 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeORACLE-CT: Anatomy-Aware Support Pooling for CT Classification
Jun 03, 2026Abdominal CT disease classification is challenging because each scan is a large 3D volume with many possible findings, while diagnostic evidence is often confined to specific organs or anatomical compartments. Most study-level classifiers aggregate encoder features using anatomy-agnostic pooling or attention, creating a mismatch between localized disease evidence and global evidence aggregation. We propose ORACLE--CT, an encoder-agnostic anatomy-aware aggregation framework that uses multi-organ segmentation to define label-specific anatomical supports and restrict attention pooling to relevant regions. The framework supports single-organ, multi-organ union, comparative, localized, and global support strategies. We evaluate ORACLE--CT with three encoder families: DINOv3, I3D--ResNet-121, and the radiology-native Pillar--0 encoder. Models are trained end-to-end on MERLIN and evaluated internally and under frozen external transfer to Duke--Abdomen and AMOS. Compared with global average pooling, support-masked pooling improved MERLIN macro-AUROC/AUPRC from 0.838/0.638 to 0.858/0.676 for DINOv3 and from 0.829/0.617 to 0.848/0.659 for I3D--ResNet-121. On harmonized 10-label external evaluation, DINOv3 improved on Duke--Abdomen from 0.802/0.628 to 0.835/0.683 and on AMOS from 0.742/0.313 to 0.762/0.350, with similar gains for I3D--ResNet-121. For Pillar--0, most gains came from learned attention, with smaller additional benefit from anatomical masking. ORACLE--CT improves discrimination and external robustness while preserving an auditable link between predictions and anatomical evidence.
JANUS: Anatomy-Conditioned Gating for Robust CT Triage Under Distribution Shift
May 13, 2026Automated CT triage requires models that are simultaneously accurate across diverse pathologies and reliable under institutional shift. While Vision Transformers provide strong visual representations, many clinically significant findings are defined by quantitative imaging biomarkers rather than appearance alone. We introduce JANUS, a physiology-guided dual-stream architecture that conditions visual embeddings on macro-radiomic priors via Anatomically Guided Gating. On the MERLIN test set (N=5082), JANUS attains macro-AUROC 0.88 and AUPRC 0.74, outperforming all reproduced baselines. It generalizes to an external dataset N=2000; AUROC 0.87), with the largest gains on findings defined by size and attenuation as well as improved calibration on both datasets. We further quantify prediction suppression using the Physiological Veto Rate (PVR), showing that under domain shift JANUS reduces high-confidence false positives substantially more often than true positives. Together, these results are consistent with physically grounded conditioning that improves both discrimination and reliability in CT triage. Code is made publicly available at github repository https://github.com/lavsendahal/janus and model weights are at https://huggingface.co/lavsendahal/janus.
iTRIALSPACE: Programmable Virtual Lesion Trials for Controlled Evaluation of Lung CT Models
May 07, 2026We introduce iTRIALSPACE, a programmable evaluation framework for controlled assessment of lung CT models. Standard benchmarks are static retrospective collections that entangle lesion size, lobe prevalence, anatomy, and acquisition context, making it difficult to determine what structurally drives model accuracy. iTRIALSPACE addresses this limitation by composing real clinical CTs and lesion profiles into controlled virtual lesion trials through a four-stage pipeline: multidataset nodule profiling, explicit trial specification, anatomy-aware mask insertion, and ControlNet-conditioned CT synthesis. The framework is built on a unified 54-attribute nodule-profile dataset spanning 13,140 annotated nodules from seven public CT sources and instantiated as 13 trial modes. We evaluate iTRIALSPACE in a 55,469-sample Virtual Lesion Study spanning three medical VLMs, four spatialguidance conditions, and three clinical tasks. Across all 13 modes, the synthetic substrate remains within the real-to-real FID baseline, and synthetic performance rankings transfer strongly to real clinical data ($ρ$ = 0.93, p < 10$^{-15}$). Controlled trial modes expose findings unavailable to fixed-distribution benchmarks, including shortcut-driven size prediction collapse under lobe-equalized sampling and hostto-donor variance ratios of 8.9x and 3.3x in twin-cross analysis. These results position iTRIALSPACE as an auditable evaluation infrastructure for controlled, falsifiable testing beyond static retrospective benchmarks.
AbdomenGen: Sequential Volume-Conditioned Diffusion Framework for Abdominal Anatomy Generation
Apr 14, 2026Computational phantoms are widely used in medical imaging research, yet current systems to generate controlled, clinically meaningful anatomical variations remain limited. We present AbdomenGen, a sequential volume-conditioned diffusion framework for controllable abdominal anatomy generation. We introduce the \textbf{Volume Control Scalar (VCS)}, a standardized residual that decouples organ size from body habitus, enabling interpretable volume modulation. Organ masks are synthesized sequentially, conditioning on the body mask and previously generated structures to preserve global anatomical coherence while supporting independent, multi-organ control. Across 11 abdominal organs, the proposed framework achieves strong geometric fidelity (e.g., liver dice $0.83 \pm 0.05$), stable single-organ calibration over $[-3,+3]$ VCS, and disentangled multi-organ modulation. To showcase clinical utility with a hepatomegaly cohort selected from MERLIN, Wasserstein-based VCS selection reduces distributional distance of training data by 73.6\% . These results demonstrate calibrated, distribution-aware anatomical generation suitable for controllable abdominal phantom construction and simulation studies.
STAMP: Selective Task-Aware Mechanism for Text Privacy
Mar 12, 2026We present STAMP (Selective Task-Aware Mechanism for Text Privacy), a new framework for task-aware text privatization that achieves an improved privacy-utility trade-off. STAMP selectively allocates privacy budgets across tokens by jointly considering (i) each token's importance to the downstream task (as measured via a task- or query-specific representation), and (ii) its privacy sensitivity (e.g., names, dates, identifiers). This token-level partitioning enables fine-grained, group-wise control over the level of noise applied to different parts of the input, balancing privacy protection with task relevance. To privatize individual token embeddings, we introduce the polar mechanism, which perturbs only the direction of embeddings on the unit sphere while preserving their magnitude. Decoding is performed via cosine nearest-neighbor search, aligning the perturbation geometry with the decoding geometry. Unlike isotropic noise mechanisms, the polar mechanism maintains semantic neighborhoods in the embedding space and better preserves downstream utility. Experimental evaluations on SQuAD, Yelp, and AG News datasets demonstrate that STAMP, when combined with the normalized polar mechanism, consistently achieves superior privacy-utility trade-offs across varying per-token privacy budgets.
Tri-Reader: An Open-Access, Multi-Stage AI Pipeline for First-Pass Lung Nodule Annotation in Screening CT
Jan 27, 2026Using multiple open-access models trained on public datasets, we developed Tri-Reader, a comprehensive, freely available pipeline that integrates lung segmentation, nodule detection, and malignancy classification into a unified tri-stage workflow. The pipeline is designed to prioritize sensitivity while reducing the candidate burden for annotators. To ensure accuracy and generalizability across diverse practices, we evaluated Tri-Reader on multiple internal and external datasets as compared with expert annotations and dataset-provided reference standards.
Organ-Aware Attention Improves CT Triage and Classification
Jan 19, 2026There is an urgent need for triage and classification of high-volume medical imaging modalities such as computed tomography (CT), which can improve patient care and mitigate radiologist burnout. Study-level CT triage requires calibrated predictions with localized evidence; however, off-the-shelf Vision Language Models (VLM) struggle with 3D anatomy, protocol shifts, and noisy report supervision. This study used the two largest publicly available chest CT datasets: CT-RATE and RADCHEST-CT (held-out external test set). Our carefully tuned supervised baseline (instantiated as a simple Global Average Pooling head) establishes a new supervised state of the art, surpassing all reported linear-probe VLMs. Building on this baseline, we present ORACLE-CT, an encoder-agnostic, organ-aware head that pairs Organ-Masked Attention (mask-restricted, per-organ pooling that yields spatial evidence) with Organ-Scalar Fusion (lightweight fusion of normalized volume and mean-HU cues). In the chest setting, ORACLE-CT masked attention model achieves AUROC 0.86 on CT-RATE; in the abdomen setting, on MERLIN (30 findings), our supervised baseline exceeds a reproduced zero-shot VLM baseline obtained by running publicly released weights through our pipeline, and adding masked attention plus scalar fusion further improves performance to AUROC 0.85. Together, these results deliver state-of-the-art supervised classification performance across both chest and abdomen CT under a unified evaluation protocol. The source code is available at https://github.com/lavsendahal/oracle-ct.
NodMAISI: Nodule-Oriented Medical AI for Synthetic Imaging
Dec 19, 2025Objective: Although medical imaging datasets are increasingly available, abnormal and annotation-intensive findings critical to lung cancer screening, particularly small pulmonary nodules, remain underrepresented and inconsistently curated. Methods: We introduce NodMAISI, an anatomically constrained, nodule-oriented CT synthesis and augmentation framework trained on a unified multi-source cohort (7,042 patients, 8,841 CTs, 14,444 nodules). The framework integrates: (i) a standardized curation and annotation pipeline linking each CT with organ masks and nodule-level annotations, (ii) a ControlNet-conditioned rectified-flow generator built on MAISI-v2's foundational blocks to enforce anatomy- and lesion-consistent synthesis, and (iii) lesion-aware augmentation that perturbs nodule masks (controlled shrinkage) while preserving surrounding anatomy to generate paired CT variants. Results: Across six public test datasets, NodMAISI improved distributional fidelity relative to MAISI-v2 (real-to-synthetic FID range 1.18 to 2.99 vs 1.69 to 5.21). In lesion detectability analysis using a MONAI nodule detector, NodMAISI substantially increased average sensitivity and more closely matched clinical scans (IMD-CT: 0.69 vs 0.39; DLCS24: 0.63 vs 0.20), with the largest gains for sub-centimeter nodules where MAISI-v2 frequently failed to reproduce the conditioned lesion. In downstream nodule-level malignancy classification trained on LUNA25 and externally evaluated on LUNA16, LNDbv4, and DLCS24, NodMAISI augmentation improved AUC by 0.07 to 0.11 at <=20% clinical data and by 0.12 to 0.21 at 10%, consistently narrowing the performance gap under data scarcity.
SYN-LUNGS: Towards Simulating Lung Nodules with Anatomy-Informed Digital Twins for AI Training
Feb 28, 2025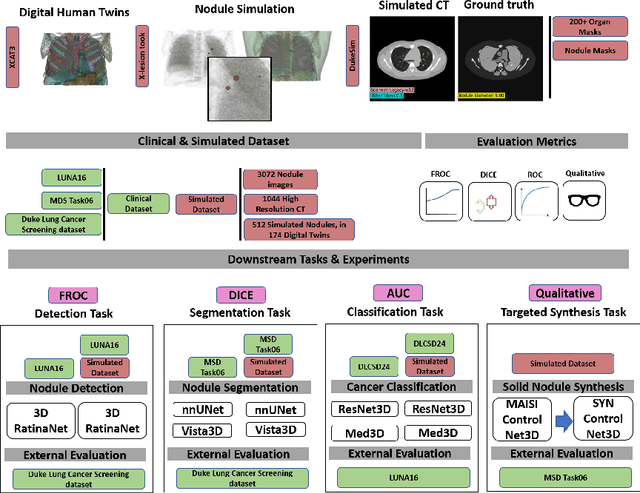
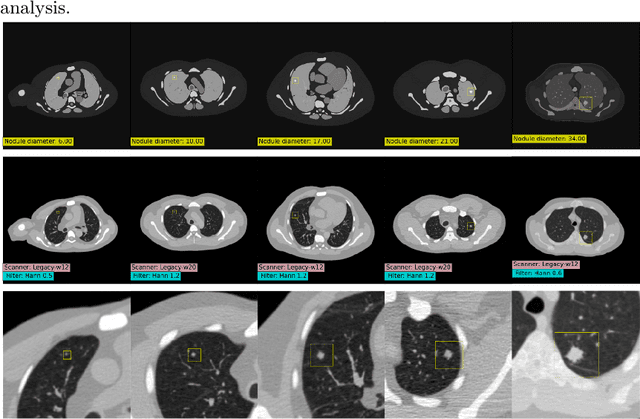
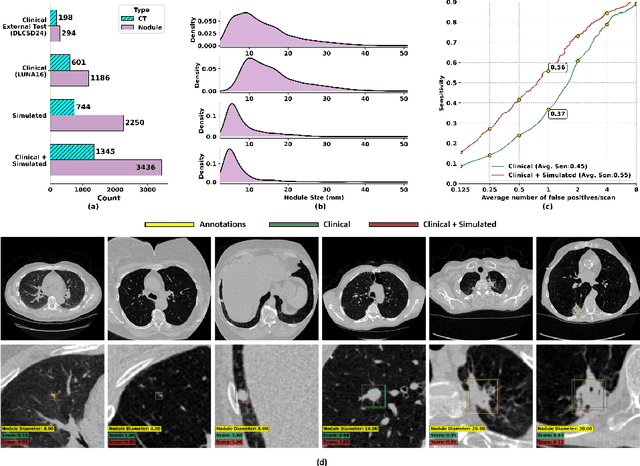
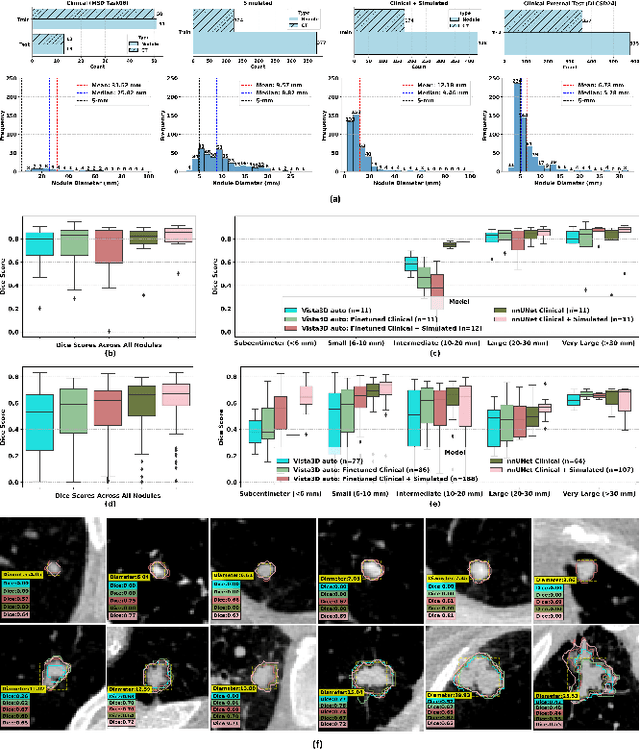
AI models for lung cancer screening are limited by data scarcity, impacting generalizability and clinical applicability. Generative models address this issue but are constrained by training data variability. We introduce SYN-LUNGS, a framework for generating high-quality 3D CT images with detailed annotations. SYN-LUNGS integrates XCAT3 phantoms for digital twin generation, X-Lesions for nodule simulation (varying size, location, and appearance), and DukeSim for CT image formation with vendor and parameter variability. The dataset includes 3,072 nodule images from 1,044 simulated CT scans, with 512 lesions and 174 digital twins. Models trained on clinical + simulated data outperform clinical only models, achieving 10% improvement in detection, 2-9% in segmentation and classification, and enhanced synthesis.By incorporating anatomy-informed simulations, SYN-LUNGS provides a scalable approach for AI model development, particularly in rare disease representation and improving model reliability.
FPN-IAIA-BL: A Multi-Scale Interpretable Deep Learning Model for Classification of Mass Margins in Digital Mammography
Jun 10, 2024



Digital mammography is essential to breast cancer detection, and deep learning offers promising tools for faster and more accurate mammogram analysis. In radiology and other high-stakes environments, uninterpretable ("black box") deep learning models are unsuitable and there is a call in these fields to make interpretable models. Recent work in interpretable computer vision provides transparency to these formerly black boxes by utilizing prototypes for case-based explanations, achieving high accuracy in applications including mammography. However, these models struggle with precise feature localization, reasoning on large portions of an image when only a small part is relevant. This paper addresses this gap by proposing a novel multi-scale interpretable deep learning model for mammographic mass margin classification. Our contribution not only offers an interpretable model with reasoning aligned with radiologist practices, but also provides a general architecture for computer vision with user-configurable prototypes from coarse- to fine-grained prototypes.