 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSTAPO: Stabilizing Reinforcement Learning for LLMs by Silencing Rare Spurious Tokens
Feb 17, 2026Reinforcement Learning (RL) has significantly improved large language model reasoning, but existing RL fine-tuning methods rely heavily on heuristic techniques such as entropy regularization and reweighting to maintain stability. In practice, they often experience late-stage performance collapse, leading to degraded reasoning quality and unstable training. We derive that the magnitude of token-wise policy gradients in RL is negatively correlated with token probability and local policy entropy. Building on this result, we prove that training instability is driven by a tiny fraction of tokens, approximately 0.01\%, which we term \emph{spurious tokens}. When such tokens appear in correct responses, they contribute little to the reasoning outcome but inherit the full sequence-level reward, leading to abnormally amplified gradient updates. Motivated by this observation, we propose Spurious-Token-Aware Policy Optimization (STAPO) for large-scale model refining, which selectively masks such updates and renormalizes the loss over valid tokens. Across six mathematical reasoning benchmarks using Qwen 1.7B, 8B, and 14B base models, STAPO consistently demonstrates superior entropy stability and achieves an average performance improvement of 7.13\% over GRPO, 20-Entropy and JustRL.
Nimbus: A Unified Embodied Synthetic Data Generation Framework
Jan 29, 2026Scaling data volume and diversity is critical for generalizing embodied intelligence. While synthetic data generation offers a scalable alternative to expensive physical data acquisition, existing pipelines remain fragmented and task-specific. This isolation leads to significant engineering inefficiency and system instability, failing to support the sustained, high-throughput data generation required for foundation model training. To address these challenges, we present Nimbus, a unified synthetic data generation framework designed to integrate heterogeneous navigation and manipulation pipelines. Nimbus introduces a modular four-layer architecture featuring a decoupled execution model that separates trajectory planning, rendering, and storage into asynchronous stages. By implementing dynamic pipeline scheduling, global load balancing, distributed fault tolerance, and backend-specific rendering optimizations, the system maximizes resource utilization across CPU, GPU, and I/O resources. Our evaluation demonstrates that Nimbus achieves a 2-3X improvement in end-to-end throughput compared to unoptimized baselines and ensuring robust, long-term operation in large-scale distributed environments. This framework serves as the production backbone for the InternData suite, enabling seamless cross-domain data synthesis.
InternVLA-A1: Unifying Understanding, Generation and Action for Robotic Manipulation
Jan 05, 2026Prevalent Vision-Language-Action (VLA) models are typically built upon Multimodal Large Language Models (MLLMs) and demonstrate exceptional proficiency in semantic understanding, but they inherently lack the capability to deduce physical world dynamics. Consequently, recent approaches have shifted toward World Models, typically formulated via video prediction; however, these methods often suffer from a lack of semantic grounding and exhibit brittleness when handling prediction errors. To synergize semantic understanding with dynamic predictive capabilities, we present InternVLA-A1. This model employs a unified Mixture-of-Transformers architecture, coordinating three experts for scene understanding, visual foresight generation, and action execution. These components interact seamlessly through a unified masked self-attention mechanism. Building upon InternVL3 and Qwen3-VL, we instantiate InternVLA-A1 at 2B and 3B parameter scales. We pre-train these models on hybrid synthetic-real datasets spanning InternData-A1 and Agibot-World, covering over 533M frames. This hybrid training strategy effectively harnesses the diversity of synthetic simulation data while minimizing the sim-to-real gap. We evaluated InternVLA-A1 across 12 real-world robotic tasks and simulation benchmark. It significantly outperforms leading models like pi0 and GR00T N1.5, achieving a 14.5\% improvement in daily tasks and a 40\%-73.3\% boost in dynamic settings, such as conveyor belt sorting.
LandMarkSystem Technical Report
Mar 27, 20253D reconstruction is vital for applications in autonomous driving, virtual reality, augmented reality, and the metaverse. Recent advancements such as Neural Radiance Fields(NeRF) and 3D Gaussian Splatting (3DGS) have transformed the field, yet traditional deep learning frameworks struggle to meet the increasing demands for scene quality and scale. This paper introduces LandMarkSystem, a novel computing framework designed to enhance multi-scale scene reconstruction and rendering. By leveraging a componentized model adaptation layer, LandMarkSystem supports various NeRF and 3DGS structures while optimizing computational efficiency through distributed parallel computing and model parameter offloading. Our system addresses the limitations of existing frameworks, providing dedicated operators for complex 3D sparse computations, thus facilitating efficient training and rapid inference over extensive scenes. Key contributions include a modular architecture, a dynamic loading strategy for limited resources, and proven capabilities across multiple representative algorithms.This comprehensive solution aims to advance the efficiency and effectiveness of 3D reconstruction tasks.To facilitate further research and collaboration, the source code and documentation for the LandMarkSystem project are publicly available in an open-source repository, accessing the repository at: https://github.com/InternLandMark/LandMarkSystem.
GS-Cache: A GS-Cache Inference Framework for Large-scale Gaussian Splatting Models
Feb 20, 2025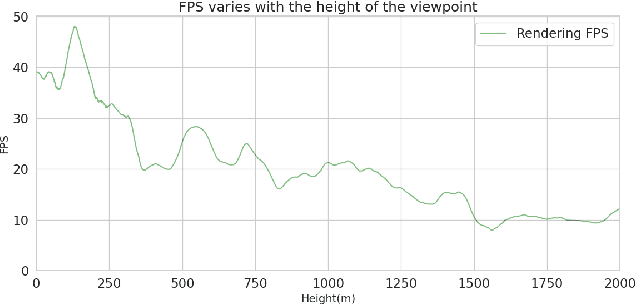
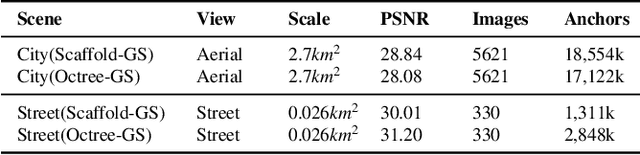
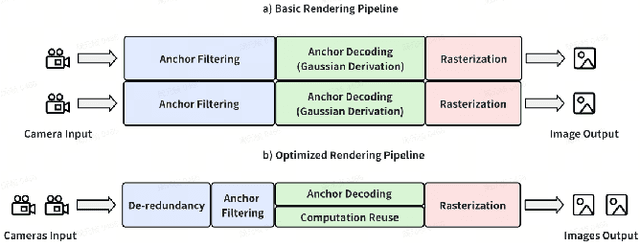
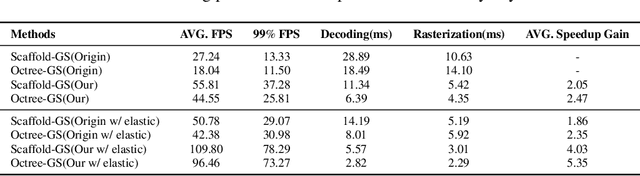
Rendering large-scale 3D Gaussian Splatting (3DGS) model faces significant challenges in achieving real-time, high-fidelity performance on consumer-grade devices. Fully realizing the potential of 3DGS in applications such as virtual reality (VR) requires addressing critical system-level challenges to support real-time, immersive experiences. We propose GS-Cache, an end-to-end framework that seamlessly integrates 3DGS's advanced representation with a highly optimized rendering system. GS-Cache introduces a cache-centric pipeline to eliminate redundant computations, an efficiency-aware scheduler for elastic multi-GPU rendering, and optimized CUDA kernels to overcome computational bottlenecks. This synergy between 3DGS and system design enables GS-Cache to achieve up to 5.35x performance improvement, 35% latency reduction, and 42% lower GPU memory usage, supporting 2K binocular rendering at over 120 FPS with high visual quality. By bridging the gap between 3DGS's representation power and the demands of VR systems, GS-Cache establishes a scalable and efficient framework for real-time neural rendering in immersive environments.
What Color Scheme is More Effective in Assisting Readers to Locate Information in a Color-Coded Article?
Aug 12, 2024
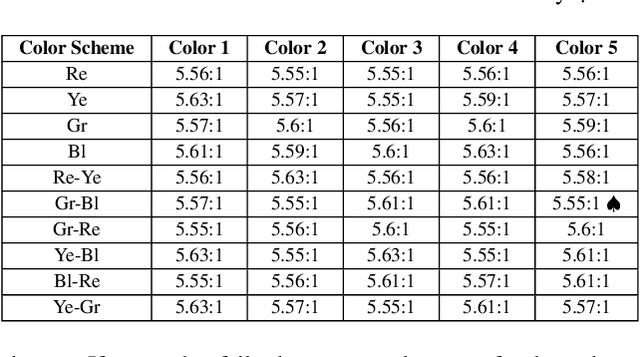
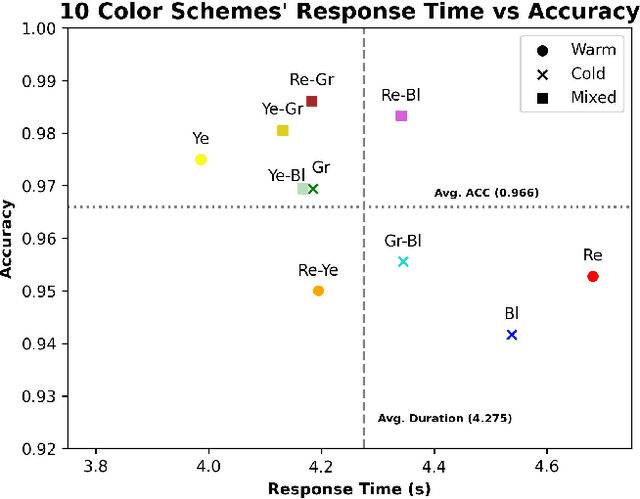
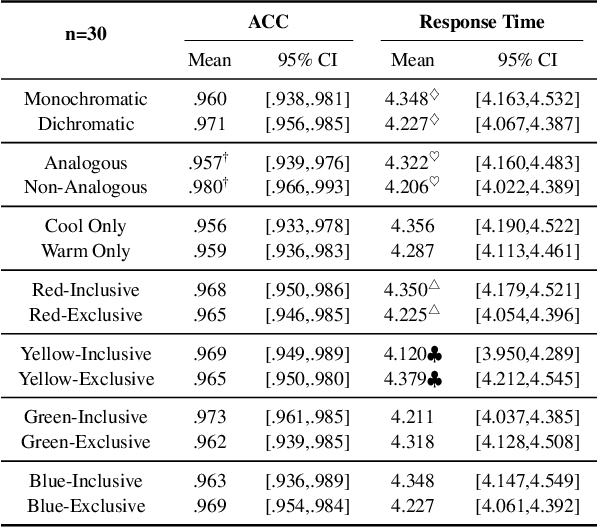
Color coding, a technique assigning specific colors to cluster information types, has proven advantages in aiding human cognitive activities, especially reading and comprehension. The rise of Large Language Models (LLMs) has streamlined document coding, enabling simple automatic text labeling with various schemes. This has the potential to make color-coding more accessible and benefit more users. However, the impact of color choice on information seeking is understudied. We conducted a user study assessing various color schemes' effectiveness in LLM-coded text documents, standardizing contrast ratios to approximately 5.55:1 across schemes. Participants performed timed information-seeking tasks in color-coded scholarly abstracts. Results showed non-analogous and yellow-inclusive color schemes improved performance, with the latter also being more preferred by participants. These findings can inform better color scheme choices for text annotation. As LLMs advance document coding, we advocate for more research focusing on the "color" aspect of color-coding techniques.
Convolutional Bayesian Filtering
Mar 30, 2024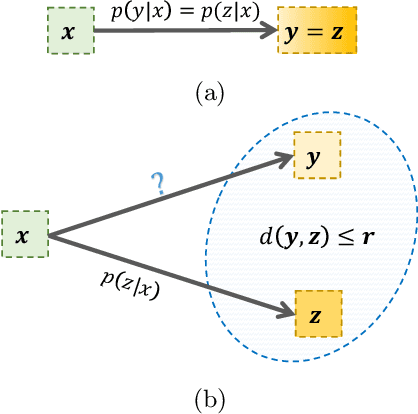
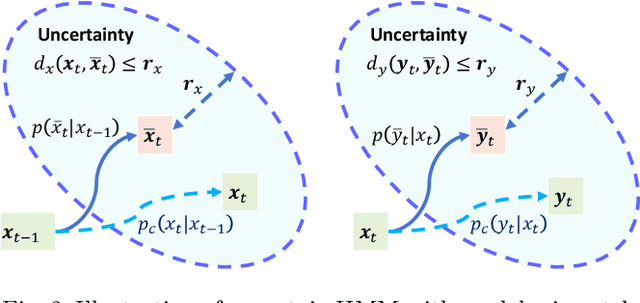
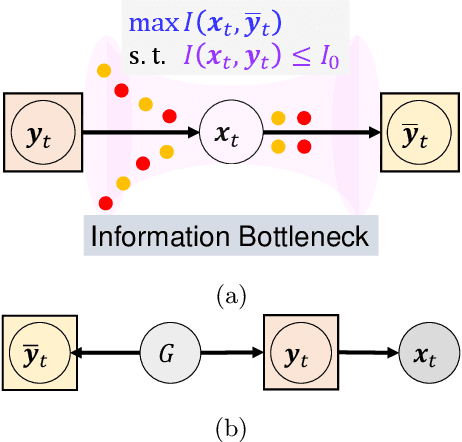
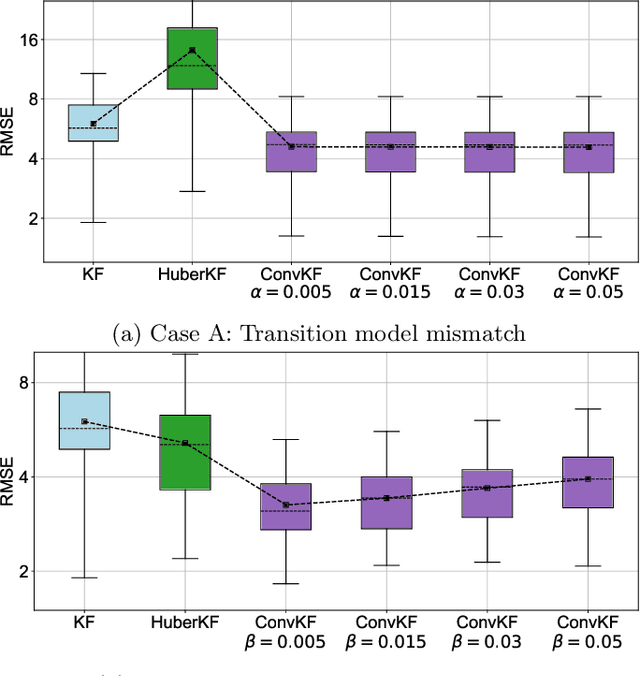
Bayesian filtering serves as the mainstream framework of state estimation in dynamic systems. Its standard version utilizes total probability rule and Bayes' law alternatively, where how to define and compute conditional probability is critical to state distribution inference. Previously, the conditional probability is assumed to be exactly known, which represents a measure of the occurrence probability of one event, given the second event. In this paper, we find that by adding an additional event that stipulates an inequality condition, we can transform the conditional probability into a special integration that is analogous to convolution. Based on this transformation, we show that both transition probability and output probability can be generalized to convolutional forms, resulting in a more general filtering framework that we call convolutional Bayesian filtering. This new framework encompasses standard Bayesian filtering as a special case when the distance metric of the inequality condition is selected as Dirac delta function. It also allows for a more nuanced consideration of model mismatch by choosing different types of inequality conditions. For instance, when the distance metric is defined in a distributional sense, the transition probability and output probability can be approximated by simply rescaling them into fractional powers. Under this framework, a robust version of Kalman filter can be constructed by only altering the noise covariance matrix, while maintaining the conjugate nature of Gaussian distributions. Finally, we exemplify the effectiveness of our approach by reshaping classic filtering algorithms into convolutional versions, including Kalman filter, extended Kalman filter, unscented Kalman filter and particle filter.
If in a Crowdsourced Data Annotation Pipeline, a GPT-4
Feb 26, 2024



Recent studies indicated GPT-4 outperforms online crowd workers in data labeling accuracy, notably workers from Amazon Mechanical Turk (MTurk). However, these studies were criticized for deviating from standard crowdsourcing practices and emphasizing individual workers' performances over the whole data-annotation process. This paper compared GPT-4 and an ethical and well-executed MTurk pipeline, with 415 workers labeling 3,177 sentence segments from 200 scholarly articles using the CODA-19 scheme. Two worker interfaces yielded 127,080 labels, which were then used to infer the final labels through eight label-aggregation algorithms. Our evaluation showed that despite best practices, MTurk pipeline's highest accuracy was 81.5%, whereas GPT-4 achieved 83.6%. Interestingly, when combining GPT-4's labels with crowd labels collected via an advanced worker interface for aggregation, 2 out of the 8 algorithms achieved an even higher accuracy (87.5%, 87.0%). Further analysis suggested that, when the crowd's and GPT-4's labeling strengths are complementary, aggregating them could increase labeling accuracy.
Adversarial Batch Inverse Reinforcement Learning: Learn to Reward from Imperfect Demonstration for Interactive Recommendation
Oct 30, 2023Rewards serve as a measure of user satisfaction and act as a limiting factor in interactive recommender systems. In this research, we focus on the problem of learning to reward (LTR), which is fundamental to reinforcement learning. Previous approaches either introduce additional procedures for learning to reward, thereby increasing the complexity of optimization, or assume that user-agent interactions provide perfect demonstrations, which is not feasible in practice. Ideally, we aim to employ a unified approach that optimizes both the reward and policy using compositional demonstrations. However, this requirement presents a challenge since rewards inherently quantify user feedback on-policy, while recommender agents approximate off-policy future cumulative valuation. To tackle this challenge, we propose a novel batch inverse reinforcement learning paradigm that achieves the desired properties. Our method utilizes discounted stationary distribution correction to combine LTR and recommender agent evaluation. To fulfill the compositional requirement, we incorporate the concept of pessimism through conservation. Specifically, we modify the vanilla correction using Bellman transformation and enforce KL regularization to constrain consecutive policy updates. We use two real-world datasets which represent two compositional coverage to conduct empirical studies, the results also show that the proposed method relatively improves both effectiveness (2.3\%) and efficiency (11.53\%)
Classifying Crime Types using Judgment Documents from Social Media
Jun 29, 2023
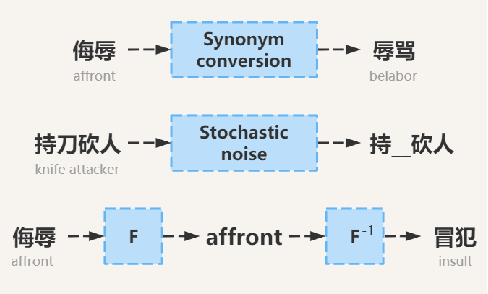
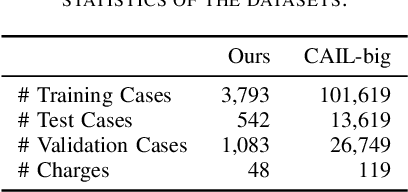
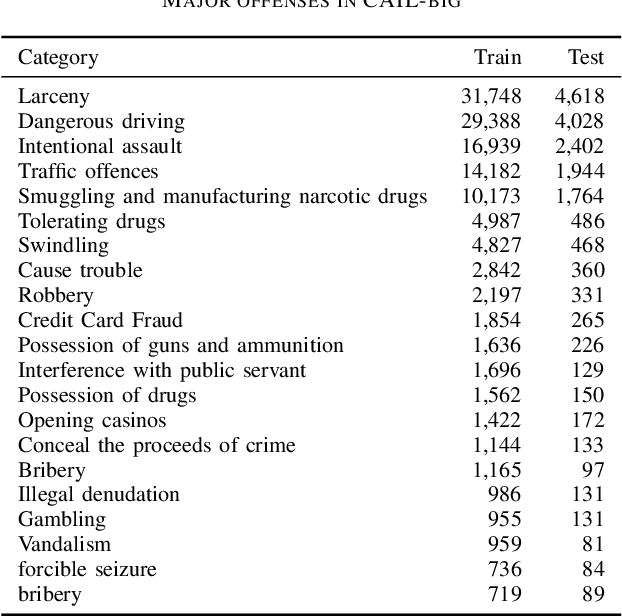
The task of determining crime types based on criminal behavior facts has become a very important and meaningful task in social science. But the problem facing the field now is that the data samples themselves are unevenly distributed, due to the nature of the crime itself. At the same time, data sets in the judicial field are less publicly available, and it is not practical to produce large data sets for direct training. This article proposes a new training model to solve this problem through NLP processing methods. We first propose a Crime Fact Data Preprocessing Module (CFDPM), which can balance the defects of uneven data set distribution by generating new samples. Then we use a large open source dataset (CAIL-big) as our pretraining dataset and a small dataset collected by ourselves for Fine-tuning, giving it good generalization ability to unfamiliar small datasets. At the same time, we use the improved Bert model with dynamic masking to improve the model. Experiments show that the proposed method achieves state-of-the-art results on the present dataset. At the same time, the effectiveness of module CFDPM is proved by experiments. This article provides a valuable methodology contribution for classifying social science texts such as criminal behaviors. Extensive experiments on public benchmarks show that the proposed method achieves new state-of-the-art results.