 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen Models Judge Themselves: Unsupervised Self-Evolution for Multimodal Reasoning
Mar 22, 2026Recent progress in multimodal large language models has led to strong performance on reasoning tasks, but these improvements largely rely on high-quality annotated data or teacher-model distillation, both of which are costly and difficult to scale.To address this, we propose an unsupervised self-evolution training framework for multimodal reasoning that achieves stable performance improvements without using human-annotated answers or external reward models. For each input, we sample multiple reasoning trajectories and jointly model their within group structure.We use the Actor's self-consistency signal as a training prior, and introduce a bounded Judge based modulation to continuously reweight trajectories of different quality.We further model the modulated scores as a group level distribution and convert absolute scores into relative advantages within each group, enabling more robust policy updates. Trained with Group Relative Policy Optimization (GRPO) on unlabeled data, our method consistently improves reasoning performance and generalization on five mathematical reasoning benchmarks, offering a scalable path toward self-evolving multimodal models.The code are available at https://dingwu1021.github.io/SelfJudge/.
Binary Neural Networks for Large Language Model: A Survey
Feb 26, 2025Large language models (LLMs) have wide applications in the field of natural language processing(NLP), such as GPT-4 and Llama. However, with the exponential growth of model parameter sizes, LLMs bring significant resource overheads. Low-bit quantization, as a key technique, reduces memory usage and computational demands by decreasing the bit-width of model parameters, activations, and gradients. Previous quantization methods for LLMs have largely employed Post-Training Quantization (PTQ) and Quantization-Aware Training (QAT). PTQ does not require any retraining of the original model, while QAT involves optimizing precision during training to achieve the best quantization parameters. The BitNet team proposed a radically different approach, where quantization is performed from the start of model training, utilizing low-precision binary weights during the training process. This approach has led to the emergence of many binary quantization techniques for large language models. This paper provides a comprehensive review of these binary quantization techniques. Specifically, we will introduce binary quantization techniques in deep neural networks and further explore their application to LLMs, reviewing their various contributions, implementations, and applications.
A Knowledge-Injected Curriculum Pretraining Framework for Question Answering
Mar 11, 2024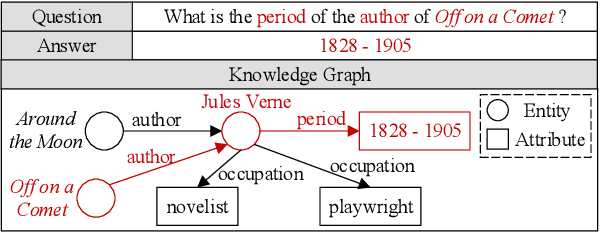
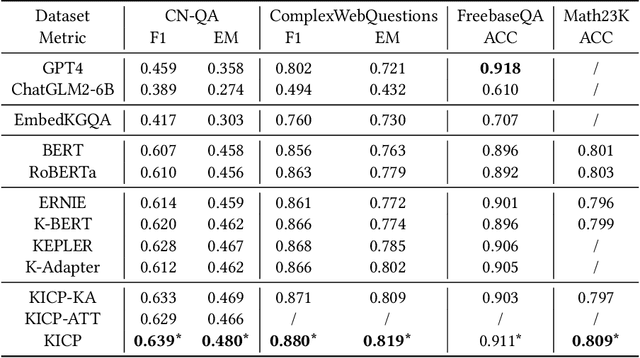
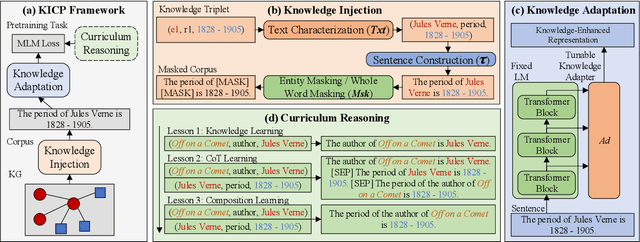
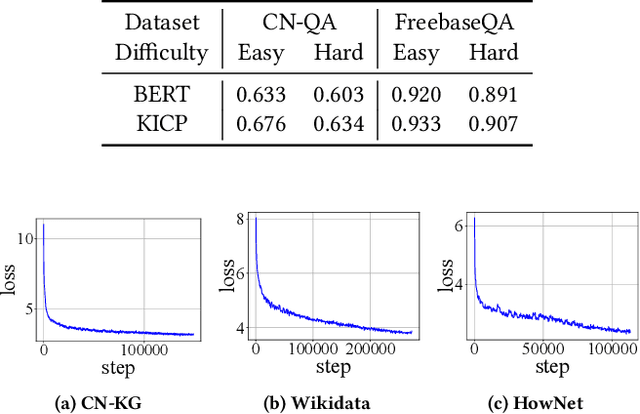
Knowledge-based question answering (KBQA) is a key task in NLP research, and also an approach to access the web data and knowledge, which requires exploiting knowledge graphs (KGs) for reasoning. In the literature, one promising solution for KBQA is to incorporate the pretrained language model (LM) with KGs by generating KG-centered pretraining corpus, which has shown its superiority. However, these methods often depend on specific techniques and resources to work, which may not always be available and restrict its application. Moreover, existing methods focus more on improving language understanding with KGs, while neglect the more important human-like complex reasoning. To this end, in this paper, we propose a general Knowledge-Injected Curriculum Pretraining framework (KICP) to achieve comprehensive KG learning and exploitation for KBQA tasks, which is composed of knowledge injection (KI), knowledge adaptation (KA) and curriculum reasoning (CR). Specifically, the KI module first injects knowledge into the LM by generating KG-centered pretraining corpus, and generalizes the process into three key steps that could work with different implementations for flexible application. Next, the KA module learns knowledge from the generated corpus with LM equipped with an adapter as well as keeps its original natural language understanding ability to reduce the negative impacts of the difference between the generated and natural corpus. Last, to enable the LM with complex reasoning, the CR module follows human reasoning patterns to construct three corpora with increasing difficulties of reasoning, and further trains the LM from easy to hard in a curriculum manner. We provide an implementation of the general framework, and evaluate the proposed KICP on four real-word datasets. The results demonstrate that our framework can achieve higher performances.
Predict Emoji Combination with Retrieval Strategy
Aug 21, 2019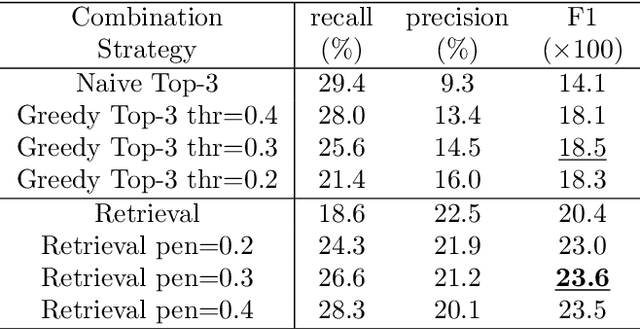

As emojis are widely used in social media, people not only use an emoji to express their emotions or mention things but also extend its usage to represent complicate emotions, concepts or activities by combining multiple emojis. In this work, we study how emoji combination, a consecutive emoji sequence, is used like a new language. We propose a novel algorithm called Retrieval Strategy to predict what emoji combination follows given a short text as context. Our algorithm treats emoji combinations as phrase in language, ranking sets of emoji combinations like retrieving words from dictionary. We show that our algorithm largely improves the F1 score from 0.141 to 0.204 on emoji combination prediction task.