 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVLST: Virtual Lung Screening Trial for Lung Cancer Detection Using Virtual Imaging Trial
Apr 17, 2024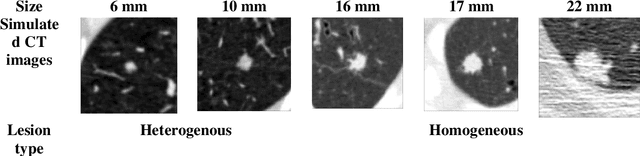

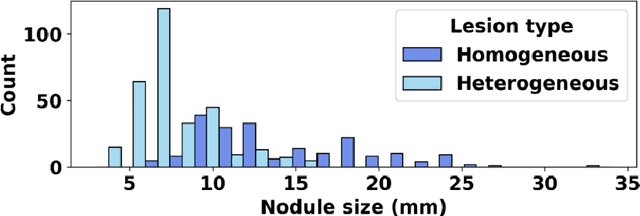
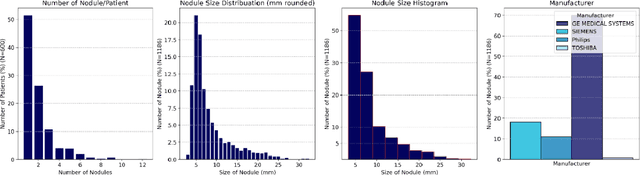
Importance: The efficacy of lung cancer screening can be significantly impacted by the imaging modality used. This Virtual Lung Screening Trial (VLST) addresses the critical need for precision in lung cancer diagnostics and the potential for reducing unnecessary radiation exposure in clinical settings. Objectives: To establish a virtual imaging trial (VIT) platform that accurately simulates real-world lung screening trials (LSTs) to assess the diagnostic accuracy of CT and CXR modalities. Design, Setting, and Participants: Utilizing computational models and machine learning algorithms, we created a diverse virtual patient population. The cohort, designed to mirror real-world demographics, was assessed using virtual imaging techniques that reflect historical imaging technologies. Main Outcomes and Measures: The primary outcome was the difference in the Area Under the Curve (AUC) for CT and CXR modalities across lesion types and sizes. Results: The study analyzed 298 CT and 313 CXR simulated images from 313 virtual patients, with a lesion-level AUC of 0.81 (95% CI: 0.78-0.84) for CT and 0.55 (95% CI: 0.53-0.56) for CXR. At the patient level, CT demonstrated an AUC of 0.85 (95% CI: 0.80-0.89), compared to 0.53 (95% CI: 0.47-0.60) for CXR. Subgroup analyses indicated CT's superior performance in detecting homogeneous lesions (AUC of 0.97 for lesion-level) and heterogeneous lesions (AUC of 0.71 for lesion-level) as well as in identifying larger nodules (AUC of 0.98 for nodules > 8 mm). Conclusion and Relevance: The VIT platform validated the superior diagnostic accuracy of CT over CXR, especially for smaller nodules, underscoring its potential to replicate real clinical imaging trials. These findings advocate for the integration of virtual trials in the evaluation and improvement of imaging-based diagnostic tools.
Large Intestine 3D Shape Refinement Using Point Diffusion Models for Digital Phantom Generation
Sep 15, 2023
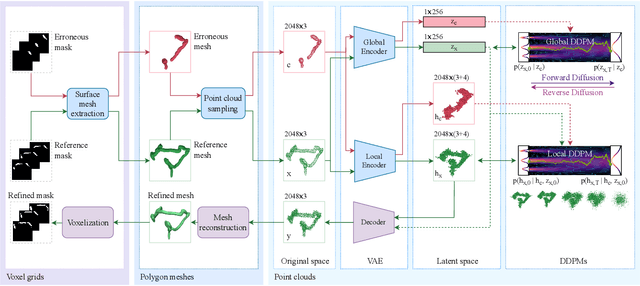
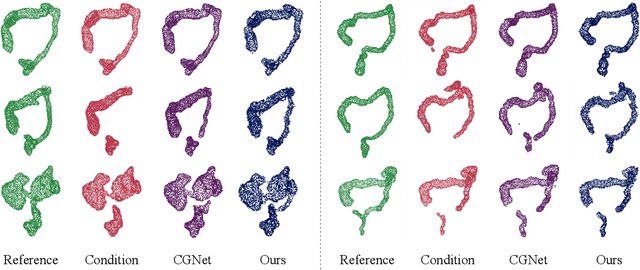
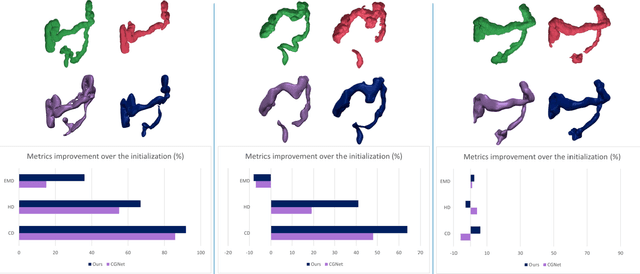
Accurate 3D modeling of human organs plays a crucial role in building computational phantoms for virtual imaging trials. However, generating anatomically plausible reconstructions of organ surfaces from computed tomography scans remains challenging for many structures in the human body. This challenge is particularly evident when dealing with the large intestine. In this study, we leverage recent advancements in geometric deep learning and denoising diffusion probabilistic models to refine the segmentation results of the large intestine. We begin by representing the organ as point clouds sampled from the surface of the 3D segmentation mask. Subsequently, we employ a hierarchical variational autoencoder to obtain global and local latent representations of the organ's shape. We train two conditional denoising diffusion models in the hierarchical latent space to perform shape refinement. To further enhance our method, we incorporate a state-of-the-art surface reconstruction model, allowing us to generate smooth meshes from the obtained complete point clouds. Experimental results demonstrate the effectiveness of our approach in capturing both the global distribution of the organ's shape and its fine details. Our complete refinement pipeline demonstrates remarkable enhancements in surface representation compared to the initial segmentation, reducing the Chamfer distance by 70%, the Hausdorff distance by 32%, and the Earth Mover's distance by 6%. By combining geometric deep learning, denoising diffusion models, and advanced surface reconstruction techniques, our proposed method offers a promising solution for accurately modeling the large intestine's surface and can easily be extended to other anatomical structures.
Data diversity and virtual imaging in AI-based diagnosis: A case study based on COVID-19
Aug 17, 2023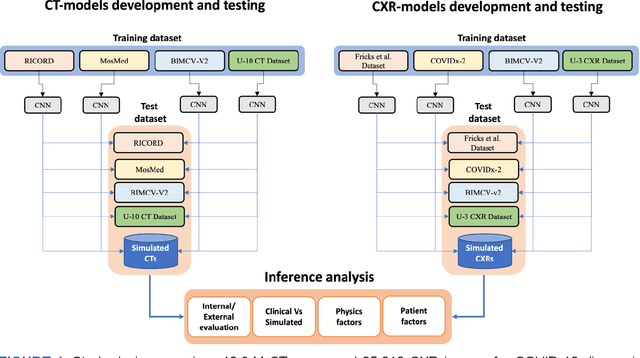
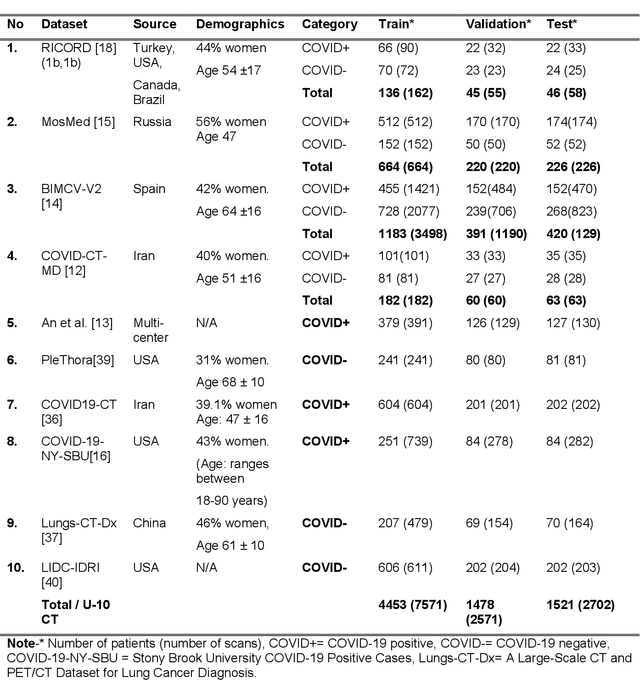
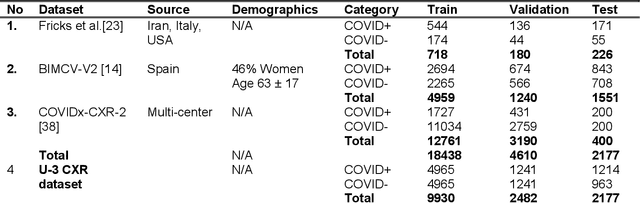
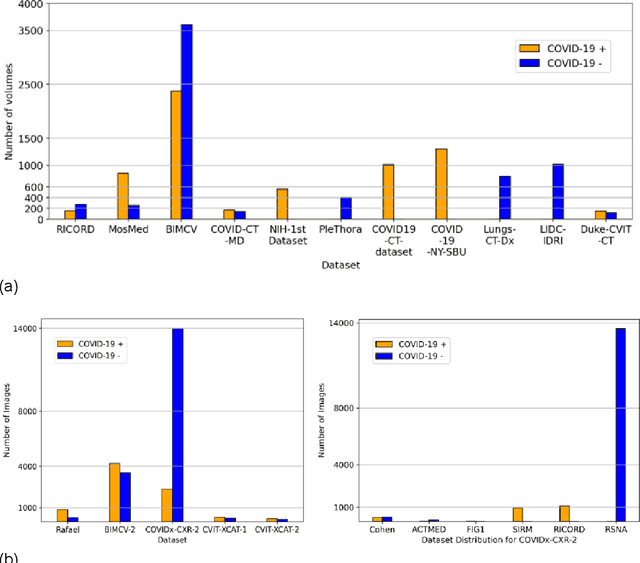
Many studies have investigated deep-learning-based artificial intelligence (AI) models for medical imaging diagnosis of the novel coronavirus (COVID-19), with many reports of near-perfect performance. However, variability in performance and underlying data biases raise concerns about clinical generalizability. This retrospective study involved the development and evaluation of artificial intelligence (AI) models for COVID-19 diagnosis using both diverse clinical and virtually generated medical images. In addition, we conducted a virtual imaging trial to assess how AI performance is affected by several patient- and physics-based factors, including the extent of disease, radiation dose, and imaging modality of computed tomography (CT) and chest radiography (CXR). AI performance was strongly influenced by dataset characteristics including quantity, diversity, and prevalence, leading to poor generalization with up to 20% drop in receiver operating characteristic area under the curve. Model performance on virtual CT and CXR images was comparable to overall results on clinical data. Imaging dose proved to have negligible influence on the results, but the extent of the disease had a marked affect. CT results were consistently superior to those from CXR. Overall, the study highlighted the significant impact of dataset characteristics and disease extent on COVID assessment, and the relevance and potential role of virtual imaging trial techniques on developing effective evaluation of AI algorithms and facilitating translation into diagnostic practice.
Virtual vs. Reality: External Validation of COVID-19 Classifiers using XCAT Phantoms for Chest Computed Tomography
Mar 07, 2022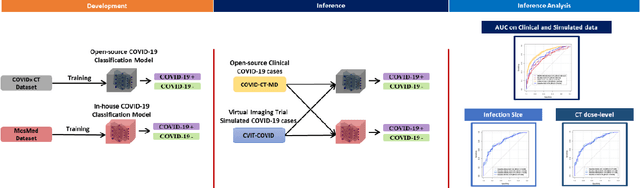

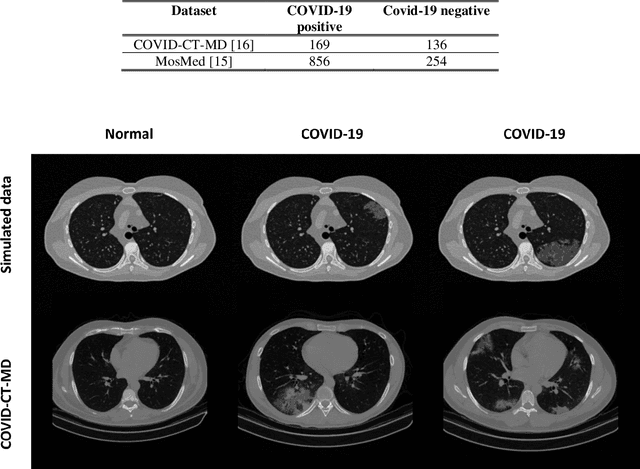
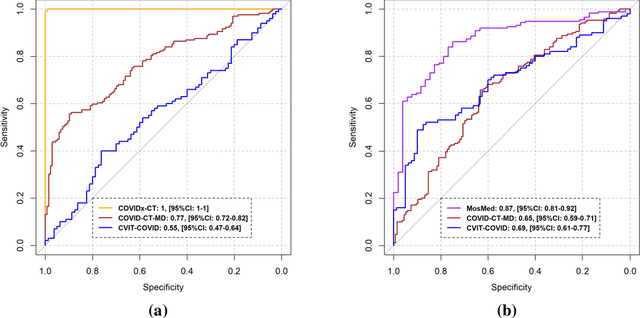
Research studies of artificial intelligence models in medical imaging have been hampered by poor generalization. This problem has been especially concerning over the last year with numerous applications of deep learning for COVID-19 diagnosis. Virtual imaging trials (VITs) could provide a solution for objective evaluation of these models. In this work utilizing the VITs, we created the CVIT-COVID dataset including 180 virtually imaged computed tomography (CT) images from simulated COVID-19 and normal phantom models under different COVID-19 morphology and imaging properties. We evaluated the performance of an open-source, deep-learning model from the University of Waterloo trained with multi-institutional data and an in-house model trained with the open clinical dataset called MosMed. We further validated the model's performance against open clinical data of 305 CT images to understand virtual vs. real clinical data performance. The open-source model was published with nearly perfect performance on the original Waterloo dataset but showed a consistent performance drop in external testing on another clinical dataset (AUC=0.77) and our simulated CVIT-COVID dataset (AUC=0.55). The in-house model achieved an AUC of 0.87 while testing on the internal test set (MosMed test set). However, performance dropped to an AUC of 0.65 and 0.69 when evaluated on clinical and our simulated CVIT-COVID dataset. The VIT framework offered control over imaging conditions, allowing us to show there was no change in performance as CT exposure was changed from 28.5 to 57 mAs. The VIT framework also provided voxel-level ground truth, revealing that performance of in-house model was much higher at AUC=0.87 for diffuse COVID-19 infection size >2.65% lung volume versus AUC=0.52 for focal disease with <2.65% volume. The virtual imaging framework enabled these uniquely rigorous analyses of model performance.