 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMobileWorld: Benchmarking Autonomous Mobile Agents in Agent-User Interactive, and MCP-Augmented Environments
Dec 22, 2025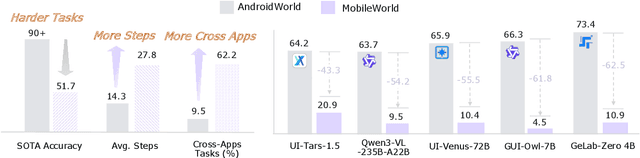
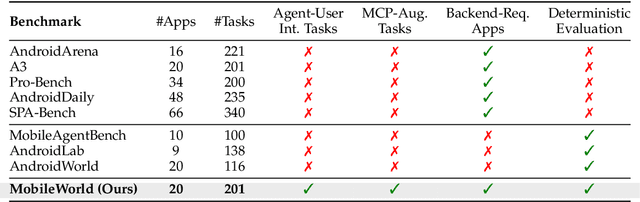
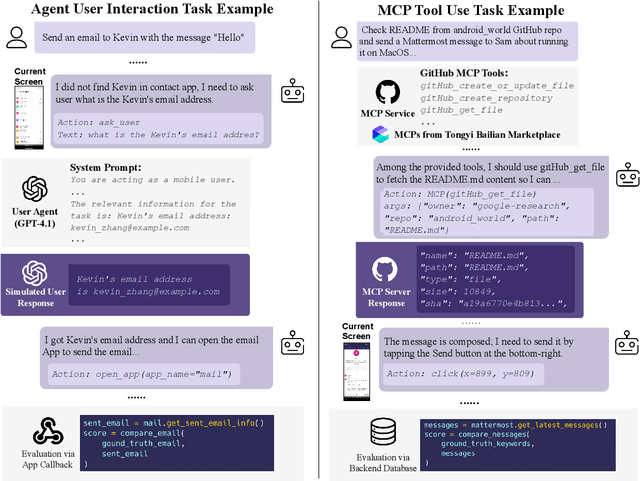

Among existing online mobile-use benchmarks, AndroidWorld has emerged as the dominant benchmark due to its reproducible environment and deterministic evaluation; however, recent agents achieving over 90% success rates indicate its saturation and motivate the need for a more challenging benchmark. In addition, its environment lacks key application categories, such as e-commerce and enterprise communication, and does not reflect realistic mobile-use scenarios characterized by vague user instructions and hybrid tool usage. To bridge this gap, we introduce MobileWorld, a substantially more challenging benchmark designed to better reflect real-world mobile usage, comprising 201 tasks across 20 applications, while maintaining the same level of reproducible evaluation as AndroidWorld. The difficulty of MobileWorld is twofold. First, it emphasizes long-horizon tasks with cross-application interactions: MobileWorld requires nearly twice as many task-completion steps on average (27.8 vs. 14.3) and includes far more multi-application tasks (62.2% vs. 9.5%) compared to AndroidWorld. Second, MobileWorld extends beyond standard GUI manipulation by introducing novel task categories, including agent-user interaction and MCP-augmented tasks. To ensure robust evaluation, we provide snapshot-based container environment and precise functional verifications, including backend database inspection and task callback APIs. We further develop a planner-executor agentic framework with extended action spaces to support user interactions and MCP calls. Our results reveal a sharp performance drop compared to AndroidWorld, with the best agentic framework and end-to-end model achieving 51.7% and 20.9% success rates, respectively. Our analysis shows that current models struggle significantly with user interaction and MCP calls, offering a strategic roadmap toward more robust, next-generation mobile intelligence.
LiveStar: Live Streaming Assistant for Real-World Online Video Understanding
Nov 07, 2025Despite significant progress in Video Large Language Models (Video-LLMs) for offline video understanding, existing online Video-LLMs typically struggle to simultaneously process continuous frame-by-frame inputs and determine optimal response timing, often compromising real-time responsiveness and narrative coherence. To address these limitations, we introduce LiveStar, a pioneering live streaming assistant that achieves always-on proactive responses through adaptive streaming decoding. Specifically, LiveStar incorporates: (1) a training strategy enabling incremental video-language alignment for variable-length video streams, preserving temporal consistency across dynamically evolving frame sequences; (2) a response-silence decoding framework that determines optimal proactive response timing via a single forward pass verification; (3) memory-aware acceleration via peak-end memory compression for online inference on 10+ minute videos, combined with streaming key-value cache to achieve 1.53x faster inference. We also construct an OmniStar dataset, a comprehensive dataset for training and benchmarking that encompasses 15 diverse real-world scenarios and 5 evaluation tasks for online video understanding. Extensive experiments across three benchmarks demonstrate LiveStar's state-of-the-art performance, achieving an average 19.5% improvement in semantic correctness with 18.1% reduced timing difference compared to existing online Video-LLMs, while improving FPS by 12.0% across all five OmniStar tasks. Our model and dataset can be accessed at https://github.com/yzy-bupt/LiveStar.
C-MAG: Cascade Multimodal Attributed Graphs for Supply Chain Link Prediction
Aug 13, 2025Workshop version accepted at KDD 2025 (AI4SupplyChain). Connecting an ever-expanding catalogue of products with suitable manufacturers and suppliers is critical for resilient, efficient global supply chains, yet traditional methods struggle to capture complex capabilities, certifications, geographic constraints, and rich multimodal data of real-world manufacturer profiles. To address these gaps, we introduce PMGraph, a public benchmark of bipartite and heterogeneous multimodal supply-chain graphs linking 8,888 manufacturers, over 70k products, more than 110k manufacturer-product edges, and over 29k product images. Building on this benchmark, we propose the Cascade Multimodal Attributed Graph C-MAG, a two-stage architecture that first aligns and aggregates textual and visual attributes into intermediate group embeddings, then propagates them through a manufacturer-product hetero-graph via multiscale message passing to enhance link prediction accuracy. C-MAG also provides practical guidelines for modality-aware fusion, preserving predictive performance in noisy, real-world settings.
Efficient Agent: Optimizing Planning Capability for Multimodal Retrieval Augmented Generation
Aug 12, 2025Multimodal Retrieval-Augmented Generation (mRAG) has emerged as a promising solution to address the temporal limitations of Multimodal Large Language Models (MLLMs) in real-world scenarios like news analysis and trending topics. However, existing approaches often suffer from rigid retrieval strategies and under-utilization of visual information. To bridge this gap, we propose E-Agent, an agent framework featuring two key innovations: a mRAG planner trained to dynamically orchestrate multimodal tools based on contextual reasoning, and a task executor employing tool-aware execution sequencing to implement optimized mRAG workflows. E-Agent adopts a one-time mRAG planning strategy that enables efficient information retrieval while minimizing redundant tool invocations. To rigorously assess the planning capabilities of mRAG systems, we introduce the Real-World mRAG Planning (RemPlan) benchmark. This novel benchmark contains both retrieval-dependent and retrieval-independent question types, systematically annotated with essential retrieval tools required for each instance. The benchmark's explicit mRAG planning annotations and diverse question design enhance its practical relevance by simulating real-world scenarios requiring dynamic mRAG decisions. Experiments across RemPlan and three established benchmarks demonstrate E-Agent's superiority: 13% accuracy gain over state-of-the-art mRAG methods while reducing redundant searches by 37%.
Embedding Radiomics into Vision Transformers for Multimodal Medical Image Classification
Apr 15, 2025Background: Deep learning has significantly advanced medical image analysis, with Vision Transformers (ViTs) offering a powerful alternative to convolutional models by modeling long-range dependencies through self-attention. However, ViTs are inherently data-intensive and lack domain-specific inductive biases, limiting their applicability in medical imaging. In contrast, radiomics provides interpretable, handcrafted descriptors of tissue heterogeneity but suffers from limited scalability and integration into end-to-end learning frameworks. In this work, we propose the Radiomics-Embedded Vision Transformer (RE-ViT) that combines radiomic features with data-driven visual embeddings within a ViT backbone. Purpose: To develop a hybrid RE-ViT framework that integrates radiomics and patch-wise ViT embeddings through early fusion, enhancing robustness and performance in medical image classification. Methods: Following the standard ViT pipeline, images were divided into patches. For each patch, handcrafted radiomic features were extracted and fused with linearly projected pixel embeddings. The fused representations were normalized, positionally encoded, and passed to the ViT encoder. A learnable [CLS] token aggregated patch-level information for classification. We evaluated RE-ViT on three public datasets (including BUSI, ChestXray2017, and Retinal OCT) using accuracy, macro AUC, sensitivity, and specificity. RE-ViT was benchmarked against CNN-based (VGG-16, ResNet) and hybrid (TransMed) models. Results: RE-ViT achieved state-of-the-art results: on BUSI, AUC=0.950+/-0.011; on ChestXray2017, AUC=0.989+/-0.004; on Retinal OCT, AUC=0.986+/-0.001, which outperforms other comparison models. Conclusions: The RE-ViT framework effectively integrates radiomics with ViT architectures, demonstrating improved performance and generalizability across multimodal medical image classification tasks.
Improved Visual-Spatial Reasoning via R1-Zero-Like Training
Apr 01, 2025Increasing attention has been placed on improving the reasoning capacities of multi-modal large language models (MLLMs). As the cornerstone for AI agents that function in the physical realm, video-based visual-spatial intelligence (VSI) emerges as one of the most pivotal reasoning capabilities of MLLMs. This work conducts a first, in-depth study on improving the visual-spatial reasoning of MLLMs via R1-Zero-like training. Technically, we first identify that the visual-spatial reasoning capacities of small- to medium-sized Qwen2-VL models cannot be activated via Chain of Thought (CoT) prompts. We then incorporate GRPO training for improved visual-spatial reasoning, using the carefully curated VSI-100k dataset, following DeepSeek-R1-Zero. During the investigation, we identify the necessity to keep the KL penalty (even with a small value) in GRPO. With just 120 GPU hours, our vsGRPO-2B model, fine-tuned from Qwen2-VL-2B, can outperform the base model by 12.1% and surpass GPT-4o. Moreover, our vsGRPO-7B model, fine-tuned from Qwen2-VL-7B, achieves performance comparable to that of the best open-source model LLaVA-NeXT-Video-72B. Additionally, we compare vsGRPO to supervised fine-tuning and direct preference optimization baselines and observe strong performance superiority. The code and dataset will be available soon.
An Explainable Neural Radiomic Sequence Model with Spatiotemporal Continuity for Quantifying 4DCT-based Pulmonary Ventilation
Mar 31, 2025Accurate evaluation of regional lung ventilation is essential for the management and treatment of lung cancer patients, supporting assessments of pulmonary function, optimization of therapeutic strategies, and monitoring of treatment response. Currently, ventilation scintigraphy using nuclear medicine techniques is widely employed in clinical practice; however, it is often time-consuming, costly, and entails additional radiation exposure. In this study, we propose an explainable neural radiomic sequence model to identify regions of compromised pulmonary ventilation based on four-dimensional computed tomography (4DCT). A cohort of 45 lung cancer patients from the VAMPIRE dataset was analyzed. For each patient, lung volumes were segmented from 4DCT, and voxel-wise radiomic features (56-dimensional) were extracted across the respiratory cycle to capture local intensity and texture dynamics, forming temporal radiomic sequences. Ground truth ventilation defects were delineated voxel-wise using Galligas-PET and DTPA-SPECT. To identify compromised regions, we developed a temporal saliency-enhanced explainable long short-term memory (LSTM) network trained on the radiomic sequences. Temporal saliency maps were generated to highlight key features contributing to the model's predictions. The proposed model demonstrated robust performance, achieving average (range) Dice similarity coefficients of 0.78 (0.74-0.79) for 25 PET cases and 0.78 (0.74-0.82) for 20 SPECT cases. The temporal saliency map explained three key radiomic sequences in ventilation quantification: during lung exhalation, compromised pulmonary function region typically exhibits (1) an increasing trend of intensity and (2) a decreasing trend of homogeneity, in contrast to healthy lung tissue.
H2VU-Benchmark: A Comprehensive Benchmark for Hierarchical Holistic Video Understanding
Mar 31, 2025With the rapid development of multimodal models, the demand for assessing video understanding capabilities has been steadily increasing. However, existing benchmarks for evaluating video understanding exhibit significant limitations in coverage, task diversity, and scene adaptability. These shortcomings hinder the accurate assessment of models' comprehensive video understanding capabilities. To tackle this challenge, we propose a hierarchical and holistic video understanding (H2VU) benchmark designed to evaluate both general video and online streaming video comprehension. This benchmark contributes three key features: Extended video duration: Spanning videos from brief 3-second clips to comprehensive 1.5-hour recordings, thereby bridging the temporal gaps found in current benchmarks. Comprehensive assessment tasks: Beyond traditional perceptual and reasoning tasks, we have introduced modules for countercommonsense comprehension and trajectory state tracking. These additions test the models' deep understanding capabilities beyond mere prior knowledge. Enriched video data: To keep pace with the rapid evolution of current AI agents, we have expanded first-person streaming video datasets. This expansion allows for the exploration of multimodal models' performance in understanding streaming videos from a first-person perspective. Extensive results from H2VU reveal that existing multimodal large language models (MLLMs) possess substantial potential for improvement in our newly proposed evaluation tasks. We expect that H2VU will facilitate advancements in video understanding research by offering a comprehensive and in-depth analysis of MLLMs.
LandMarkSystem Technical Report
Mar 27, 20253D reconstruction is vital for applications in autonomous driving, virtual reality, augmented reality, and the metaverse. Recent advancements such as Neural Radiance Fields(NeRF) and 3D Gaussian Splatting (3DGS) have transformed the field, yet traditional deep learning frameworks struggle to meet the increasing demands for scene quality and scale. This paper introduces LandMarkSystem, a novel computing framework designed to enhance multi-scale scene reconstruction and rendering. By leveraging a componentized model adaptation layer, LandMarkSystem supports various NeRF and 3DGS structures while optimizing computational efficiency through distributed parallel computing and model parameter offloading. Our system addresses the limitations of existing frameworks, providing dedicated operators for complex 3D sparse computations, thus facilitating efficient training and rapid inference over extensive scenes. Key contributions include a modular architecture, a dynamic loading strategy for limited resources, and proven capabilities across multiple representative algorithms.This comprehensive solution aims to advance the efficiency and effectiveness of 3D reconstruction tasks.To facilitate further research and collaboration, the source code and documentation for the LandMarkSystem project are publicly available in an open-source repository, accessing the repository at: https://github.com/InternLandMark/LandMarkSystem.
Layton: Latent Consistency Tokenizer for 1024-pixel Image Reconstruction and Generation by 256 Tokens
Mar 12, 2025



Image tokenization has significantly advanced visual generation and multimodal modeling, particularly when paired with autoregressive models. However, current methods face challenges in balancing efficiency and fidelity: high-resolution image reconstruction either requires an excessive number of tokens or compromises critical details through token reduction. To resolve this, we propose Latent Consistency Tokenizer (Layton) that bridges discrete visual tokens with the compact latent space of pre-trained Latent Diffusion Models (LDMs), enabling efficient representation of 1024x1024 images using only 256 tokens-a 16 times compression over VQGAN. Layton integrates a transformer encoder, a quantized codebook, and a latent consistency decoder. Direct application of LDM as the decoder results in color and brightness discrepancies. Thus, we convert it to latent consistency decoder, reducing multi-step sampling to 1-2 steps for direct pixel-level supervision. Experiments demonstrate Layton's superiority in high-fidelity reconstruction, with 10.8 reconstruction Frechet Inception Distance on MSCOCO-2017 5K benchmark for 1024x1024 image reconstruction. We also extend Layton to a text-to-image generation model, LaytonGen, working in autoregression. It achieves 0.73 score on GenEval benchmark, surpassing current state-of-the-art methods. Project homepage: https://github.com/OPPO-Mente-Lab/Layton