often requires significant manual effort. To streamline this modeling process, we introduce AutoURDF, an unsupervised approach for constructing description files for unseen robots from point cloud frames. Our method leverages a cluster-based point cloud registration model that tracks the 6-DoF transformations of point clusters. Through analyzing cluster movements, we hierarchically address the following challenges: (1) moving part segmentation, (2) body topology inference, and (3) joint parameter estimation. The complete pipeline produces robot description files that are fully compatible with existing simulators. We validate our method across a variety of robots, using both synthetic and real-world scan data. Results indicate that our approach outperforms previous methods in registration and body topology estimation accuracy, offering a scalable solution for automated robot modeling.
Robot Metabolism: Towards machines that can grow by consuming other machines
Nov 17, 2024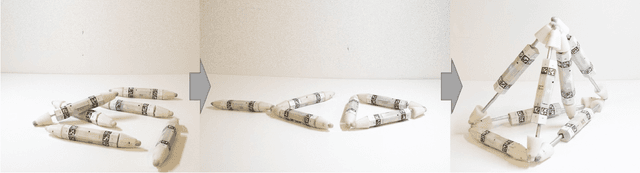
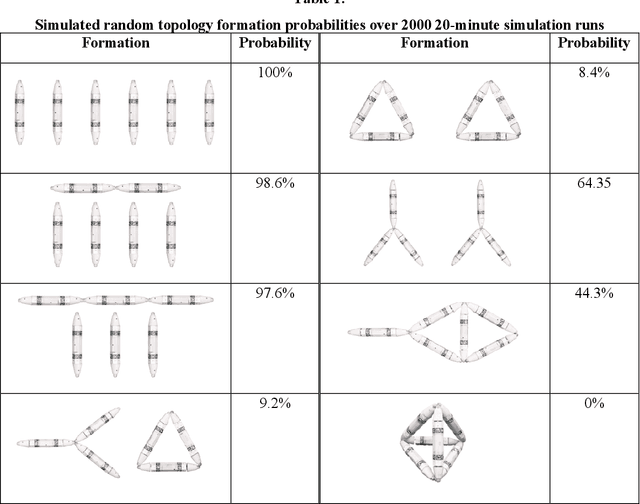
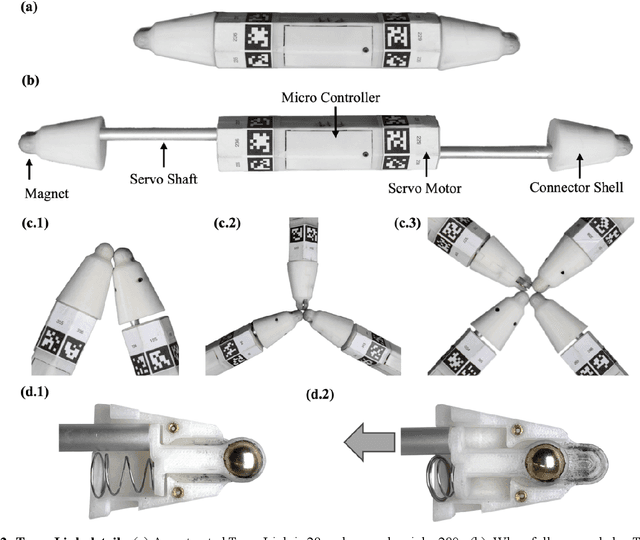
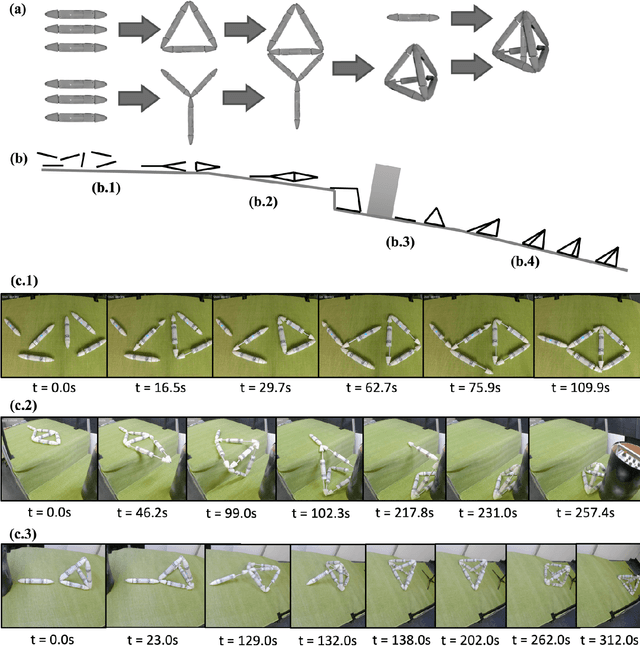
Biological lifeforms can heal, grow, adapt, and reproduce -- abilities essential for sustained survival and development. In contrast, robots today are primarily monolithic machines with limited ability to self-repair, physically develop, or incorporate material from their environments. A key challenge to such physical adaptation has been that while robot minds are rapidly evolving new behaviors through AI, their bodies remain closed systems, unable to systematically integrate new material to grow or heal. We argue that open-ended physical adaptation is only possible when robots are designed using only a small repertoire of simple modules. This allows machines to mechanically adapt by consuming parts from other machines or their surroundings and shedding broken components. We demonstrate this principle using a truss modular robot platform composed of one-dimensional actuated bars. We show how robots in this space can grow bigger, faster, and more capable by consuming materials from their environment and from other robots. We suggest that machine metabolic processes akin to the one demonstrated here will be an essential part of any sustained future robot ecology.
Aligning AI-driven discovery with human intuition
Oct 09, 2024As data-driven modeling of physical dynamical systems becomes more prevalent, a new challenge is emerging: making these models more compatible and aligned with existing human knowledge. AI-driven scientific modeling processes typically begin with identifying hidden state variables, then deriving governing equations, followed by predicting and analyzing future behaviors. The critical initial step of identification of an appropriate set of state variables remains challenging for two reasons. First, finding a compact set of meaningfully predictive variables is mathematically difficult and under-defined. A second reason is that variables found often lack physical significance, and are therefore difficult for human scientists to interpret. We propose a new general principle for distilling representations that are naturally more aligned with human intuition, without relying on prior physical knowledge. We demonstrate our approach on a number of experimental and simulated system where the variables generated by the AI closely resemble those chosen independently by human scientists. We suggest that this principle can help make human-AI collaboration more fruitful, as well as shed light on how humans make scientific modeling choices.