 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInstructEngine: Instruction-driven Text-to-Image Alignment
Paper and Code
Apr 14, 2025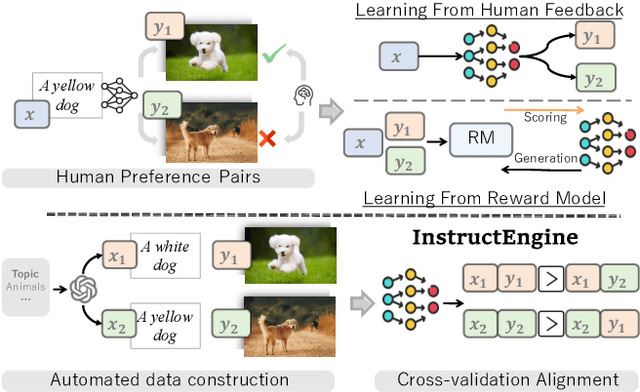
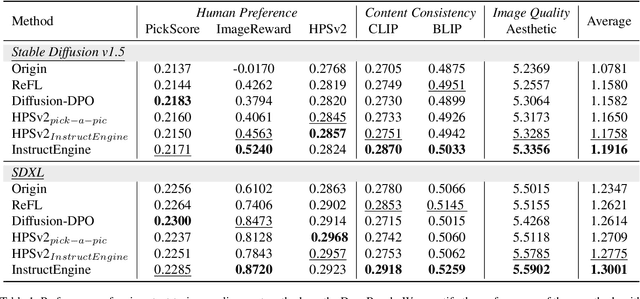

Reinforcement Learning from Human/AI Feedback (RLHF/RLAIF) has been extensively utilized for preference alignment of text-to-image models. Existing methods face certain limitations in terms of both data and algorithm. For training data, most approaches rely on manual annotated preference data, either by directly fine-tuning the generators or by training reward models to provide training signals. However, the high annotation cost makes them difficult to scale up, the reward model consumes extra computation and cannot guarantee accuracy. From an algorithmic perspective, most methods neglect the value of text and only take the image feedback as a comparative signal, which is inefficient and sparse. To alleviate these drawbacks, we propose the InstructEngine framework. Regarding annotation cost, we first construct a taxonomy for text-to-image generation, then develop an automated data construction pipeline based on it. Leveraging advanced large multimodal models and human-defined rules, we generate 25K text-image preference pairs. Finally, we introduce cross-validation alignment method, which refines data efficiency by organizing semantically analogous samples into mutually comparable pairs. Evaluations on DrawBench demonstrate that InstructEngine improves SD v1.5 and SDXL's performance by 10.53% and 5.30%, outperforming state-of-the-art baselines, with ablation study confirming the benefits of InstructEngine's all components. A win rate of over 50% in human reviews also proves that InstructEngine better aligns with human preferences.