 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQianfanHuijin Technical Report: A Novel Multi-Stage Training Paradigm for Finance Industrial LLMs
Dec 30, 2025Domain-specific enhancement of Large Language Models (LLMs) within the financial context has long been a focal point of industrial application. While previous models such as BloombergGPT and Baichuan-Finance primarily focused on knowledge enhancement, the deepening complexity of financial services has driven a growing demand for models that possess not only domain knowledge but also robust financial reasoning and agentic capabilities. In this paper, we present QianfanHuijin, a financial domain LLM, and propose a generalizable multi-stage training paradigm for industrial model enhancement. Our approach begins with Continual Pre-training (CPT) on financial corpora to consolidate the knowledge base. This is followed by a fine-grained Post-training pipeline designed with increasing specificity: starting with Financial SFT, progressing to Finance Reasoning RL and Finance Agentic RL, and culminating in General RL aligned with real-world business scenarios. Empirical results demonstrate that QianfanHuijin achieves superior performance across various authoritative financial benchmarks. Furthermore, ablation studies confirm that the targeted Reasoning RL and Agentic RL stages yield significant gains in their respective capabilities. These findings validate our motivation and suggest that this fine-grained, progressive post-training methodology is poised to become a mainstream paradigm for various industrial-enhanced LLMs.
The FM Agent
Oct 30, 2025Large language models (LLMs) are catalyzing the development of autonomous AI research agents for scientific and engineering discovery. We present FM Agent, a novel and general-purpose multi-agent framework that leverages a synergistic combination of LLM-based reasoning and large-scale evolutionary search to address complex real-world challenges. The core of FM Agent integrates several key innovations: 1) a cold-start initialization phase incorporating expert guidance, 2) a novel evolutionary sampling strategy for iterative optimization, 3) domain-specific evaluators that combine correctness, effectiveness, and LLM-supervised feedback, and 4) a distributed, asynchronous execution infrastructure built on Ray. Demonstrating broad applicability, our system has been evaluated across diverse domains, including operations research, machine learning, GPU kernel optimization, and classical mathematical problems. FM Agent reaches state-of-the-art results autonomously, without human interpretation or tuning -- 1976.3 on ALE-Bench (+5.2\%), 43.56\% on MLE-Bench (+4.0pp), up to 20x speedups on KernelBench, and establishes new state-of-the-art(SOTA) results on several classical mathematical problems. Beyond academic benchmarks, FM Agent shows considerable promise for both large-scale enterprise R\&D workflows and fundamental scientific research, where it can accelerate innovation, automate complex discovery processes, and deliver substantial engineering and scientific advances with broader societal impact.
TagRouter: Learning Route to LLMs through Tags for Open-Domain Text Generation Tasks
Jun 14, 2025Model routing allocates queries to the suitable model, improving system performance while reducing costs. However, existing routing methods face practical limitations that hinder scalability in large-scale applications and struggle to keep up with the rapid growth of the large language model (LLM) ecosystem. To tackle these challenges, we propose TagRouter, a training-free model routing method designed to optimize the synergy among multiple LLMs for open-domain text generation tasks. Experimental results demonstrate that TagRouter outperforms 13 baseline methods, increasing the accept rate of system by 6.15% and reducing costs by 17.20%, achieving optimal cost-efficiency. Our findings provides the LLM community with an efficient and scalable solution for model ensembling, offering users an evolvable "super model."
Virtual ID Discovery from E-commerce Media at Alibaba: Exploiting Richness of User Click Behavior for Visual Search Relevance
Feb 09, 2021

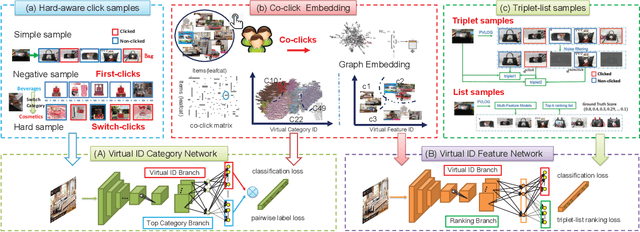

Visual search plays an essential role for E-commerce. To meet the search demands of users and promote shopping experience at Alibaba, visual search relevance of real-shot images is becoming the bottleneck. Traditional visual search paradigm is usually based upon supervised learning with labeled data. However, large-scale categorical labels are required with expensive human annotations, which limits its applicability and also usually fails in distinguishing the real-shot images. In this paper, we propose to discover Virtual ID from user click behavior to improve visual search relevance at Alibaba. As a totally click-data driven approach, we collect various types of click data for training deep networks without any human annotations at all. In particular, Virtual ID are learned as classification supervision with co-click embedding, which explores image relationship from user co-click behaviors to guide category prediction and feature learning. Concretely, we deploy Virtual ID Category Network by integrating first-clicks and switch-clicks as regularizer. Incorporating triplets and list constraints, Virtual ID Feature Network is trained in a joint classification and ranking manner. Benefiting from exploration of user click data, our networks are more effective to encode richer supervision and better distinguish real-shot images in terms of category and feature. To validate our method for visual search relevance, we conduct an extensive set of offline and online experiments on the collected real-shot images. We consistently achieve better experimental results across all components, compared with alternative and state-of-the-art methods.
* accepted by CIKM 2019
Predict Emoji Combination with Retrieval Strategy
Aug 21, 2019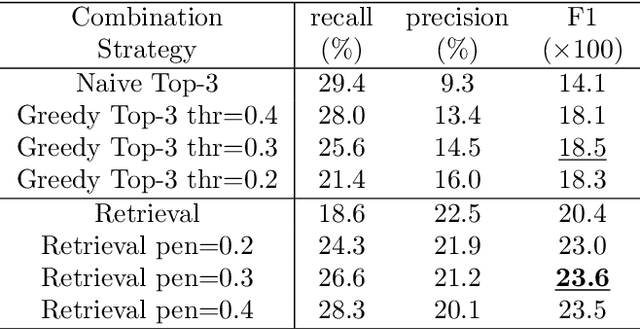

As emojis are widely used in social media, people not only use an emoji to express their emotions or mention things but also extend its usage to represent complicate emotions, concepts or activities by combining multiple emojis. In this work, we study how emoji combination, a consecutive emoji sequence, is used like a new language. We propose a novel algorithm called Retrieval Strategy to predict what emoji combination follows given a short text as context. Our algorithm treats emoji combinations as phrase in language, ranking sets of emoji combinations like retrieving words from dictionary. We show that our algorithm largely improves the F1 score from 0.141 to 0.204 on emoji combination prediction task.