 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmbedding Radiomics into Vision Transformers for Multimodal Medical Image Classification
Apr 15, 2025Background: Deep learning has significantly advanced medical image analysis, with Vision Transformers (ViTs) offering a powerful alternative to convolutional models by modeling long-range dependencies through self-attention. However, ViTs are inherently data-intensive and lack domain-specific inductive biases, limiting their applicability in medical imaging. In contrast, radiomics provides interpretable, handcrafted descriptors of tissue heterogeneity but suffers from limited scalability and integration into end-to-end learning frameworks. In this work, we propose the Radiomics-Embedded Vision Transformer (RE-ViT) that combines radiomic features with data-driven visual embeddings within a ViT backbone. Purpose: To develop a hybrid RE-ViT framework that integrates radiomics and patch-wise ViT embeddings through early fusion, enhancing robustness and performance in medical image classification. Methods: Following the standard ViT pipeline, images were divided into patches. For each patch, handcrafted radiomic features were extracted and fused with linearly projected pixel embeddings. The fused representations were normalized, positionally encoded, and passed to the ViT encoder. A learnable [CLS] token aggregated patch-level information for classification. We evaluated RE-ViT on three public datasets (including BUSI, ChestXray2017, and Retinal OCT) using accuracy, macro AUC, sensitivity, and specificity. RE-ViT was benchmarked against CNN-based (VGG-16, ResNet) and hybrid (TransMed) models. Results: RE-ViT achieved state-of-the-art results: on BUSI, AUC=0.950+/-0.011; on ChestXray2017, AUC=0.989+/-0.004; on Retinal OCT, AUC=0.986+/-0.001, which outperforms other comparison models. Conclusions: The RE-ViT framework effectively integrates radiomics with ViT architectures, demonstrating improved performance and generalizability across multimodal medical image classification tasks.
Feature Flow: In-network Feature Flow Estimation for Video Object Detection
Sep 21, 2020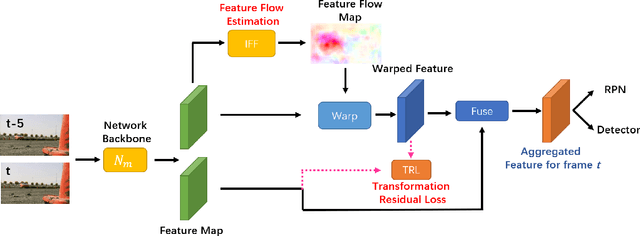
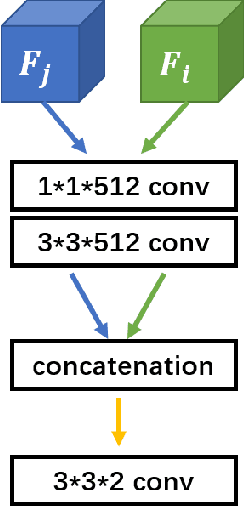
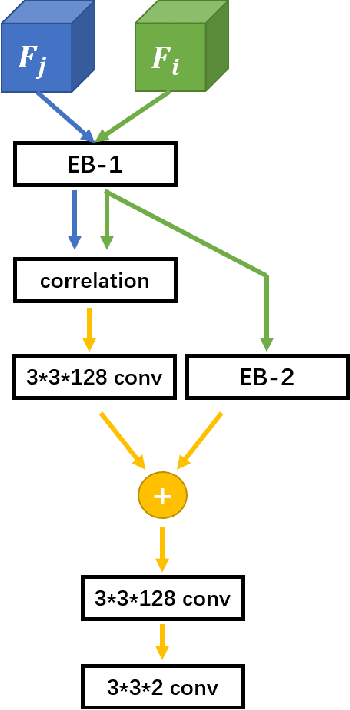
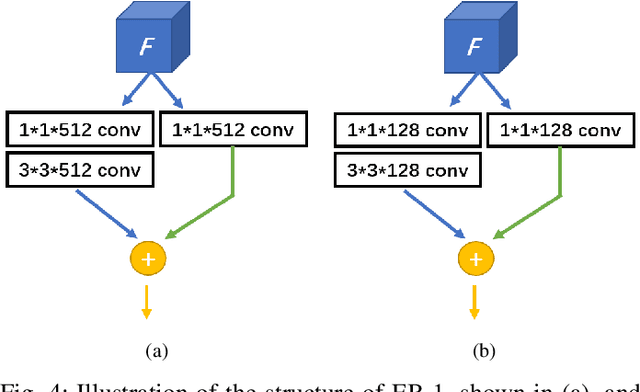
Optical flow, which expresses pixel displacement, is widely used in many computer vision tasks to provide pixel-level motion information. However, with the remarkable progress of the convolutional neural network, recent state-of-the-art approaches are proposed to solve problems directly on feature-level. Since the displacement of feature vector is not consistent to the pixel displacement, a common approach is to:forward optical flow to a neural network and fine-tune this network on the task dataset. With this method,they expect the fine-tuned network to produce tensors encoding feature-level motion information. In this paper, we rethink this de facto paradigm and analyze its drawbacks in the video object detection task. To mitigate these issues, we propose a novel network (IFF-Net) with an \textbf{I}n-network \textbf{F}eature \textbf{F}low estimation module (IFF module) for video object detection. Without resorting pre-training on any additional dataset, our IFF module is able to directly produce \textbf{feature flow} which indicates the feature displacement. Our IFF module consists of a shallow module, which shares the features with the detection branches. This compact design enables our IFF-Net to accurately detect objects, while maintaining a fast inference speed. Furthermore, we propose a transformation residual loss (TRL) based on \textit{self-supervision}, which further improves the performance of our IFF-Net. Our IFF-Net outperforms existing methods and sets a state-of-the-art performance on ImageNet VID.