 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDuke Spleen Data Set: A Publicly Available Spleen MRI and CT dataset for Training Segmentation
Paper and Code
May 09, 2023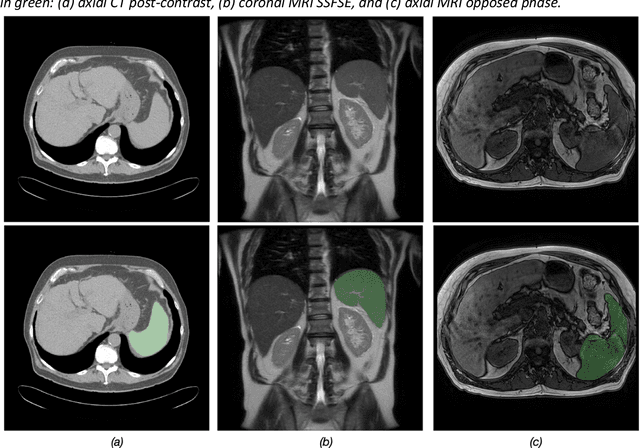

Spleen volumetry is primarily associated with patients suffering from chronic liver disease and portal hypertension, as they often have spleens with abnormal shapes and sizes. However, manually segmenting the spleen to obtain its volume is a time-consuming process. Deep learning algorithms have proven to be effective in automating spleen segmentation, but a suitable dataset is necessary for training such algorithms. To our knowledge, the few publicly available datasets for spleen segmentation lack confounding features such as ascites and abdominal varices. To address this issue, the Duke Spleen Data Set (DSDS) has been developed, which includes 109 CT and MRI volumes from patients with chronic liver disease and portal hypertension. The dataset includes a diverse range of image types, vendors, planes, and contrasts, as well as varying spleen shapes and sizes due to underlying disease states. The DSDS aims to facilitate the creation of robust spleen segmentation models that can take into account these variations and confounding factors.