 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUniRef-Image-Edit: Towards Scalable and Consistent Multi-Reference Image Editing
Feb 15, 2026We present UniRef-Image-Edit, a high-performance multi-modal generation system that unifies single-image editing and multi-image composition within a single framework. Existing diffusion-based editing methods often struggle to maintain consistency across multiple conditions due to limited interaction between reference inputs. To address this, we introduce Sequence-Extended Latent Fusion (SELF), a unified input representation that dynamically serializes multiple reference images into a coherent latent sequence. During a dedicated training stage, all reference images are jointly constrained to fit within a fixed-length sequence under a global pixel-budget constraint. Building upon SELF, we propose a two-stage training framework comprising supervised fine-tuning (SFT) and reinforcement learning (RL). In the SFT stage, we jointly train on single-image editing and multi-image composition tasks to establish a robust generative prior. We adopt a progressive sequence length training strategy, in which all input images are initially resized to a total pixel budget of $1024^2$, and are then gradually increased to $1536^2$ and $2048^2$ to improve visual fidelity and cross-reference consistency. This gradual relaxation of compression enables the model to incrementally capture finer visual details while maintaining stable alignment across references. For the RL stage, we introduce Multi-Source GRPO (MSGRPO), to our knowledge the first reinforcement learning framework tailored for multi-reference image generation. MSGRPO optimizes the model to reconcile conflicting visual constraints, significantly enhancing compositional consistency. We will open-source the code, models, training data, and reward data for community research purposes.
Beyond Cropping and Rotation: Automated Evolution of Powerful Task-Specific Augmentations with Generative Models
Feb 03, 2026Data augmentation has long been a cornerstone for reducing overfitting in vision models, with methods like AutoAugment automating the design of task-specific augmentations. Recent advances in generative models, such as conditional diffusion and few-shot NeRFs, offer a new paradigm for data augmentation by synthesizing data with significantly greater diversity and realism. However, unlike traditional augmentations like cropping or rotation, these methods introduce substantial changes that enhance robustness but also risk degrading performance if the augmentations are poorly matched to the task. In this work, we present EvoAug, an automated augmentation learning pipeline, which leverages these generative models alongside an efficient evolutionary algorithm to learn optimal task-specific augmentations. Our pipeline introduces a novel approach to image augmentation that learns stochastic augmentation trees that hierarchically compose augmentations, enabling more structured and adaptive transformations. We demonstrate strong performance across fine-grained classification and few-shot learning tasks. Notably, our pipeline discovers augmentations that align with domain knowledge, even in low-data settings. These results highlight the potential of learned generative augmentations, unlocking new possibilities for robust model training.
LiveStar: Live Streaming Assistant for Real-World Online Video Understanding
Nov 07, 2025Despite significant progress in Video Large Language Models (Video-LLMs) for offline video understanding, existing online Video-LLMs typically struggle to simultaneously process continuous frame-by-frame inputs and determine optimal response timing, often compromising real-time responsiveness and narrative coherence. To address these limitations, we introduce LiveStar, a pioneering live streaming assistant that achieves always-on proactive responses through adaptive streaming decoding. Specifically, LiveStar incorporates: (1) a training strategy enabling incremental video-language alignment for variable-length video streams, preserving temporal consistency across dynamically evolving frame sequences; (2) a response-silence decoding framework that determines optimal proactive response timing via a single forward pass verification; (3) memory-aware acceleration via peak-end memory compression for online inference on 10+ minute videos, combined with streaming key-value cache to achieve 1.53x faster inference. We also construct an OmniStar dataset, a comprehensive dataset for training and benchmarking that encompasses 15 diverse real-world scenarios and 5 evaluation tasks for online video understanding. Extensive experiments across three benchmarks demonstrate LiveStar's state-of-the-art performance, achieving an average 19.5% improvement in semantic correctness with 18.1% reduced timing difference compared to existing online Video-LLMs, while improving FPS by 12.0% across all five OmniStar tasks. Our model and dataset can be accessed at https://github.com/yzy-bupt/LiveStar.
Kwai Keye-VL Technical Report
Jul 02, 2025While Multimodal Large Language Models (MLLMs) demonstrate remarkable capabilities on static images, they often fall short in comprehending dynamic, information-dense short-form videos, a dominant medium in today's digital landscape. To bridge this gap, we introduce \textbf{Kwai Keye-VL}, an 8-billion-parameter multimodal foundation model engineered for leading-edge performance in short-video understanding while maintaining robust general-purpose vision-language abilities. The development of Keye-VL rests on two core pillars: a massive, high-quality dataset exceeding 600 billion tokens with a strong emphasis on video, and an innovative training recipe. This recipe features a four-stage pre-training process for solid vision-language alignment, followed by a meticulous two-phase post-training process. The first post-training stage enhances foundational capabilities like instruction following, while the second phase focuses on stimulating advanced reasoning. In this second phase, a key innovation is our five-mode ``cold-start'' data mixture, which includes ``thinking'', ``non-thinking'', ``auto-think'', ``think with image'', and high-quality video data. This mixture teaches the model to decide when and how to reason. Subsequent reinforcement learning (RL) and alignment steps further enhance these reasoning capabilities and correct abnormal model behaviors, such as repetitive outputs. To validate our approach, we conduct extensive evaluations, showing that Keye-VL achieves state-of-the-art results on public video benchmarks and remains highly competitive on general image-based tasks (Figure 1). Furthermore, we develop and release the \textbf{KC-MMBench}, a new benchmark tailored for real-world short-video scenarios, where Keye-VL shows a significant advantage.
InstructEngine: Instruction-driven Text-to-Image Alignment
Apr 14, 2025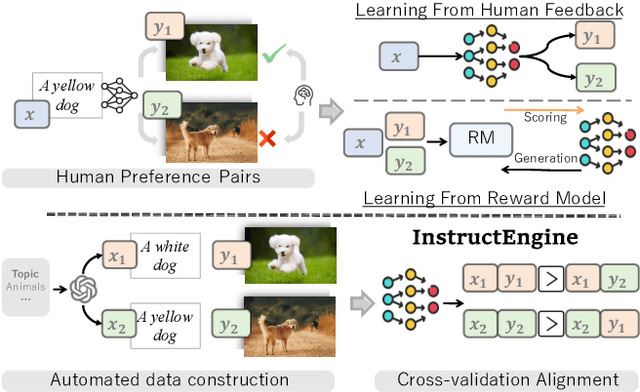
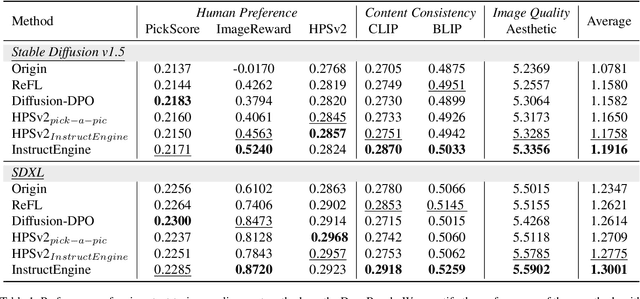

Reinforcement Learning from Human/AI Feedback (RLHF/RLAIF) has been extensively utilized for preference alignment of text-to-image models. Existing methods face certain limitations in terms of both data and algorithm. For training data, most approaches rely on manual annotated preference data, either by directly fine-tuning the generators or by training reward models to provide training signals. However, the high annotation cost makes them difficult to scale up, the reward model consumes extra computation and cannot guarantee accuracy. From an algorithmic perspective, most methods neglect the value of text and only take the image feedback as a comparative signal, which is inefficient and sparse. To alleviate these drawbacks, we propose the InstructEngine framework. Regarding annotation cost, we first construct a taxonomy for text-to-image generation, then develop an automated data construction pipeline based on it. Leveraging advanced large multimodal models and human-defined rules, we generate 25K text-image preference pairs. Finally, we introduce cross-validation alignment method, which refines data efficiency by organizing semantically analogous samples into mutually comparable pairs. Evaluations on DrawBench demonstrate that InstructEngine improves SD v1.5 and SDXL's performance by 10.53% and 5.30%, outperforming state-of-the-art baselines, with ablation study confirming the benefits of InstructEngine's all components. A win rate of over 50% in human reviews also proves that InstructEngine better aligns with human preferences.
Robot Metabolism: Towards machines that can grow by consuming other machines
Nov 17, 2024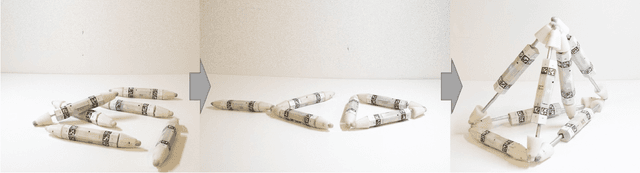
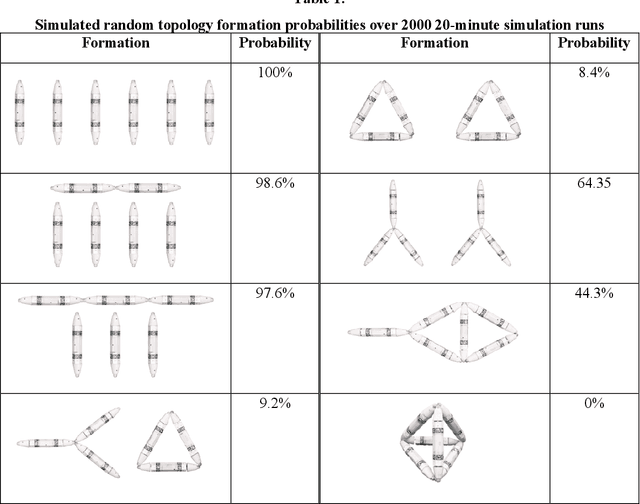
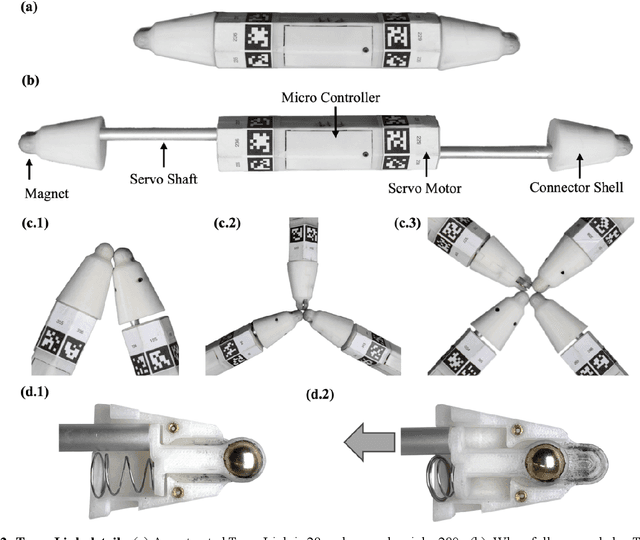
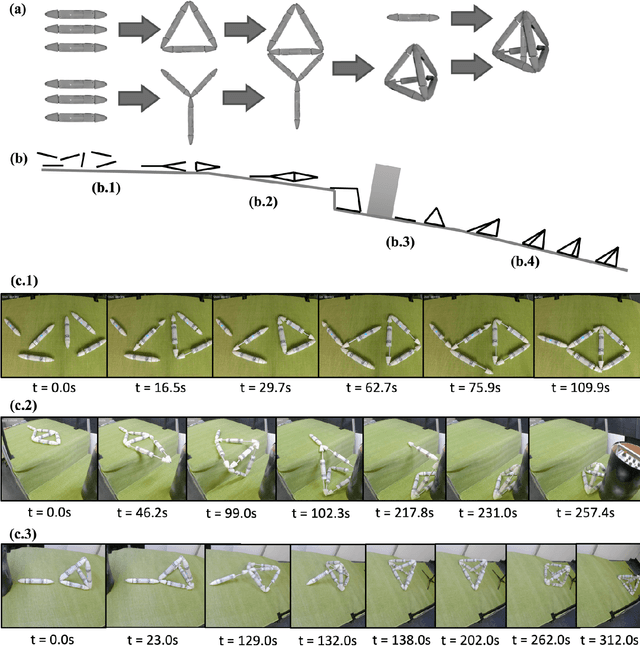
Biological lifeforms can heal, grow, adapt, and reproduce -- abilities essential for sustained survival and development. In contrast, robots today are primarily monolithic machines with limited ability to self-repair, physically develop, or incorporate material from their environments. A key challenge to such physical adaptation has been that while robot minds are rapidly evolving new behaviors through AI, their bodies remain closed systems, unable to systematically integrate new material to grow or heal. We argue that open-ended physical adaptation is only possible when robots are designed using only a small repertoire of simple modules. This allows machines to mechanically adapt by consuming parts from other machines or their surroundings and shedding broken components. We demonstrate this principle using a truss modular robot platform composed of one-dimensional actuated bars. We show how robots in this space can grow bigger, faster, and more capable by consuming materials from their environment and from other robots. We suggest that machine metabolic processes akin to the one demonstrated here will be an essential part of any sustained future robot ecology.
Kwai-STaR: Transform LLMs into State-Transition Reasoners
Nov 07, 2024



Mathematical reasoning presents a significant challenge to the cognitive capabilities of LLMs. Various methods have been proposed to enhance the mathematical ability of LLMs. However, few recognize the value of state transition for LLM reasoning. In this work, we define mathematical problem-solving as a process of transiting from an initial unsolved state to the final resolved state, and propose Kwai-STaR framework, which transforms LLMs into State-Transition Reasoners to improve their intuitive reasoning capabilities. Our approach comprises three main steps: (1) Define the state space tailored to the mathematical reasoning. (2) Generate state-transition data based on the state space. (3) Convert original LLMs into State-Transition Reasoners via a curricular training strategy. Our experiments validate the effectiveness of Kwai-STaR in enhancing mathematical reasoning: After training on the small-scale Kwai-STaR dataset, general LLMs, including Mistral-7B and LLaMA-3, achieve considerable performance gain on the GSM8K and GSM-Hard dataset. Additionally, the state transition-based design endows Kwai-STaR with remarkable training and inference efficiency. Further experiments are underway to establish the generality of Kwai-STaR.
NTIRE 2024 Challenge on Short-form UGC Video Quality Assessment: Methods and Results
Apr 17, 2024



This paper reviews the NTIRE 2024 Challenge on Shortform UGC Video Quality Assessment (S-UGC VQA), where various excellent solutions are submitted and evaluated on the collected dataset KVQ from popular short-form video platform, i.e., Kuaishou/Kwai Platform. The KVQ database is divided into three parts, including 2926 videos for training, 420 videos for validation, and 854 videos for testing. The purpose is to build new benchmarks and advance the development of S-UGC VQA. The competition had 200 participants and 13 teams submitted valid solutions for the final testing phase. The proposed solutions achieved state-of-the-art performances for S-UGC VQA. The project can be found at https://github.com/lixinustc/KVQChallenge-CVPR-NTIRE2024.
Reconfigurable Robot Identification from Motion Data
Mar 15, 2024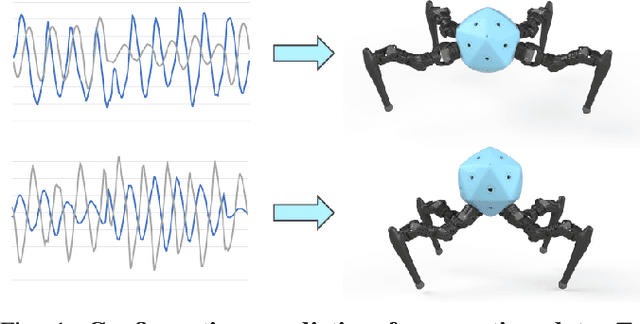
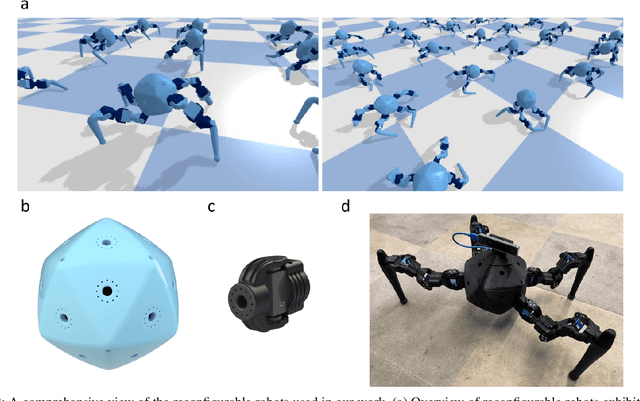
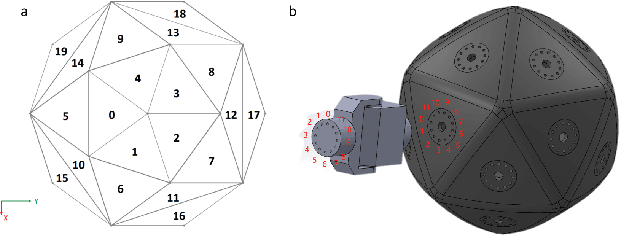
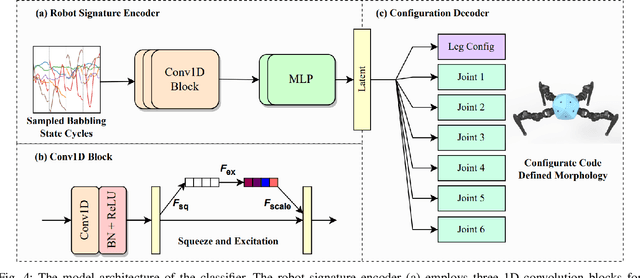
Integrating Large Language Models (VLMs) and Vision-Language Models (VLMs) with robotic systems enables robots to process and understand complex natural language instructions and visual information. However, a fundamental challenge remains: for robots to fully capitalize on these advancements, they must have a deep understanding of their physical embodiment. The gap between AI models cognitive capabilities and the understanding of physical embodiment leads to the following question: Can a robot autonomously understand and adapt to its physical form and functionalities through interaction with its environment? This question underscores the transition towards developing self-modeling robots without reliance on external sensory or pre-programmed knowledge about their structure. Here, we propose a meta self modeling that can deduce robot morphology through proprioception (the internal sense of position and movement). Our study introduces a 12 DoF reconfigurable legged robot, accompanied by a diverse dataset of 200k unique configurations, to systematically investigate the relationship between robotic motion and robot morphology. Utilizing a deep neural network model comprising a robot signature encoder and a configuration decoder, we demonstrate the capability of our system to accurately predict robot configurations from proprioceptive signals. This research contributes to the field of robotic self-modeling, aiming to enhance understanding of their physical embodiment and adaptability in real world scenarios.
Teaching Robots to Build Simulations of Themselves
Nov 20, 2023Simulation enables robots to plan and estimate the outcomes of prospective actions without the need to physically execute them. We introduce a self-supervised learning framework to enable robots model and predict their morphology, kinematics and motor control using only brief raw video data, eliminating the need for extensive real-world data collection and kinematic priors. By observing their own movements, akin to humans watching their reflection in a mirror, robots learn an ability to simulate themselves and predict their spatial motion for various tasks. Our results demonstrate that this self-learned simulation not only enables accurate motion planning but also allows the robot to detect abnormalities and recover from damage.