 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmbedding Radiomics into Vision Transformers for Multimodal Medical Image Classification
Apr 15, 2025Background: Deep learning has significantly advanced medical image analysis, with Vision Transformers (ViTs) offering a powerful alternative to convolutional models by modeling long-range dependencies through self-attention. However, ViTs are inherently data-intensive and lack domain-specific inductive biases, limiting their applicability in medical imaging. In contrast, radiomics provides interpretable, handcrafted descriptors of tissue heterogeneity but suffers from limited scalability and integration into end-to-end learning frameworks. In this work, we propose the Radiomics-Embedded Vision Transformer (RE-ViT) that combines radiomic features with data-driven visual embeddings within a ViT backbone. Purpose: To develop a hybrid RE-ViT framework that integrates radiomics and patch-wise ViT embeddings through early fusion, enhancing robustness and performance in medical image classification. Methods: Following the standard ViT pipeline, images were divided into patches. For each patch, handcrafted radiomic features were extracted and fused with linearly projected pixel embeddings. The fused representations were normalized, positionally encoded, and passed to the ViT encoder. A learnable [CLS] token aggregated patch-level information for classification. We evaluated RE-ViT on three public datasets (including BUSI, ChestXray2017, and Retinal OCT) using accuracy, macro AUC, sensitivity, and specificity. RE-ViT was benchmarked against CNN-based (VGG-16, ResNet) and hybrid (TransMed) models. Results: RE-ViT achieved state-of-the-art results: on BUSI, AUC=0.950+/-0.011; on ChestXray2017, AUC=0.989+/-0.004; on Retinal OCT, AUC=0.986+/-0.001, which outperforms other comparison models. Conclusions: The RE-ViT framework effectively integrates radiomics with ViT architectures, demonstrating improved performance and generalizability across multimodal medical image classification tasks.
An Explainable Neural Radiomic Sequence Model with Spatiotemporal Continuity for Quantifying 4DCT-based Pulmonary Ventilation
Mar 31, 2025Accurate evaluation of regional lung ventilation is essential for the management and treatment of lung cancer patients, supporting assessments of pulmonary function, optimization of therapeutic strategies, and monitoring of treatment response. Currently, ventilation scintigraphy using nuclear medicine techniques is widely employed in clinical practice; however, it is often time-consuming, costly, and entails additional radiation exposure. In this study, we propose an explainable neural radiomic sequence model to identify regions of compromised pulmonary ventilation based on four-dimensional computed tomography (4DCT). A cohort of 45 lung cancer patients from the VAMPIRE dataset was analyzed. For each patient, lung volumes were segmented from 4DCT, and voxel-wise radiomic features (56-dimensional) were extracted across the respiratory cycle to capture local intensity and texture dynamics, forming temporal radiomic sequences. Ground truth ventilation defects were delineated voxel-wise using Galligas-PET and DTPA-SPECT. To identify compromised regions, we developed a temporal saliency-enhanced explainable long short-term memory (LSTM) network trained on the radiomic sequences. Temporal saliency maps were generated to highlight key features contributing to the model's predictions. The proposed model demonstrated robust performance, achieving average (range) Dice similarity coefficients of 0.78 (0.74-0.79) for 25 PET cases and 0.78 (0.74-0.82) for 20 SPECT cases. The temporal saliency map explained three key radiomic sequences in ventilation quantification: during lung exhalation, compromised pulmonary function region typically exhibits (1) an increasing trend of intensity and (2) a decreasing trend of homogeneity, in contrast to healthy lung tissue.
Synthetic Poisoning Attacks: The Impact of Poisoned MRI Image on U-Net Brain Tumor Segmentation
Feb 06, 2025Deep learning-based medical image segmentation models, such as U-Net, rely on high-quality annotated datasets to achieve accurate predictions. However, the increasing use of generative models for synthetic data augmentation introduces potential risks, particularly in the absence of rigorous quality control. In this paper, we investigate the impact of synthetic MRI data on the robustness and segmentation accuracy of U-Net models for brain tumor segmentation. Specifically, we generate synthetic T1-contrast-enhanced (T1-Ce) MRI scans using a GAN-based model with a shared encoding-decoding framework and shortest-path regularization. To quantify the effect of synthetic data contamination, we train U-Net models on progressively "poisoned" datasets, where synthetic data proportions range from 16.67% to 83.33%. Experimental results on a real MRI validation set reveal a significant performance degradation as synthetic data increases, with Dice coefficients dropping from 0.8937 (33.33% synthetic) to 0.7474 (83.33% synthetic). Accuracy and sensitivity exhibit similar downward trends, demonstrating the detrimental effect of synthetic data on segmentation robustness. These findings underscore the importance of quality control in synthetic data integration and highlight the risks of unregulated synthetic augmentation in medical image analysis. Our study provides critical insights for the development of more reliable and trustworthy AI-driven medical imaging systems.
Incorporating Cyclic Group Equivariance into Deep Learning for Reliable Reconstruction of Rotationally Symmetric Tomography Systems
Feb 04, 2025



Rotational symmetry is a defining feature of many tomography systems, including computed tomography (CT) and emission computed tomography (ECT), where detectors are arranged in a circular or periodically rotating configuration. This study revisits the image reconstruction process from the perspective of hardware-induced rotational symmetry and introduces a cyclic group equivariance framework for deep learning-based reconstruction. Specifically, we derive a mathematical correspondence that couples cyclic rotations in the projection domain to discrete rotations in the image domain, both arising from the same cyclic group inherent in the hardware design. This insight also reveals the uniformly distributed circular structure of the projection space. Building on this principle, we provide a cyclic rotation equivariant convolution design method to preserve projection domain symmetry and a cyclic group equivariance regularization approach that enforces consistent rotational transformations across the entire network. We further integrate these modules into a domain transform reconstruction framework and validate them using digital brain phantoms, training on discrete models and testing on more complex and realistic fuzzy variants. Results indicate markedly improved generalization and stability, with fewer artifacts and better detail preservation, especially under data distribution deviation. These findings highlight the potential of cyclic group equivariance as a unifying principle for tomographic reconstruction in rotationally symmetric systems, offering a flexible and interpretable solution for scenarios with limited data.
A Radiomics-Incorporated Deep Ensemble Learning Model for Multi-Parametric MRI-based Glioma Segmentation
Mar 19, 2023We developed a deep ensemble learning model with a radiomics spatial encoding execution for improved glioma segmentation accuracy using multi-parametric MRI (mp-MRI). This model was developed using 369 glioma patients with a 4-modality mp-MRI protocol: T1, contrast-enhanced T1 (T1-Ce), T2, and FLAIR. In each modality volume, a 3D sliding kernel was implemented across the brain to capture image heterogeneity: fifty-six radiomic features were extracted within the kernel, resulting in a 4th order tensor. Each radiomic feature can then be encoded as a 3D image volume, namely a radiomic feature map (RFM). PCA was employed for data dimension reduction and the first 4 PCs were selected. Four deep neural networks as sub-models following the U-Net architecture were trained for the segmenting of a region-of-interest (ROI): each sub-model utilizes the mp-MRI and 1 of the 4 PCs as a 5-channel input for a 2D execution. The 4 softmax probability results given by the U-net ensemble were superimposed and binarized by Otsu method as the segmentation result. Three ensemble models were trained to segment enhancing tumor (ET), tumor core (TC), and whole tumor (WT). The adopted radiomics spatial encoding execution enriches the image heterogeneity information that leads to the successful demonstration of the proposed deep ensemble model, which offers a new tool for mp-MRI based medical image segmentation.
Quantifying U-Net Uncertainty in Multi-Parametric MRI-based Glioma Segmentation by Spherical Image Projection
Oct 12, 2022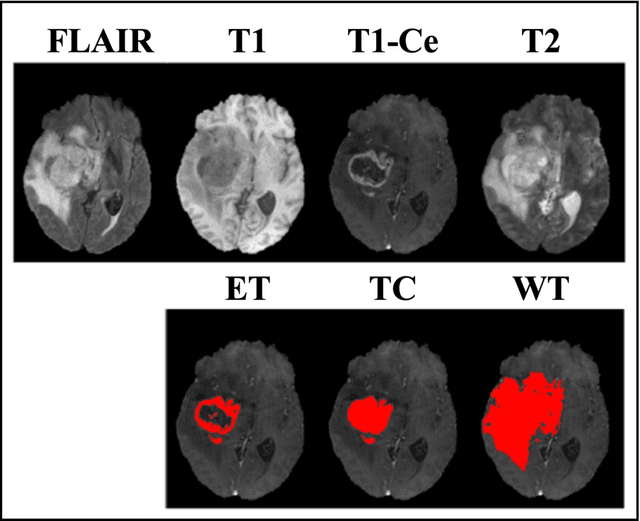
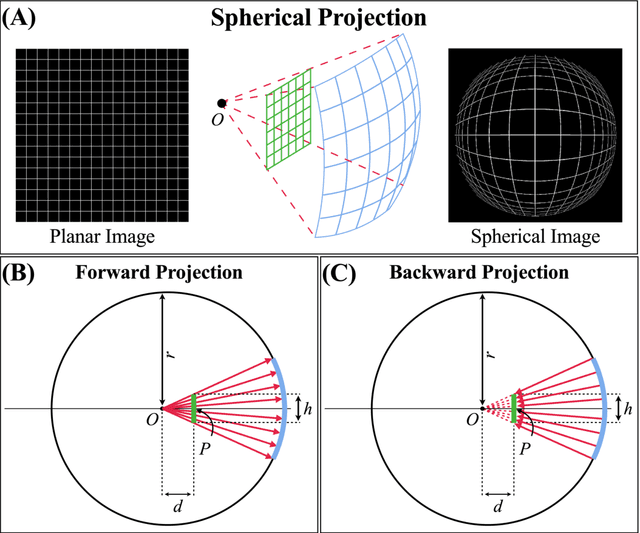
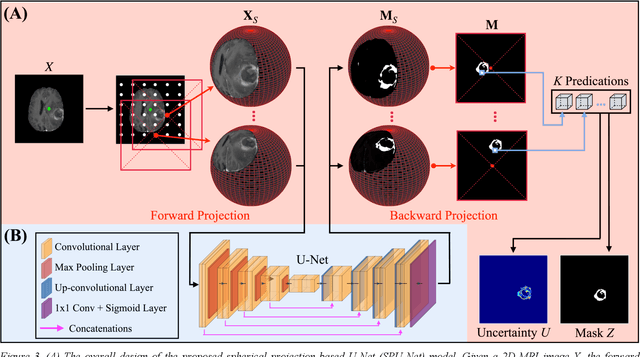
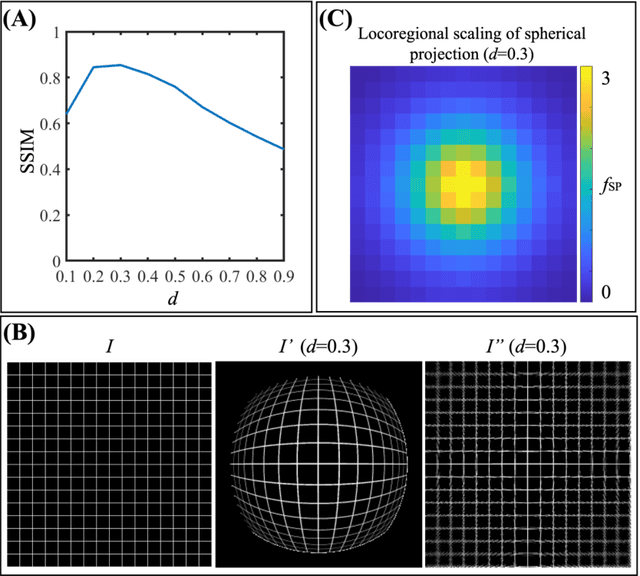
Purpose: To develop a U-Net segmentation uncertainty quantification method based on spherical image projection of multi-parametric MRI (MP-MRI) in glioma segmentation. Methods: The projection of planar MRI onto a spherical surface retains global anatomical information. By incorporating such image transformation in our proposed spherical projection-based U-Net (SPU-Net) segmentation model design, multiple segmentation predictions can be obtained for a single MRI. The final segmentation is the average of all predictions, and the variation can be shown as an uncertainty map. An uncertainty score was introduced to compare the uncertainty measurements' performance. The SPU-Net model was implemented on 369 glioma patients with MP-MRI scans. Three SPU-Nets were trained to segment enhancing tumor (ET), tumor core (TC), and whole tumor (WT), respectively. The SPU-Net was compared with (1) classic U-Net with test-time augmentation (TTA) and (2) linear scaling-based U-Net (LSU-Net) in both segmentation accuracy (Dice coefficient) and uncertainty (uncertainty map and uncertainty score). Results: The SPU-Net achieved low uncertainty for correct segmentation predictions (e.g., tumor interior or healthy tissue interior) and high uncertainty for incorrect results (e.g., tumor boundaries). This model could allow the identification of missed tumor targets or segmentation errors in U-Net. The SPU-Net achieved the highest uncertainty scores for 3 targets (ET/TC/WT): 0.826/0.848/0.936, compared to 0.784/0.643/0.872 for the U-Net with TTA and 0.743/0.702/0.876 for the LSU-Net. The SPU-Net also achieved statistically significantly higher Dice coefficients. Conclusion: The SPU-Net offers a powerful tool to quantify glioma segmentation uncertainty while improving segmentation accuracy. The proposed method can be generalized to other medical image-related deep-learning applications for uncertainty evaluation.
A Neural Ordinary Differential Equation Model for Visualizing Deep Neural Network Behaviors in Multi-Parametric MRI based Glioma Segmentation
Mar 23, 2022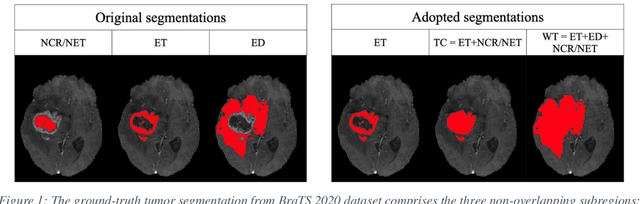
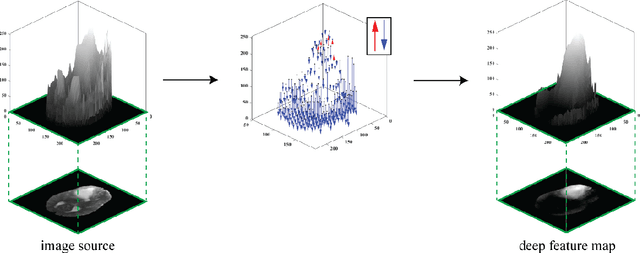
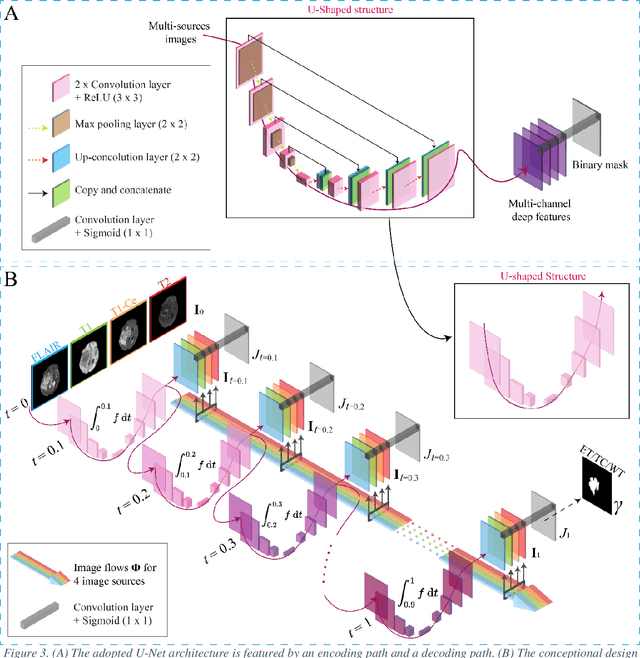
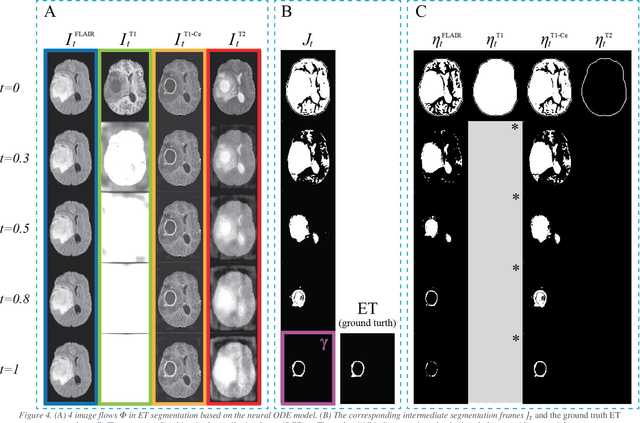
Purpose: To develop a neural ordinary differential equation (ODE) model for visualizing deep neural network (DNN) behavior during multi-parametric MRI (mp-MRI) based glioma segmentation as a method to enhance deep learning explainability. Methods: By hypothesizing that deep feature extraction can be modeled as a spatiotemporally continuous process, we designed a novel deep learning model, neural ODE, in which deep feature extraction was governed by an ODE without explicit expression. The dynamics of 1) MR images after interactions with DNN and 2) segmentation formation can be visualized after solving ODE. An accumulative contribution curve (ACC) was designed to quantitatively evaluate the utilization of each MRI by DNN towards the final segmentation results. The proposed neural ODE model was demonstrated using 369 glioma patients with a 4-modality mp-MRI protocol: T1, contrast-enhanced T1 (T1-Ce), T2, and FLAIR. Three neural ODE models were trained to segment enhancing tumor (ET), tumor core (TC), and whole tumor (WT). The key MR modalities with significant utilization by DNN were identified based on ACC analysis. Segmentation results by DNN using only the key MR modalities were compared to the ones using all 4 MR modalities. Results: All neural ODE models successfully illustrated image dynamics as expected. ACC analysis identified T1-Ce as the only key modality in ET and TC segmentations, while both FLAIR and T2 were key modalities in WT segmentation. Compared to the U-Net results using all 4 MR modalities, Dice coefficient of ET (0.784->0.775), TC (0.760->0.758), and WT (0.841->0.837) using the key modalities only had minimal differences without significance. Conclusion: The neural ODE model offers a new tool for optimizing the deep learning model inputs with enhanced explainability. The presented methodology can be generalized to other medical image-related deep learning applications.
A Radiomics-Boosted Deep-Learning Model for COVID-19 and Non-COVID-19 Pneumonia Detection Using Chest X-ray Image
Jul 19, 2021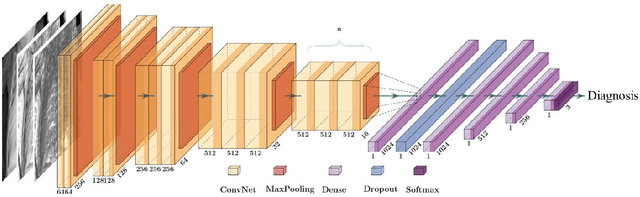
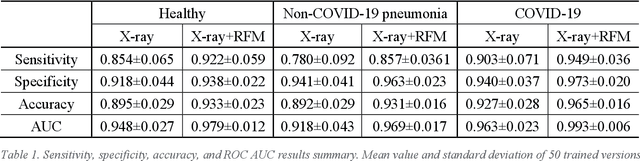
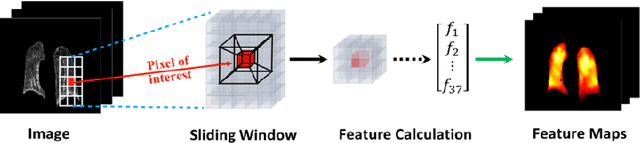
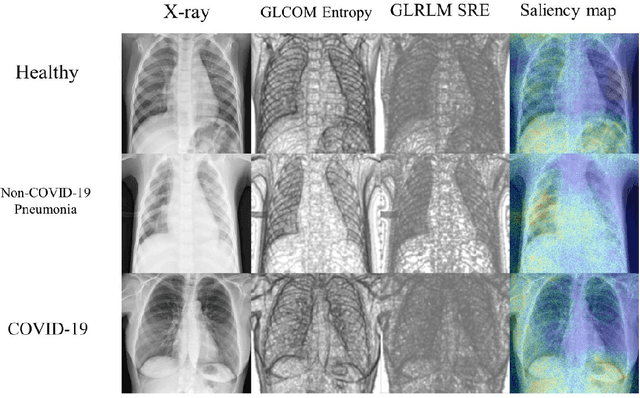
To develop a deep-learning model that integrates radiomics analysis for enhanced performance of COVID-19 and Non-COVID-19 pneumonia detection using chest X-ray image, two deep-learning models were trained based on a pre-trained VGG-16 architecture: in the 1st model, X-ray image was the sole input; in the 2nd model, X-ray image and 2 radiomic feature maps (RFM) selected by the saliency map analysis of the 1st model were stacked as the input. Both models were developed using 812 chest X-ray images with 262/288/262 COVID-19/Non-COVID-19 pneumonia/healthy cases, and 649/163 cases were assigned as training-validation/independent test sets. In 1st model using X-ray as the sole input, the 1) sensitivity, 2) specificity, 3) accuracy, and 4) ROC Area-Under-the-Curve of COVID-19 vs Non-COVID-19 pneumonia detection were 1) 0.90$\pm$0.07 vs 0.78$\pm$0.09, 2) 0.94$\pm$0.04 vs 0.94$\pm$0.04, 3) 0.93$\pm$0.03 vs 0.89$\pm$0.03, and 4) 0.96$\pm$0.02 vs 0.92$\pm$0.04. In the 2nd model, two RFMs, Entropy and Short-Run-Emphasize, were selected with their highest cross-correlations with the saliency maps of the 1st model. The corresponding results demonstrated significant improvements (p<0.05) of COVID-19 vs Non-COVID-19 pneumonia detection: 1) 0.95$\pm$0.04 vs 0.85$\pm$0.04, 2) 0.97$\pm$0.02 vs 0.96$\pm$0.02, 3) 0.97$\pm$0.02 vs 0.93$\pm$0.02, and 4) 0.99$\pm$0.01 vs 0.97$\pm$0.02. The reduced variations suggested a superior robustness of 2nd model design.
Post-Radiotherapy PET Image Outcome Prediction by Deep Learning under Biological Model Guidance: A Feasibility Study of Oropharyngeal Cancer Application
May 22, 2021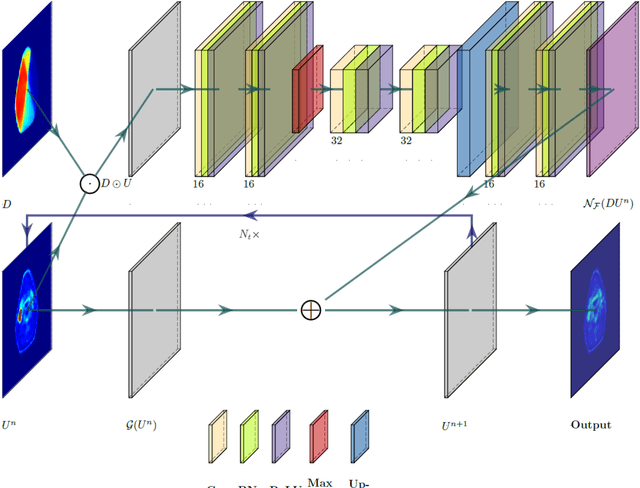
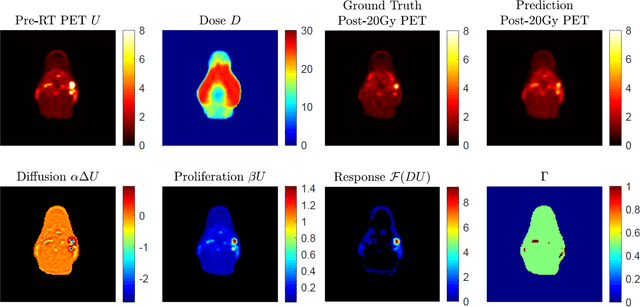
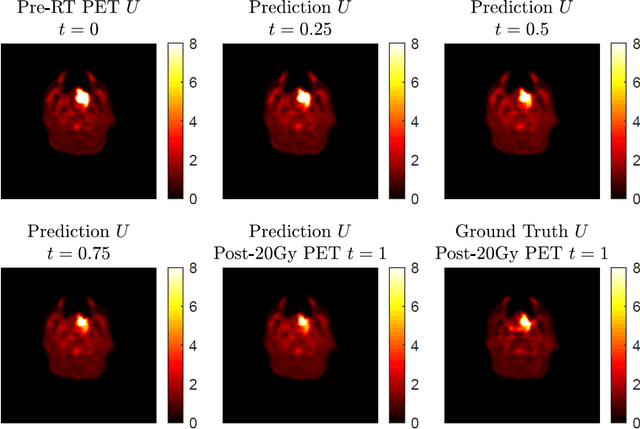
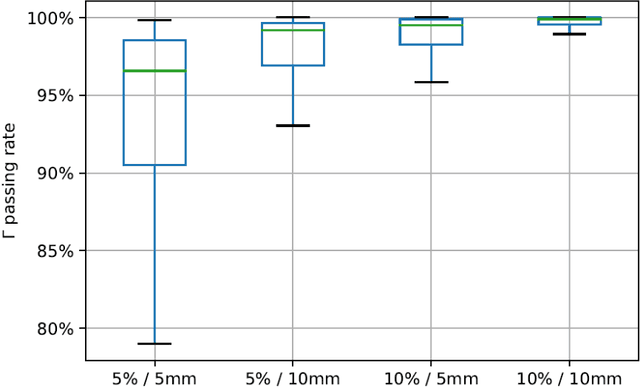
This paper develops a method of biologically guided deep learning for post-radiation FDG-PET image outcome prediction based on pre-radiation images and radiotherapy dose information. Based on the classic reaction-diffusion mechanism, a novel biological model was proposed using a partial differential equation that incorporates spatial radiation dose distribution as a patient-specific treatment information variable. A 7-layer encoder-decoder-based convolutional neural network (CNN) was designed and trained to learn the proposed biological model. As such, the model could generate post-radiation FDG-PET image outcome predictions with possible time-series transition from pre-radiotherapy image states to post-radiotherapy states. The proposed method was developed using 64 oropharyngeal patients with paired FDG-PET studies before and after 20Gy delivery (2Gy/daily fraction) by IMRT. In a two-branch deep learning execution, the proposed CNN learns specific terms in the biological model from paired FDG-PET images and spatial dose distribution as in one branch, and the biological model generates post-20Gy FDG-PET image prediction in the other branch. The proposed method successfully generated post-20Gy FDG-PET image outcome prediction with breakdown illustrations of biological model components. Time-series FDG-PET image predictions were generated to demonstrate the feasibility of disease response rendering. The developed biologically guided deep learning method achieved post-20Gy FDG-PET image outcome predictions in good agreement with ground-truth results. With break-down biological modeling components, the outcome image predictions could be used in adaptive radiotherapy decision-making to optimize personalized plans for the best outcome in the future.
Iterative Inversion of Deformation Vector Fields with Feedback Control
Mar 28, 2018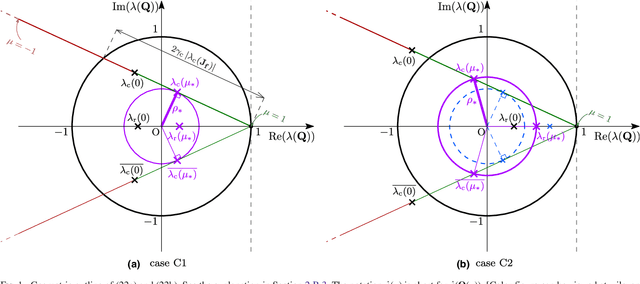
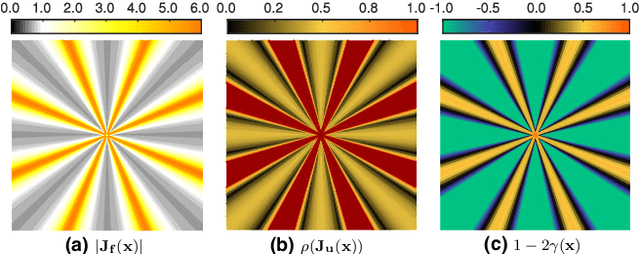
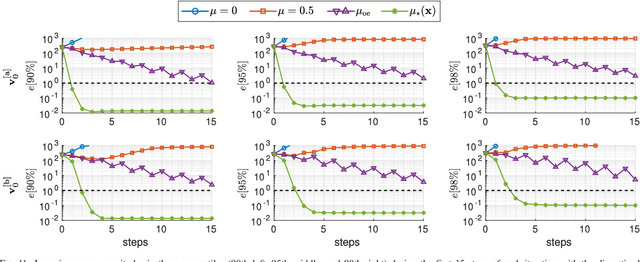
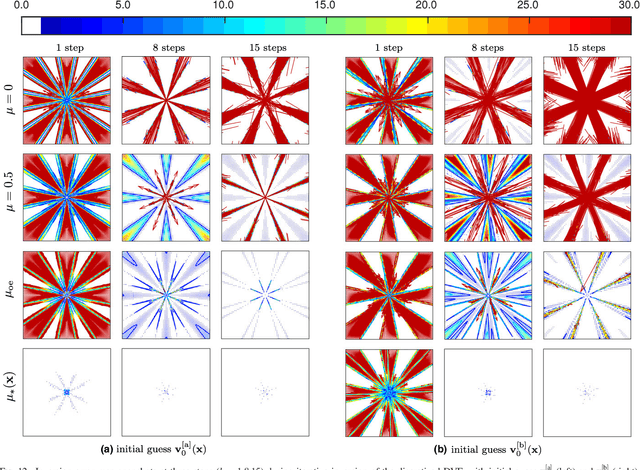
Purpose: Often, the inverse deformation vector field (DVF) is needed together with the corresponding forward DVF in 4D reconstruction and dose calculation, adaptive radiation therapy, and simultaneous deformable registration. This study aims at improving both accuracy and efficiency of iterative algorithms for DVF inversion, and advancing our understanding of divergence and latency conditions. Method: We introduce a framework of fixed-point iteration algorithms with active feedback control for DVF inversion. Based on rigorous convergence analysis, we design control mechanisms for modulating the inverse consistency (IC) residual of the current iterate, to be used as feedback into the next iterate. The control is designed adaptively to the input DVF with the objective to enlarge the convergence area and expedite convergence. Three particular settings of feedback control are introduced: constant value over the domain throughout the iteration; alternating values between iteration steps; and spatially variant values. We also introduce three spectral measures of the displacement Jacobian for characterizing a DVF. These measures reveal the critical role of what we term the non-translational displacement component (NTDC) of the DVF. We carry out inversion experiments with an analytical DVF pair, and with DVFs associated with thoracic CT images of 6 patients at end of expiration and end of inspiration. Results: NTDC-adaptive iterations are shown to attain a larger convergence region at a faster pace compared to previous non-adaptive DVF inversion iteration algorithms. By our numerical experiments, alternating control yields smaller IC residuals and inversion errors than constant control. Spatially variant control renders smaller residuals and errors by at least an order of magnitude, compared to other schemes, in no more than 10 steps. Inversion results also show remarkable quantitative agreement with analysis-based predictions. Conclusion: Our analysis captures properties of DVF data associated with clinical CT images, and provides new understanding of iterative DVF inversion algorithms with a simple residual feedback control. Adaptive control is necessary and highly effective in the presence of non-small NTDCs. The adaptive iterations or the spectral measures, or both, may potentially be incorporated into deformable image registration methods.