 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOrgan-Aware Attention Improves CT Triage and Classification
Jan 19, 2026There is an urgent need for triage and classification of high-volume medical imaging modalities such as computed tomography (CT), which can improve patient care and mitigate radiologist burnout. Study-level CT triage requires calibrated predictions with localized evidence; however, off-the-shelf Vision Language Models (VLM) struggle with 3D anatomy, protocol shifts, and noisy report supervision. This study used the two largest publicly available chest CT datasets: CT-RATE and RADCHEST-CT (held-out external test set). Our carefully tuned supervised baseline (instantiated as a simple Global Average Pooling head) establishes a new supervised state of the art, surpassing all reported linear-probe VLMs. Building on this baseline, we present ORACLE-CT, an encoder-agnostic, organ-aware head that pairs Organ-Masked Attention (mask-restricted, per-organ pooling that yields spatial evidence) with Organ-Scalar Fusion (lightweight fusion of normalized volume and mean-HU cues). In the chest setting, ORACLE-CT masked attention model achieves AUROC 0.86 on CT-RATE; in the abdomen setting, on MERLIN (30 findings), our supervised baseline exceeds a reproduced zero-shot VLM baseline obtained by running publicly released weights through our pipeline, and adding masked attention plus scalar fusion further improves performance to AUROC 0.85. Together, these results deliver state-of-the-art supervised classification performance across both chest and abdomen CT under a unified evaluation protocol. The source code is available at https://github.com/lavsendahal/oracle-ct.
SYN-LUNGS: Towards Simulating Lung Nodules with Anatomy-Informed Digital Twins for AI Training
Feb 28, 2025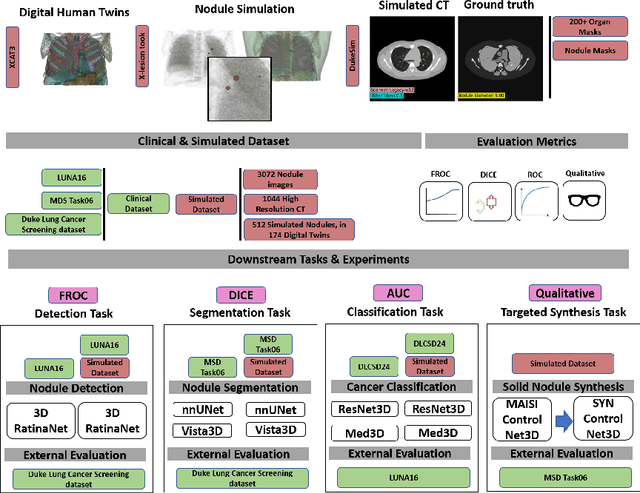
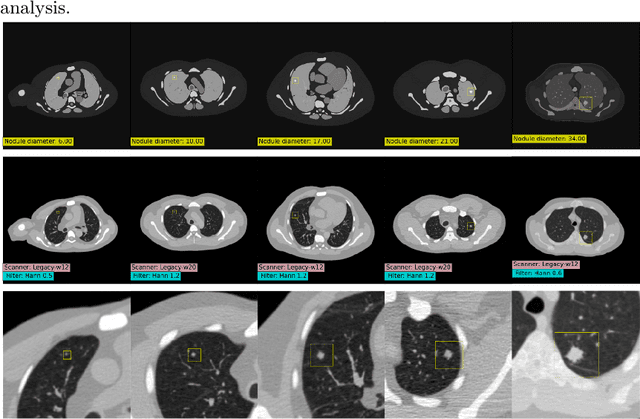
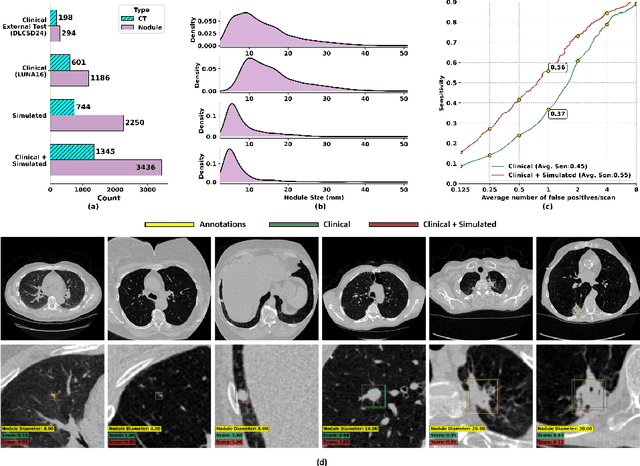
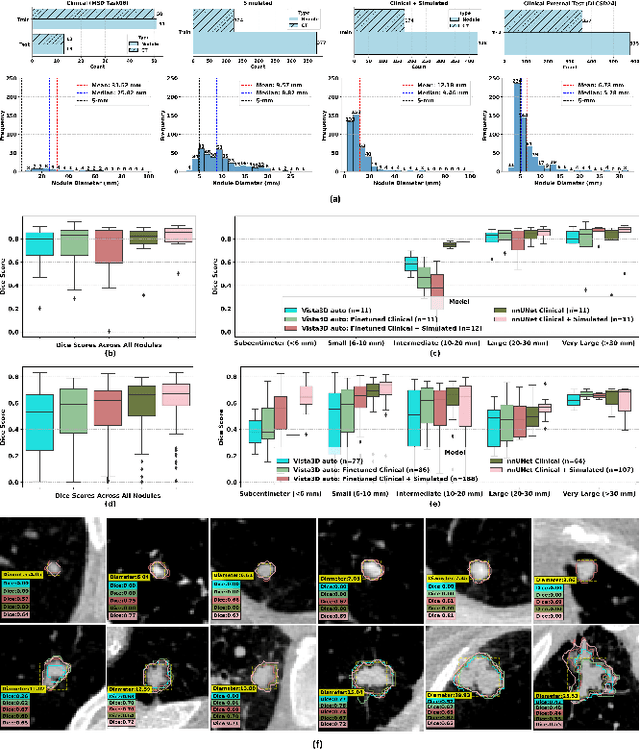
AI models for lung cancer screening are limited by data scarcity, impacting generalizability and clinical applicability. Generative models address this issue but are constrained by training data variability. We introduce SYN-LUNGS, a framework for generating high-quality 3D CT images with detailed annotations. SYN-LUNGS integrates XCAT3 phantoms for digital twin generation, X-Lesions for nodule simulation (varying size, location, and appearance), and DukeSim for CT image formation with vendor and parameter variability. The dataset includes 3,072 nodule images from 1,044 simulated CT scans, with 512 lesions and 174 digital twins. Models trained on clinical + simulated data outperform clinical only models, achieving 10% improvement in detection, 2-9% in segmentation and classification, and enhanced synthesis.By incorporating anatomy-informed simulations, SYN-LUNGS provides a scalable approach for AI model development, particularly in rare disease representation and improving model reliability.
XCAT-2.0: A Comprehensive Library of Personalized Digital Twins Derived from CT Scans
May 18, 2024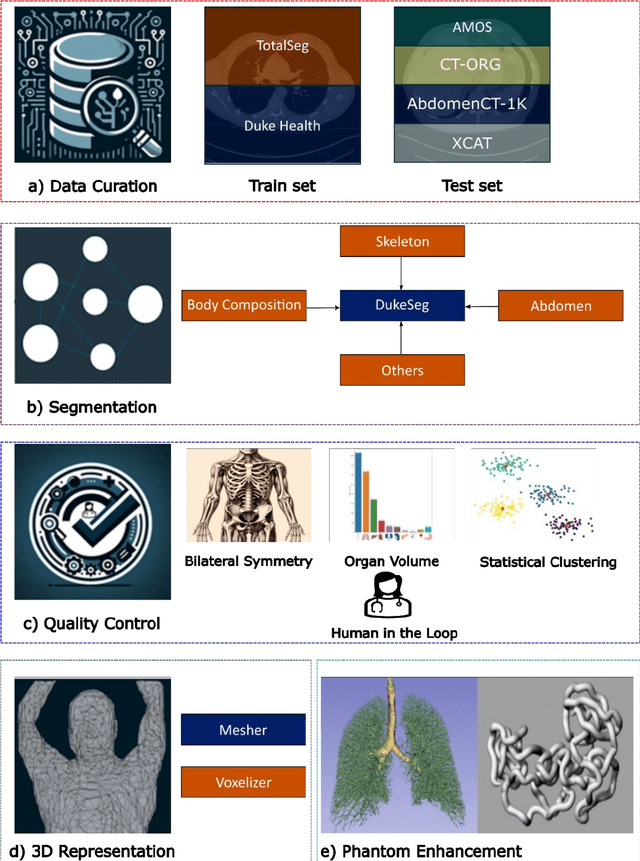
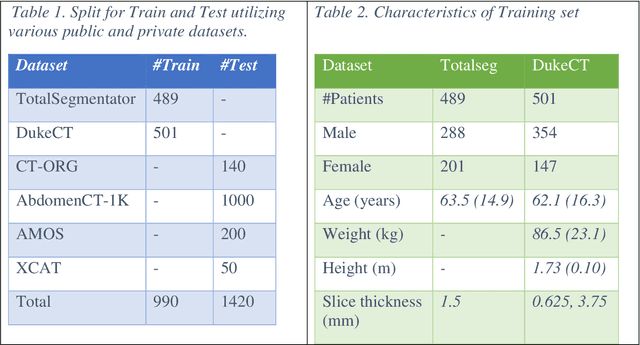
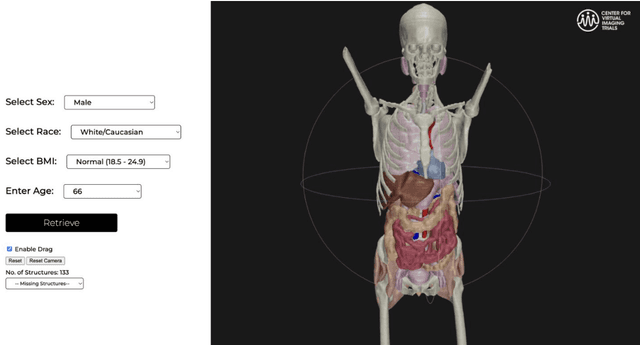
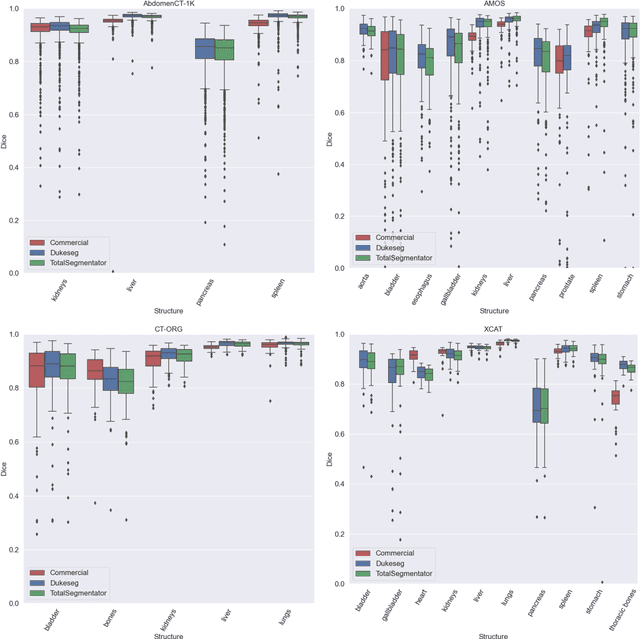
Virtual Imaging Trials (VIT) offer a cost-effective and scalable approach for evaluating medical imaging technologies. Computational phantoms, which mimic real patient anatomy and physiology, play a central role in VIT. However, the current libraries of computational phantoms face limitations, particularly in terms of sample size and diversity. Insufficient representation of the population hampers accurate assessment of imaging technologies across different patient groups. Traditionally, phantoms were created by manual segmentation, which is a laborious and time-consuming task, impeding the expansion of phantom libraries. This study presents a framework for realistic computational phantom modeling using a suite of four deep learning segmentation models, followed by three forms of automated organ segmentation quality control. Over 2500 computational phantoms with up to 140 structures illustrating a sophisticated approach to detailed anatomical modeling are released. Phantoms are available in both voxelized and surface mesh formats. The framework is aggregated with an in-house CT scanner simulator to produce realistic CT images. The framework can potentially advance virtual imaging trials, facilitating comprehensive and reliable evaluations of medical imaging technologies. Phantoms may be requested at https://cvit.duke.edu/resources/, code, model weights, and sample CT images are available at https://xcat-2.github.io.
AI in Lung Health: Benchmarking Detection and Diagnostic Models Across Multiple CT Scan Datasets
May 07, 2024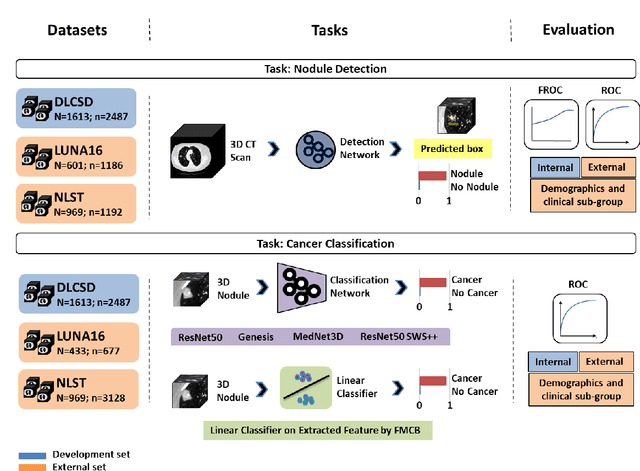
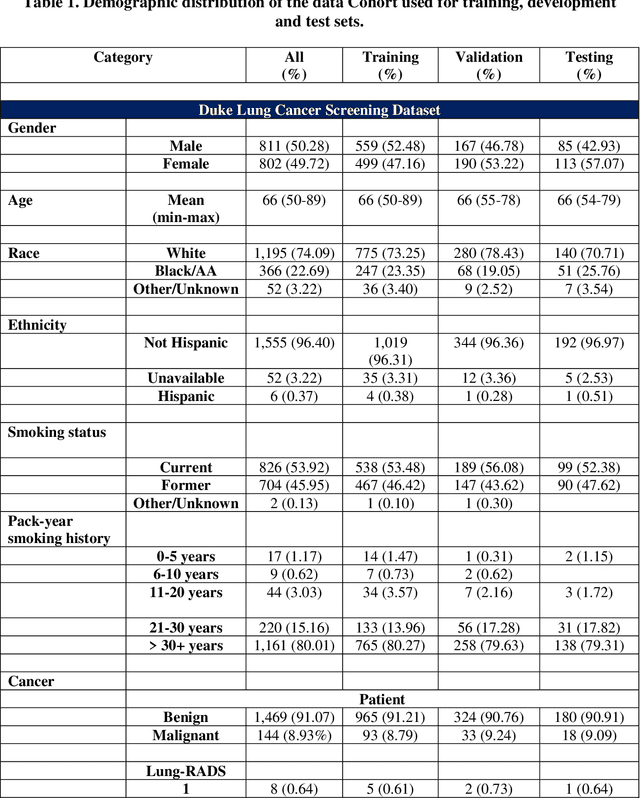
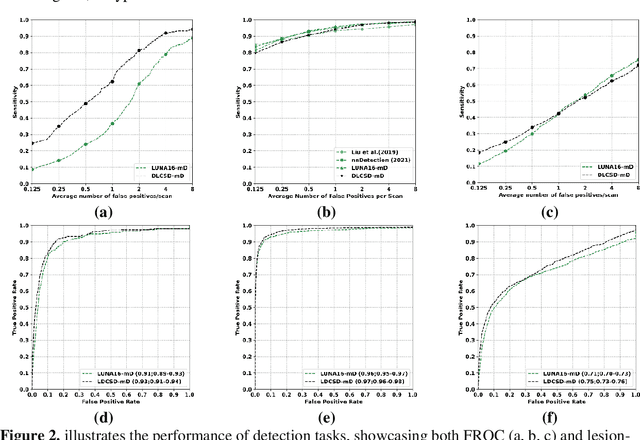
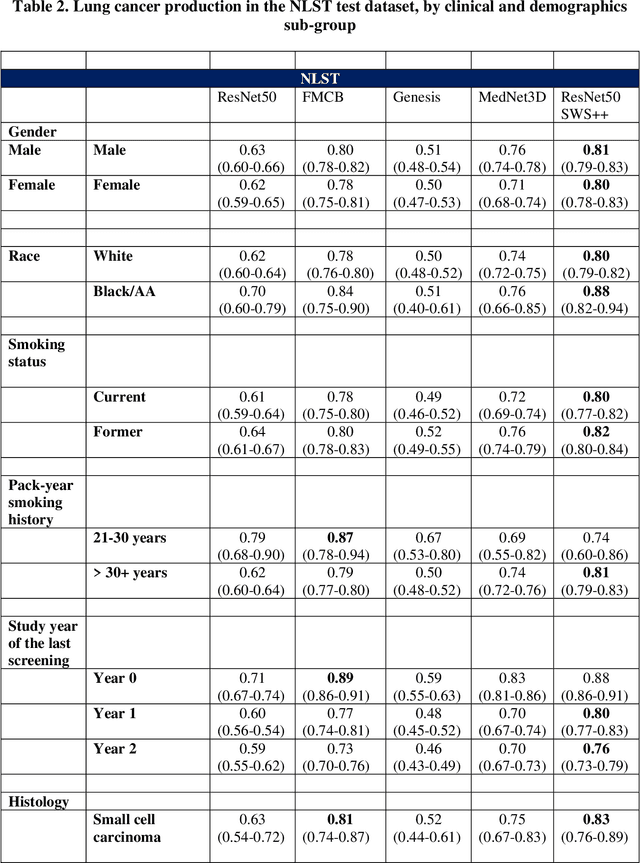
BACKGROUND: Lung cancer's high mortality rate can be mitigated by early detection, which is increasingly reliant on artificial intelligence (AI) for diagnostic imaging. However, the performance of AI models is contingent upon the datasets used for their training and validation. METHODS: This study developed and validated the DLCSD-mD and LUNA16-mD models utilizing the Duke Lung Cancer Screening Dataset (DLCSD), encompassing over 2,000 CT scans with more than 3,000 annotations. These models were rigorously evaluated against the internal DLCSD and external LUNA16 and NLST datasets, aiming to establish a benchmark for imaging-based performance. The assessment focused on creating a standardized evaluation framework to facilitate consistent comparison with widely utilized datasets, ensuring a comprehensive validation of the model's efficacy. Diagnostic accuracy was assessed using free-response receiver operating characteristic (FROC) and area under the curve (AUC) analyses. RESULTS: On the internal DLCSD set, the DLCSD-mD model achieved an AUC of 0.93 (95% CI:0.91-0.94), demonstrating high accuracy. Its performance was sustained on the external datasets, with AUCs of 0.97 (95% CI: 0.96-0.98) on LUNA16 and 0.75 (95% CI: 0.73-0.76) on NLST. Similarly, the LUNA16-mD model recorded an AUC of 0.96 (95% CI: 0.95-0.97) on its native dataset and showed transferable diagnostic performance with AUCs of 0.91 (95% CI: 0.89-0.93) on DLCSD and 0.71 (95% CI: 0.70-0.72) on NLST. CONCLUSION: The DLCSD-mD model exhibits reliable performance across different datasets, establishing the DLCSD as a robust benchmark for lung cancer detection and diagnosis. Through the provision of our models and code to the public domain, we aim to accelerate the development of AI-based diagnostic tools and encourage reproducibility and collaborative advancements within the medical machine-learning (ML) field.
VLST: Virtual Lung Screening Trial for Lung Cancer Detection Using Virtual Imaging Trial
Apr 17, 2024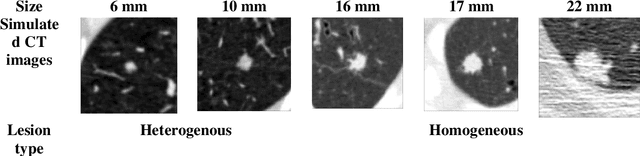

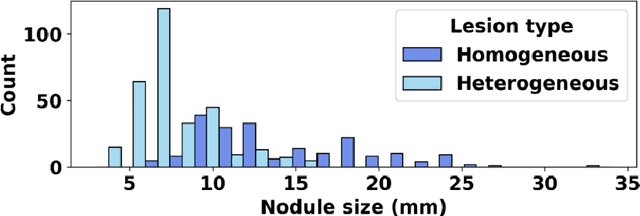
Importance: The efficacy of lung cancer screening can be significantly impacted by the imaging modality used. This Virtual Lung Screening Trial (VLST) addresses the critical need for precision in lung cancer diagnostics and the potential for reducing unnecessary radiation exposure in clinical settings. Objectives: To establish a virtual imaging trial (VIT) platform that accurately simulates real-world lung screening trials (LSTs) to assess the diagnostic accuracy of CT and CXR modalities. Design, Setting, and Participants: Utilizing computational models and machine learning algorithms, we created a diverse virtual patient population. The cohort, designed to mirror real-world demographics, was assessed using virtual imaging techniques that reflect historical imaging technologies. Main Outcomes and Measures: The primary outcome was the difference in the Area Under the Curve (AUC) for CT and CXR modalities across lesion types and sizes. Results: The study analyzed 298 CT and 313 CXR simulated images from 313 virtual patients, with a lesion-level AUC of 0.81 (95% CI: 0.78-0.84) for CT and 0.55 (95% CI: 0.53-0.56) for CXR. At the patient level, CT demonstrated an AUC of 0.85 (95% CI: 0.80-0.89), compared to 0.53 (95% CI: 0.47-0.60) for CXR. Subgroup analyses indicated CT's superior performance in detecting homogeneous lesions (AUC of 0.97 for lesion-level) and heterogeneous lesions (AUC of 0.71 for lesion-level) as well as in identifying larger nodules (AUC of 0.98 for nodules > 8 mm). Conclusion and Relevance: The VIT platform validated the superior diagnostic accuracy of CT over CXR, especially for smaller nodules, underscoring its potential to replicate real clinical imaging trials. These findings advocate for the integration of virtual trials in the evaluation and improvement of imaging-based diagnostic tools.
Large Intestine 3D Shape Refinement Using Point Diffusion Models for Digital Phantom Generation
Sep 15, 2023
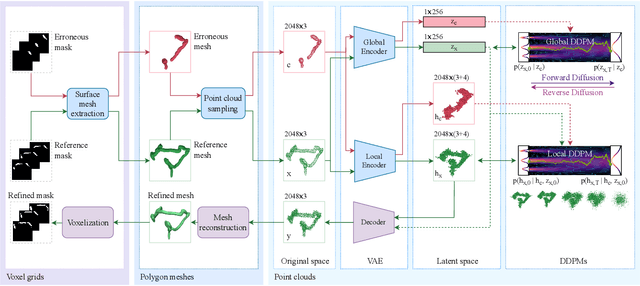
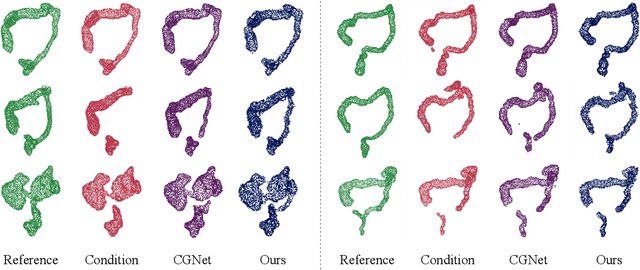
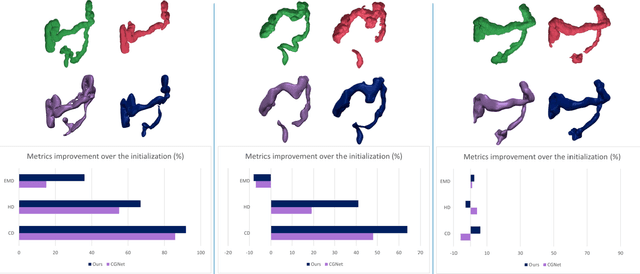
Accurate 3D modeling of human organs plays a crucial role in building computational phantoms for virtual imaging trials. However, generating anatomically plausible reconstructions of organ surfaces from computed tomography scans remains challenging for many structures in the human body. This challenge is particularly evident when dealing with the large intestine. In this study, we leverage recent advancements in geometric deep learning and denoising diffusion probabilistic models to refine the segmentation results of the large intestine. We begin by representing the organ as point clouds sampled from the surface of the 3D segmentation mask. Subsequently, we employ a hierarchical variational autoencoder to obtain global and local latent representations of the organ's shape. We train two conditional denoising diffusion models in the hierarchical latent space to perform shape refinement. To further enhance our method, we incorporate a state-of-the-art surface reconstruction model, allowing us to generate smooth meshes from the obtained complete point clouds. Experimental results demonstrate the effectiveness of our approach in capturing both the global distribution of the organ's shape and its fine details. Our complete refinement pipeline demonstrates remarkable enhancements in surface representation compared to the initial segmentation, reducing the Chamfer distance by 70%, the Hausdorff distance by 32%, and the Earth Mover's distance by 6%. By combining geometric deep learning, denoising diffusion models, and advanced surface reconstruction techniques, our proposed method offers a promising solution for accurately modeling the large intestine's surface and can easily be extended to other anatomical structures.
Data diversity and virtual imaging in AI-based diagnosis: A case study based on COVID-19
Aug 17, 2023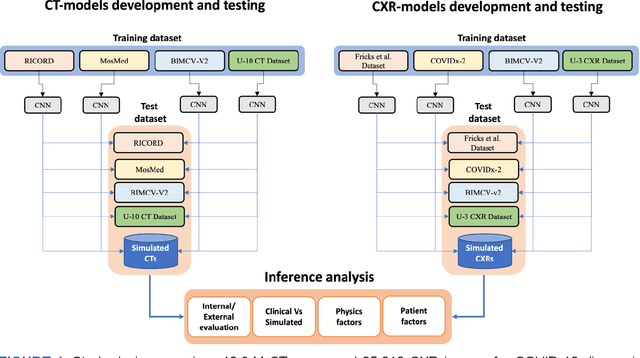
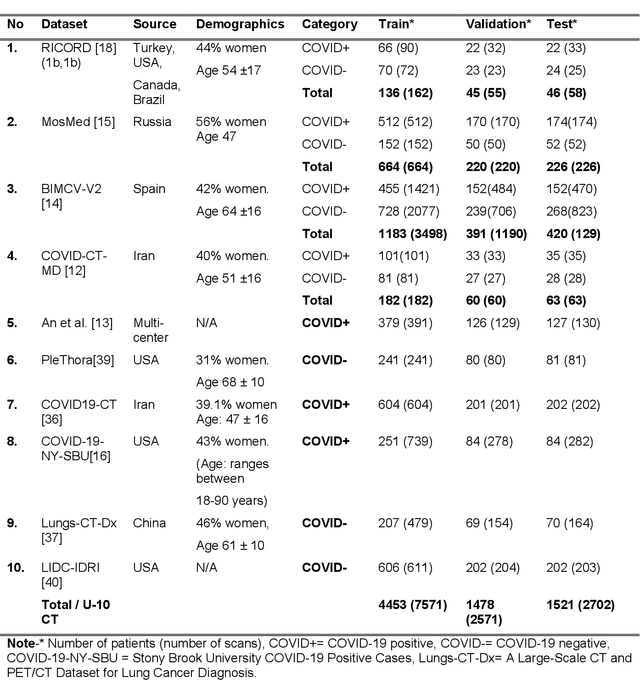
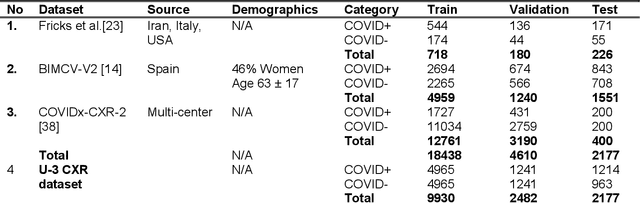
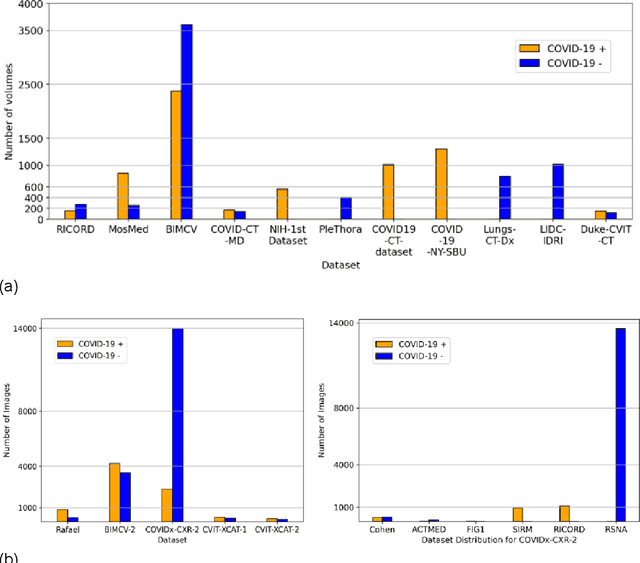
Many studies have investigated deep-learning-based artificial intelligence (AI) models for medical imaging diagnosis of the novel coronavirus (COVID-19), with many reports of near-perfect performance. However, variability in performance and underlying data biases raise concerns about clinical generalizability. This retrospective study involved the development and evaluation of artificial intelligence (AI) models for COVID-19 diagnosis using both diverse clinical and virtually generated medical images. In addition, we conducted a virtual imaging trial to assess how AI performance is affected by several patient- and physics-based factors, including the extent of disease, radiation dose, and imaging modality of computed tomography (CT) and chest radiography (CXR). AI performance was strongly influenced by dataset characteristics including quantity, diversity, and prevalence, leading to poor generalization with up to 20% drop in receiver operating characteristic area under the curve. Model performance on virtual CT and CXR images was comparable to overall results on clinical data. Imaging dose proved to have negligible influence on the results, but the extent of the disease had a marked affect. CT results were consistently superior to those from CXR. Overall, the study highlighted the significant impact of dataset characteristics and disease extent on COVID assessment, and the relevance and potential role of virtual imaging trial techniques on developing effective evaluation of AI algorithms and facilitating translation into diagnostic practice.
Uncertainty Estimation in Deep 2D Echocardiography Segmentation
May 19, 2020


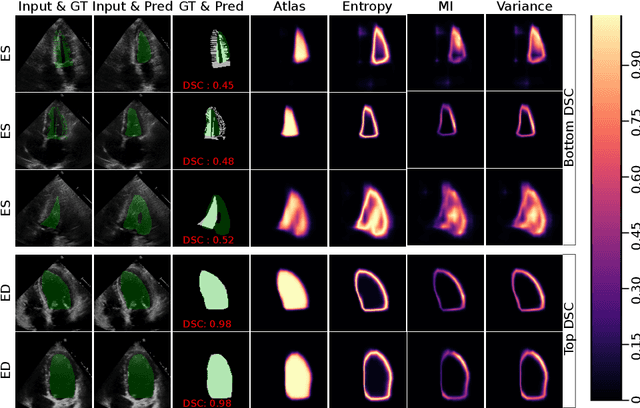
2D echocardiography is the most common imaging modality for cardiovascular diseases. The portability and relatively low-cost nature of Ultrasound (US) enable the US devices needed for performing echocardiography to be made widely available. However, acquiring and interpreting cardiac US images is operator dependent, limiting its use to only places where experts are present. Recently, Deep Learning (DL) has been used in 2D echocardiography for automated view classification, and structure and function assessment. Although these recent works show promise in developing computer-guided acquisition and automated interpretation of echocardiograms, most of these methods do not model and estimate uncertainty which can be important when testing on data coming from a distribution further away from that of the training data. Uncertainty estimates can be beneficial both during the image acquisition phase (by providing real-time feedback to the operator on acquired image's quality), and during automated measurement and interpretation. The performance of uncertainty models and quantification metric may depend on the prediction task and the models being compared. Hence, to gain insight of uncertainty modelling for left ventricular segmentation from US images, we compare three ensembling based uncertainty models quantified using four different metrics (one newly proposed) on state-of-the-art baseline networks using two publicly available echocardiogram datasets. We further demonstrate how uncertainty estimation can be used to automatically reject poor quality images and improve state-of-the-art segmentation results.
Automatic Cobb Angle Detection using Vertebra Detector and Vertebra Corners Regression
Oct 31, 2019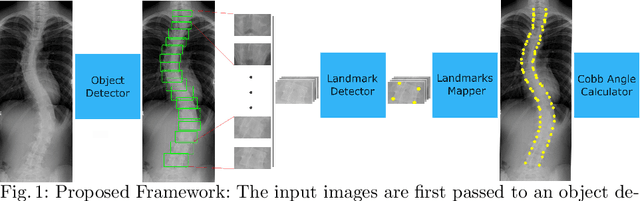

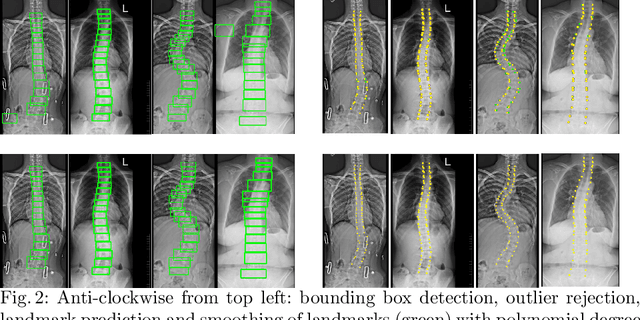
Correct evaluation and treatment of Scoliosis require accurate estimation of spinal curvature. Current gold standard is to manually estimate Cobb Angles in spinal X-ray images which is time consuming and has high inter-rater variability. We propose an automatic method with a novel framework that first detects vertebrae as objects followed by a landmark detector that estimates the 4 landmark corners of each vertebra separately. Cobb Angles are calculated using the slope of each vertebra obtained from the predicted landmarks. For inference on test data, we perform pre and post processings that include cropping, outlier rejection and smoothing of the predicted landmarks. The results were assessed in AASCE MICCAI challenge 2019 which showed a promise with a SMAPE score of 25.69 on the challenge test set.
DSNet: Automatic Dermoscopic Skin Lesion Segmentation
Jul 09, 2019



Automatic segmentation of skin lesion is considered a crucial step in Computer Aided Diagnosis (CAD) for melanoma diagnosis. Despite its significance, skin lesion segmentation remains a challenging task due to their diverse color, texture, and indistinguishable boundaries and forms an open problem. Through this study, we present a new and automatic semantic segmentation network for robust skin lesion segmentation named Dermoscopic Skin Network (DSNet). In order to reduce the number of parameters to make the network lightweight, we used depth-wise separable convolution in lieu of standard convolution to project the learned discriminating features onto the pixel space at different stages of the encoder. Additionally, we implemented U-Net and Fully Convolutional Network (FCN8s) to compare against the proposed DSNet. We evaluate our proposed model on two publicly available datasets, namely ISIC-2017 and PH2. The obtained mean Intersection over Union (mIoU) is 77.5 % and 87.0 % respectively for ISIC-2017 and PH2 datasets which outperformed the ISIC-2017 challenge winner by 1.0 % with respect to mIoU. Our proposed network also outperformed U-Net and FCN8s respectively by 3.6 % and 6.8 % with respect to mIoU on the ISIC-2017 dataset. Our network for skin lesion segmentation outperforms other methods and can provide better segmented masks on two different test datasets which can lead to better performance in melanoma detection. Our trained model along with the source code and predicted masks are made publicly available.