 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSYN-LUNGS: Towards Simulating Lung Nodules with Anatomy-Informed Digital Twins for AI Training
Feb 28, 2025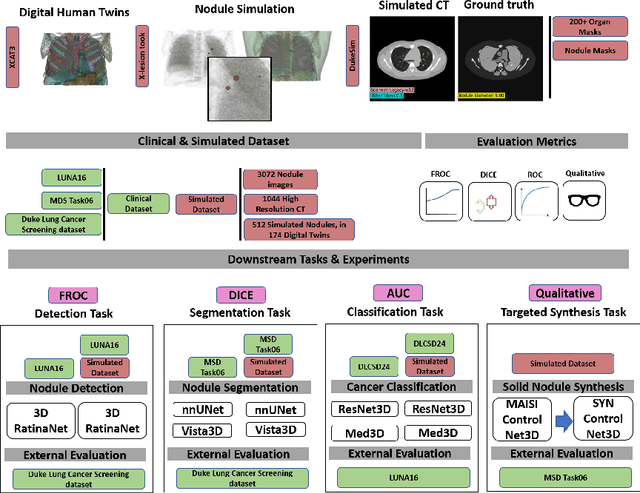
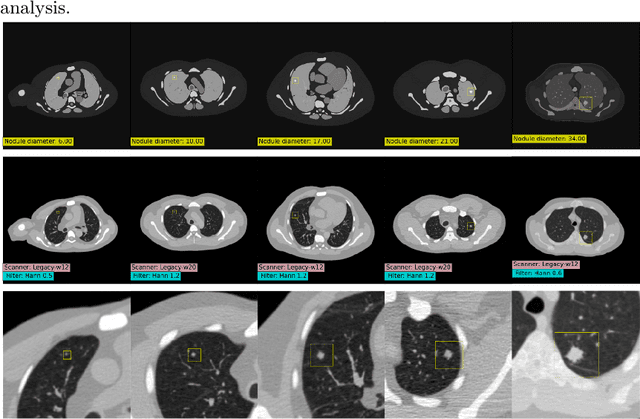
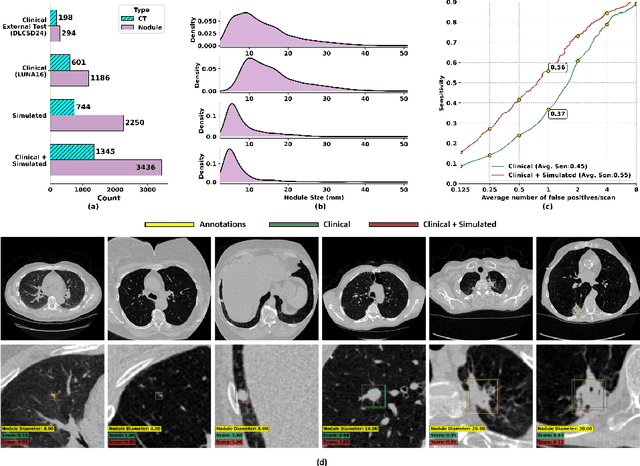
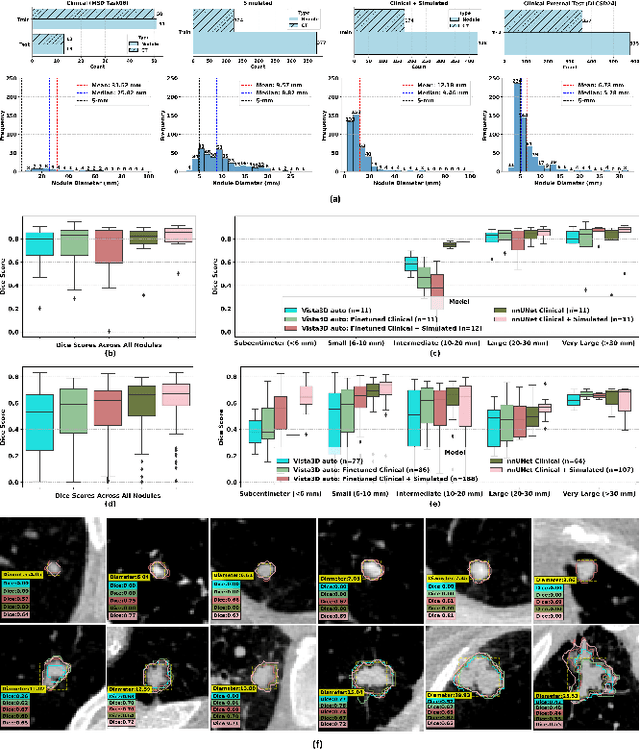
AI models for lung cancer screening are limited by data scarcity, impacting generalizability and clinical applicability. Generative models address this issue but are constrained by training data variability. We introduce SYN-LUNGS, a framework for generating high-quality 3D CT images with detailed annotations. SYN-LUNGS integrates XCAT3 phantoms for digital twin generation, X-Lesions for nodule simulation (varying size, location, and appearance), and DukeSim for CT image formation with vendor and parameter variability. The dataset includes 3,072 nodule images from 1,044 simulated CT scans, with 512 lesions and 174 digital twins. Models trained on clinical + simulated data outperform clinical only models, achieving 10% improvement in detection, 2-9% in segmentation and classification, and enhanced synthesis.By incorporating anatomy-informed simulations, SYN-LUNGS provides a scalable approach for AI model development, particularly in rare disease representation and improving model reliability.
AI in Lung Health: Benchmarking Detection and Diagnostic Models Across Multiple CT Scan Datasets
May 07, 2024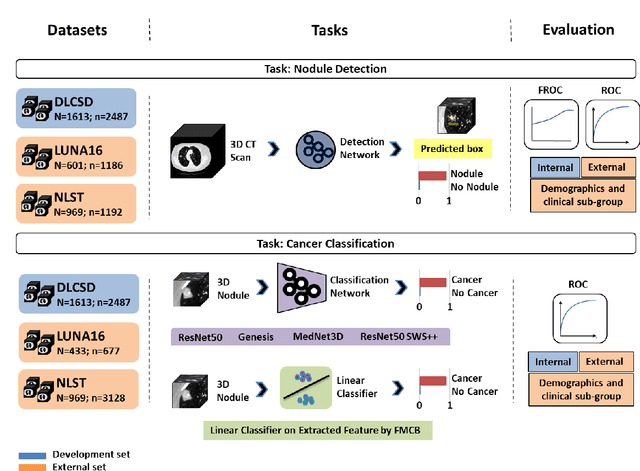
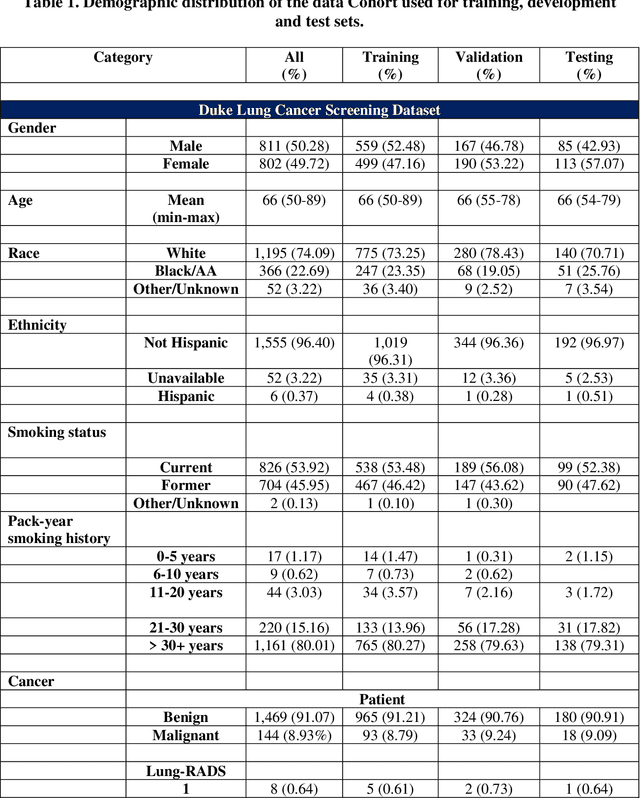
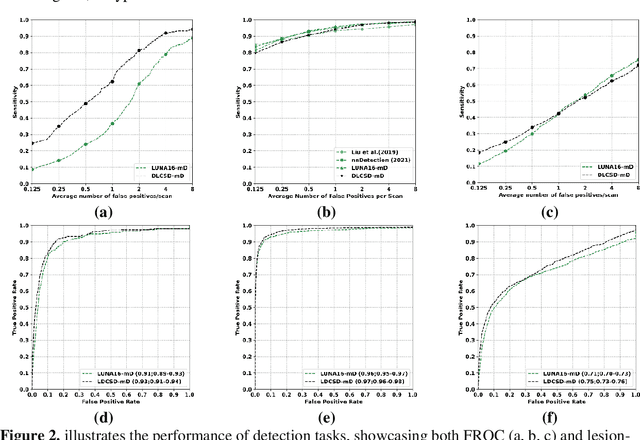
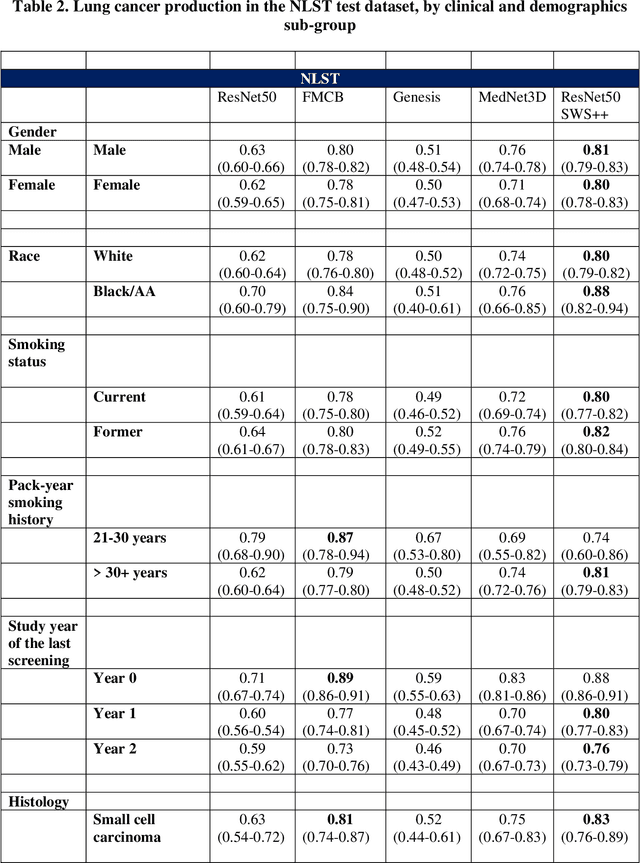
BACKGROUND: Lung cancer's high mortality rate can be mitigated by early detection, which is increasingly reliant on artificial intelligence (AI) for diagnostic imaging. However, the performance of AI models is contingent upon the datasets used for their training and validation. METHODS: This study developed and validated the DLCSD-mD and LUNA16-mD models utilizing the Duke Lung Cancer Screening Dataset (DLCSD), encompassing over 2,000 CT scans with more than 3,000 annotations. These models were rigorously evaluated against the internal DLCSD and external LUNA16 and NLST datasets, aiming to establish a benchmark for imaging-based performance. The assessment focused on creating a standardized evaluation framework to facilitate consistent comparison with widely utilized datasets, ensuring a comprehensive validation of the model's efficacy. Diagnostic accuracy was assessed using free-response receiver operating characteristic (FROC) and area under the curve (AUC) analyses. RESULTS: On the internal DLCSD set, the DLCSD-mD model achieved an AUC of 0.93 (95% CI:0.91-0.94), demonstrating high accuracy. Its performance was sustained on the external datasets, with AUCs of 0.97 (95% CI: 0.96-0.98) on LUNA16 and 0.75 (95% CI: 0.73-0.76) on NLST. Similarly, the LUNA16-mD model recorded an AUC of 0.96 (95% CI: 0.95-0.97) on its native dataset and showed transferable diagnostic performance with AUCs of 0.91 (95% CI: 0.89-0.93) on DLCSD and 0.71 (95% CI: 0.70-0.72) on NLST. CONCLUSION: The DLCSD-mD model exhibits reliable performance across different datasets, establishing the DLCSD as a robust benchmark for lung cancer detection and diagnosis. Through the provision of our models and code to the public domain, we aim to accelerate the development of AI-based diagnostic tools and encourage reproducibility and collaborative advancements within the medical machine-learning (ML) field.
VLST: Virtual Lung Screening Trial for Lung Cancer Detection Using Virtual Imaging Trial
Apr 17, 2024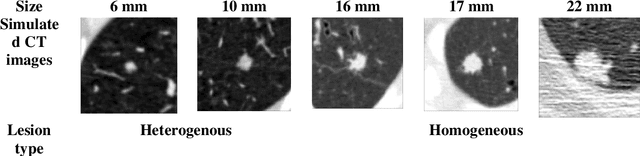

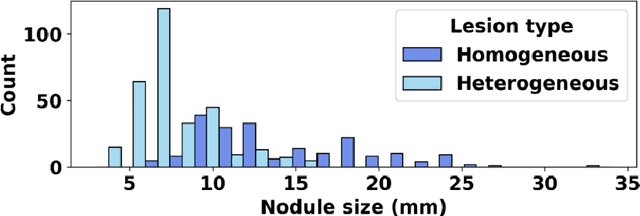
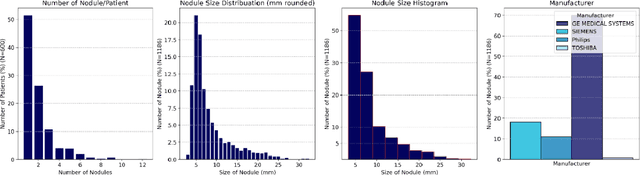
Importance: The efficacy of lung cancer screening can be significantly impacted by the imaging modality used. This Virtual Lung Screening Trial (VLST) addresses the critical need for precision in lung cancer diagnostics and the potential for reducing unnecessary radiation exposure in clinical settings. Objectives: To establish a virtual imaging trial (VIT) platform that accurately simulates real-world lung screening trials (LSTs) to assess the diagnostic accuracy of CT and CXR modalities. Design, Setting, and Participants: Utilizing computational models and machine learning algorithms, we created a diverse virtual patient population. The cohort, designed to mirror real-world demographics, was assessed using virtual imaging techniques that reflect historical imaging technologies. Main Outcomes and Measures: The primary outcome was the difference in the Area Under the Curve (AUC) for CT and CXR modalities across lesion types and sizes. Results: The study analyzed 298 CT and 313 CXR simulated images from 313 virtual patients, with a lesion-level AUC of 0.81 (95% CI: 0.78-0.84) for CT and 0.55 (95% CI: 0.53-0.56) for CXR. At the patient level, CT demonstrated an AUC of 0.85 (95% CI: 0.80-0.89), compared to 0.53 (95% CI: 0.47-0.60) for CXR. Subgroup analyses indicated CT's superior performance in detecting homogeneous lesions (AUC of 0.97 for lesion-level) and heterogeneous lesions (AUC of 0.71 for lesion-level) as well as in identifying larger nodules (AUC of 0.98 for nodules > 8 mm). Conclusion and Relevance: The VIT platform validated the superior diagnostic accuracy of CT over CXR, especially for smaller nodules, underscoring its potential to replicate real clinical imaging trials. These findings advocate for the integration of virtual trials in the evaluation and improvement of imaging-based diagnostic tools.
A personalized Uncertainty Quantification framework for patient survival models: estimating individual uncertainty of patients with metastatic brain tumors in the absence of ground truth
Nov 28, 2023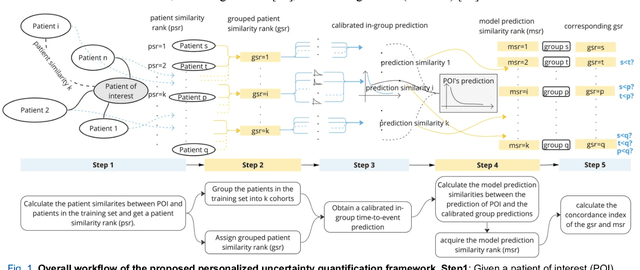
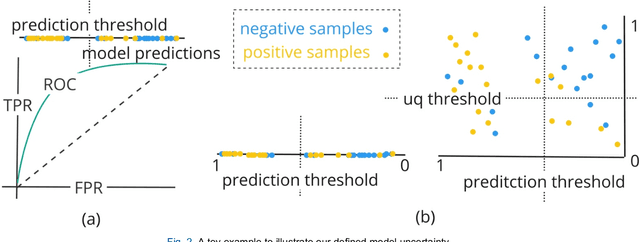
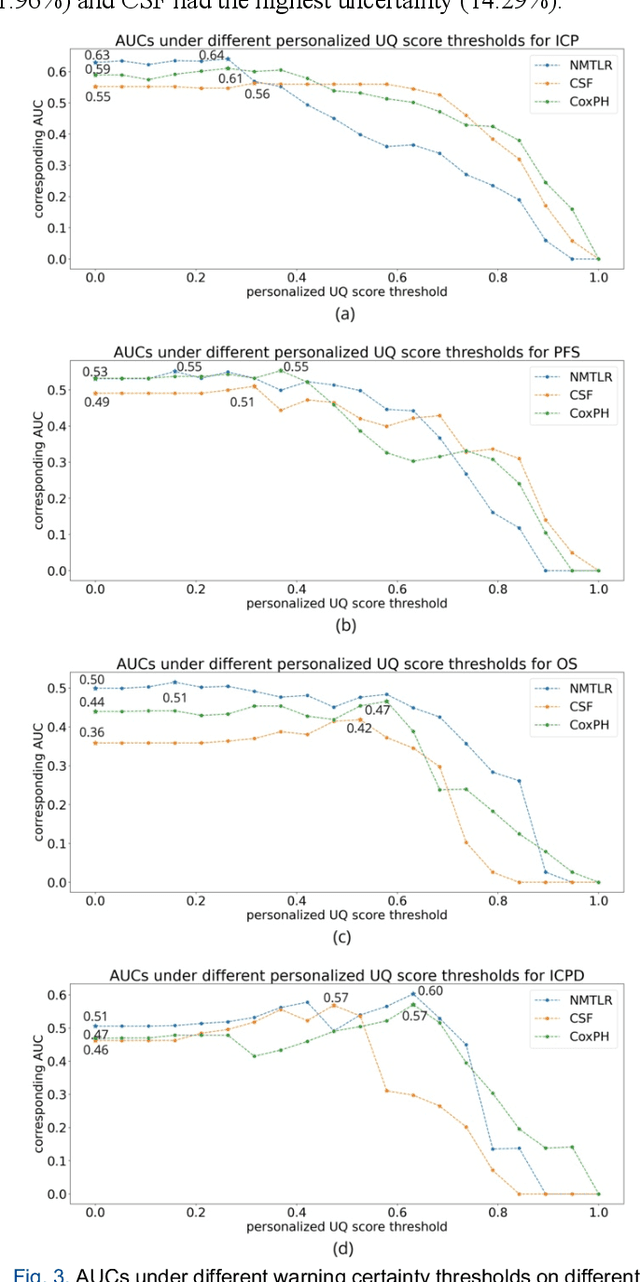
TodevelopanovelUncertaintyQuantification (UQ) framework to estimate the uncertainty of patient survival models in the absence of ground truth, we developed and evaluated our approach based on a dataset of 1383 patients treated with stereotactic radiosurgery (SRS) for brain metastases between January 2015 and December 2020. Our motivating hypothesis is that a time-to-event prediction of a test patient on inference is more certain given a higher feature-space-similarity to patients in the training set. Therefore, the uncertainty for a particular patient-of-interest is represented by the concordance index between a patient similarity rank and a prediction similarity rank. Model uncertainty was defined as the increased percentage of the max uncertainty-constrained-AUC compared to the model AUC. We evaluated our method on multiple clinically-relevant endpoints, including time to intracranial progression (ICP), progression-free survival (PFS) after SRS, overall survival (OS), and time to ICP and/or death (ICPD), on a variety of both statistical and non-statistical models, including CoxPH, conditional survival forest (CSF), and neural multi-task linear regression (NMTLR). Our results show that all models had the lowest uncertainty on ICP (2.21%) and the highest uncertainty (17.28%) on ICPD. OS models demonstrated high variation in uncertainty performance, where NMTLR had the lowest uncertainty(1.96%)and CSF had the highest uncertainty (14.29%). In conclusion, our method can estimate the uncertainty of individual patient survival modeling results. As expected, our data empirically demonstrate that as model uncertainty measured via our technique increases, the similarity between a feature-space and its predicted outcome decreases.
Duke Spleen Data Set: A Publicly Available Spleen MRI and CT dataset for Training Segmentation
May 09, 2023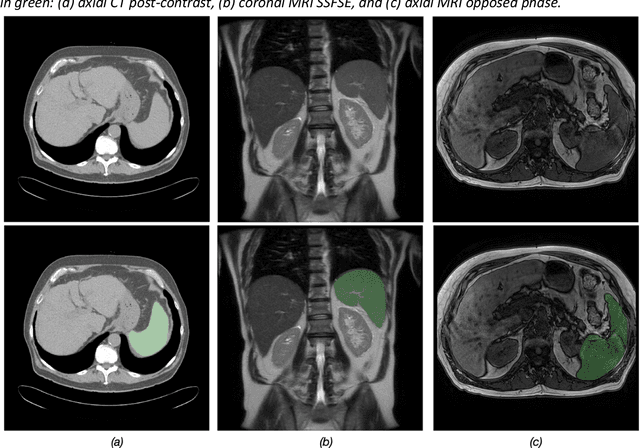

Spleen volumetry is primarily associated with patients suffering from chronic liver disease and portal hypertension, as they often have spleens with abnormal shapes and sizes. However, manually segmenting the spleen to obtain its volume is a time-consuming process. Deep learning algorithms have proven to be effective in automating spleen segmentation, but a suitable dataset is necessary for training such algorithms. To our knowledge, the few publicly available datasets for spleen segmentation lack confounding features such as ascites and abdominal varices. To address this issue, the Duke Spleen Data Set (DSDS) has been developed, which includes 109 CT and MRI volumes from patients with chronic liver disease and portal hypertension. The dataset includes a diverse range of image types, vendors, planes, and contrasts, as well as varying spleen shapes and sizes due to underlying disease states. The DSDS aims to facilitate the creation of robust spleen segmentation models that can take into account these variations and confounding factors.
A Radiomics-Boosted Deep-Learning Model for COVID-19 and Non-COVID-19 Pneumonia Detection Using Chest X-ray Image
Jul 19, 2021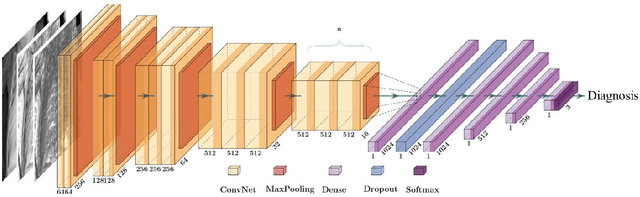
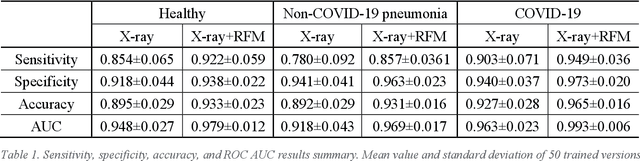
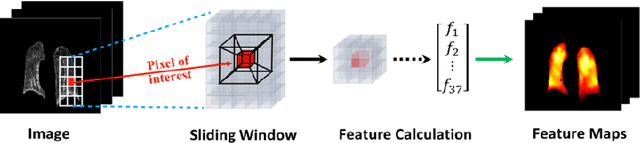
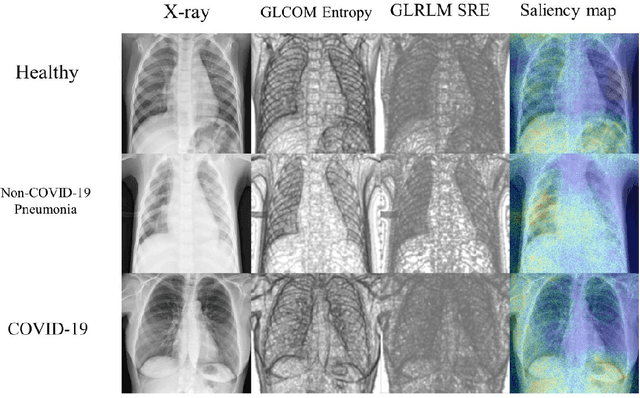
To develop a deep-learning model that integrates radiomics analysis for enhanced performance of COVID-19 and Non-COVID-19 pneumonia detection using chest X-ray image, two deep-learning models were trained based on a pre-trained VGG-16 architecture: in the 1st model, X-ray image was the sole input; in the 2nd model, X-ray image and 2 radiomic feature maps (RFM) selected by the saliency map analysis of the 1st model were stacked as the input. Both models were developed using 812 chest X-ray images with 262/288/262 COVID-19/Non-COVID-19 pneumonia/healthy cases, and 649/163 cases were assigned as training-validation/independent test sets. In 1st model using X-ray as the sole input, the 1) sensitivity, 2) specificity, 3) accuracy, and 4) ROC Area-Under-the-Curve of COVID-19 vs Non-COVID-19 pneumonia detection were 1) 0.90$\pm$0.07 vs 0.78$\pm$0.09, 2) 0.94$\pm$0.04 vs 0.94$\pm$0.04, 3) 0.93$\pm$0.03 vs 0.89$\pm$0.03, and 4) 0.96$\pm$0.02 vs 0.92$\pm$0.04. In the 2nd model, two RFMs, Entropy and Short-Run-Emphasize, were selected with their highest cross-correlations with the saliency maps of the 1st model. The corresponding results demonstrated significant improvements (p<0.05) of COVID-19 vs Non-COVID-19 pneumonia detection: 1) 0.95$\pm$0.04 vs 0.85$\pm$0.04, 2) 0.97$\pm$0.02 vs 0.96$\pm$0.02, 3) 0.97$\pm$0.02 vs 0.93$\pm$0.02, and 4) 0.99$\pm$0.01 vs 0.97$\pm$0.02. The reduced variations suggested a superior robustness of 2nd model design.