 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMsFormer: Enabling Robust Predictive Maintenance Services for Industrial Devices
Mar 24, 2026Providing reliable predictive maintenance is a critical industrial AI service essential for ensuring the high availability of manufacturing devices. Existing deep-learning methods present competitive results on such tasks but lack a general service-oriented framework to capture complex dependencies in industrial IoT sensor data. While Transformer-based models show strong sequence modeling capabilities, their direct deployment as robust AI services faces significant bottlenecks. Specifically, streaming sensor data collected in real-world service environments often exhibits multi-scale temporal correlations driven by machine working principles. Besides, the datasets available for training time-to-failure predictive services are typically limited in size. These issues pose significant challenges for directly applying existing models as robust predictive services. To address these challenges, we propose MsFormer, a lightweight Multi-scale Transformer designed as a unified AI service model for reliable industrial predictive maintenance. MsFormer incorporates a Multi-scale Sampling (MS) module and a tailored position encoding mechanism to capture sequential correlations across multi-streaming service data. Additionally, to accommodate data-scarce service environments, MsFormer adopts a lightweight attention mechanism with straightforward pooling operations instead of self-attention. Extensive experiments on real-world datasets demonstrate that the proposed framework achieves significant performance improvements over state-of-the-art methods. Furthermore, MsFormer outperforms across industrial devices and operating conditions, demonstrating strong generalizability while maintaining a highly reliable Quality of Service (QoS).
SimCast: Enhancing Precipitation Nowcasting with Short-to-Long Term Knowledge Distillation
Oct 09, 2025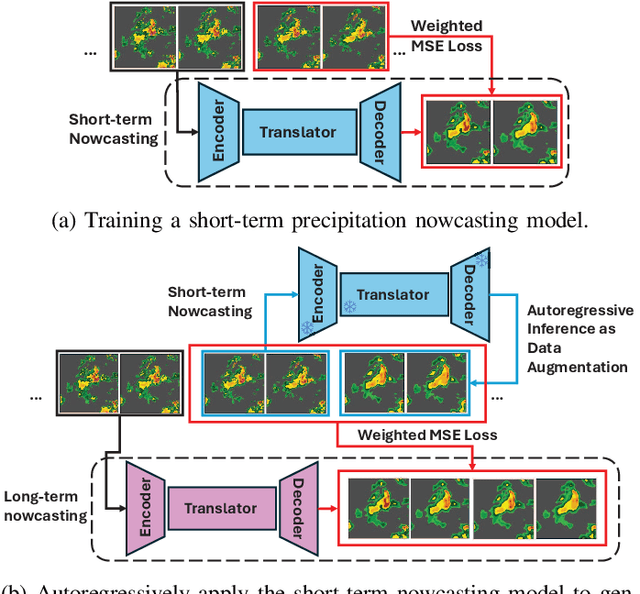
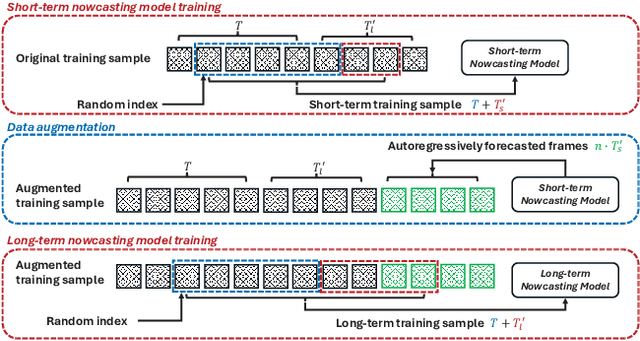
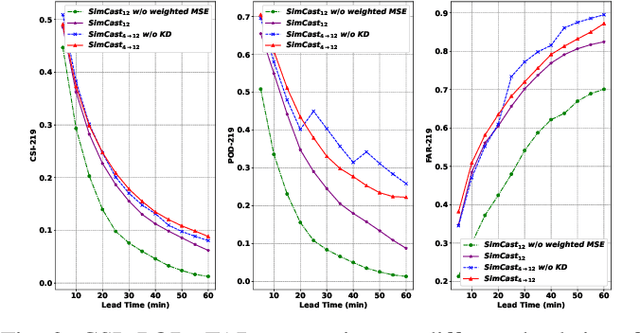
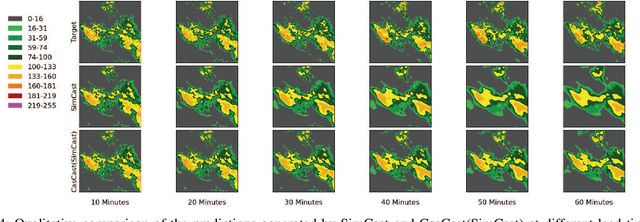
Precipitation nowcasting predicts future radar sequences based on current observations, which is a highly challenging task driven by the inherent complexity of the Earth system. Accurate nowcasting is of utmost importance for addressing various societal needs, including disaster management, agriculture, transportation, and energy optimization. As a complementary to existing non-autoregressive nowcasting approaches, we investigate the impact of prediction horizons on nowcasting models and propose SimCast, a novel training pipeline featuring a short-to-long term knowledge distillation technique coupled with a weighted MSE loss to prioritize heavy rainfall regions. Improved nowcasting predictions can be obtained without introducing additional overhead during inference. As SimCast generates deterministic predictions, we further integrate it into a diffusion-based framework named CasCast, leveraging the strengths from probabilistic models to overcome limitations such as blurriness and distribution shift in deterministic outputs. Extensive experimental results on three benchmark datasets validate the effectiveness of the proposed framework, achieving mean CSI scores of 0.452 on SEVIR, 0.474 on HKO-7, and 0.361 on MeteoNet, which outperforms existing approaches by a significant margin.
* accepted by ICME 2025
LLM-based Knowledge Pruning for Time Series Data Analytics on Edge-computing Devices
Jun 13, 2024Limited by the scale and diversity of time series data, the neural networks trained on time series data often overfit and show unsatisfacotry performances. In comparison, large language models (LLMs) recently exhibit impressive generalization in diverse fields. Although massive LLM based approaches are proposed for time series tasks, these methods require to load the whole LLM in both training and reference. This high computational demands limit practical applications in resource-constrained settings, like edge-computing and IoT devices. To address this issue, we propose Knowledge Pruning (KP), a novel paradigm for time series learning in this paper. For a specific downstream task, we argue that the world knowledge learned by LLMs is much redundant and only the related knowledge termed as "pertinent knowledge" is useful. Unlike other methods, our KP targets to prune the redundant knowledge and only distill the pertinent knowledge into the target model. This reduces model size and computational costs significantly. Additionally, different from existing LLM based approaches, our KP does not require to load the LLM in the process of training and testing, further easing computational burdens. With our proposed KP, a lightweight network can effectively learn the pertinent knowledge, achieving satisfactory performances with a low computation cost. To verify the effectiveness of our KP, two fundamental tasks on edge-computing devices are investigated in our experiments, where eight diverse environments or benchmarks with different networks are used to verify the generalization of our KP. Through experiments, our KP demonstrates effective learning of pertinent knowledge, achieving notable performance improvements in regression (19.7% on average) and classification (up to 13.7%) tasks, showcasing state-of-the-art results.
K-Link: Knowledge-Link Graph from LLMs for Enhanced Representation Learning in Multivariate Time-Series Data
Mar 06, 2024

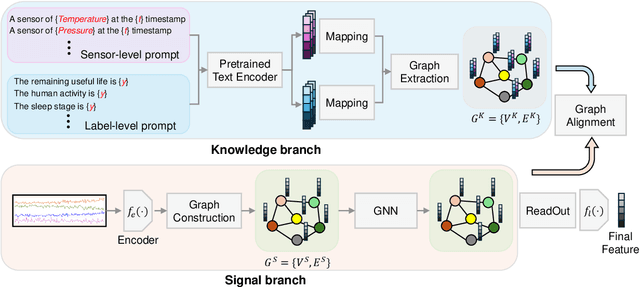

Sourced from various sensors and organized chronologically, Multivariate Time-Series (MTS) data involves crucial spatial-temporal dependencies, e.g., correlations among sensors. To capture these dependencies, Graph Neural Networks (GNNs) have emerged as powerful tools, yet their effectiveness is restricted by the quality of graph construction from MTS data. Typically, existing approaches construct graphs solely from MTS signals, which may introduce bias due to a small training dataset and may not accurately represent underlying dependencies. To address this challenge, we propose a novel framework named K-Link, leveraging Large Language Models (LLMs) to encode extensive general knowledge and thereby providing effective solutions to reduce the bias. Leveraging the knowledge embedded in LLMs, such as physical principles, we extract a \textit{Knowledge-Link graph}, capturing vast semantic knowledge of sensors and the linkage of the sensor-level knowledge. To harness the potential of the knowledge-link graph in enhancing the graph derived from MTS data, we propose a graph alignment module, facilitating the transfer of semantic knowledge within the knowledge-link graph into the MTS-derived graph. By doing so, we can improve the graph quality, ensuring effective representation learning with GNNs for MTS data. Extensive experiments demonstrate the efficacy of our approach for superior performance across various MTS-related downstream tasks.
Unlimited Knowledge Distillation for Action Recognition in the Dark
Aug 18, 2023Dark videos often lose essential information, which causes the knowledge learned by networks is not enough to accurately recognize actions. Existing knowledge assembling methods require massive GPU memory to distill the knowledge from multiple teacher models into a student model. In action recognition, this drawback becomes serious due to much computation required by video process. Constrained by limited computation source, these approaches are infeasible. To address this issue, we propose an unlimited knowledge distillation (UKD) in this paper. Compared with existing knowledge assembling methods, our UKD can effectively assemble different knowledge without introducing high GPU memory consumption. Thus, the number of teaching models for distillation is unlimited. With our UKD, the network's learned knowledge can be remarkably enriched. Our experiments show that the single stream network distilled with our UKD even surpasses a two-stream network. Extensive experiments are conducted on the ARID dataset.
Online Active Proposal Set Generation for Weakly Supervised Object Detection
Jan 20, 2021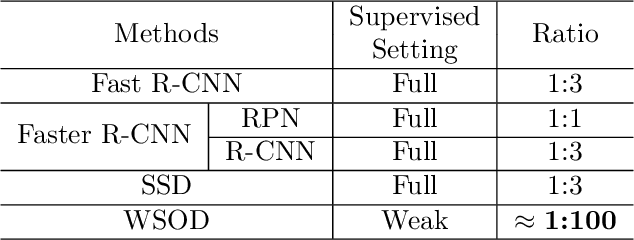

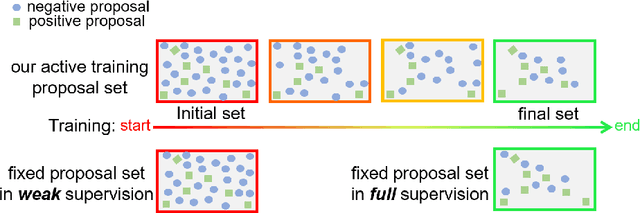
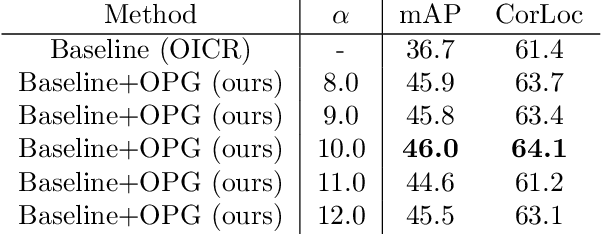
To reduce the manpower consumption on box-level annotations, many weakly supervised object detection methods which only require image-level annotations, have been proposed recently. The training process in these methods is formulated into two steps. They firstly train a neural network under weak supervision to generate pseudo ground truths (PGTs). Then, these PGTs are used to train another network under full supervision. Compared with fully supervised methods, the training process in weakly supervised methods becomes more complex and time-consuming. Furthermore, overwhelming negative proposals are involved at the first step. This is neglected by most methods, which makes the training network biased towards to negative proposals and thus degrades the quality of the PGTs, limiting the training network performance at the second step. Online proposal sampling is an intuitive solution to these issues. However, lacking of adequate labeling, a simple online proposal sampling may make the training network stuck into local minima. To solve this problem, we propose an Online Active Proposal Set Generation (OPG) algorithm. Our OPG algorithm consists of two parts: Dynamic Proposal Constraint (DPC) and Proposal Partition (PP). DPC is proposed to dynamically determine different proposal sampling strategy according to the current training state. PP is used to score each proposal, part proposals into different sets and generate an active proposal set for the network optimization. Through experiments, our proposed OPG shows consistent and significant improvement on both datasets PASCAL VOC 2007 and 2012, yielding comparable performance to the state-of-the-art results.
Feature Flow: In-network Feature Flow Estimation for Video Object Detection
Sep 21, 2020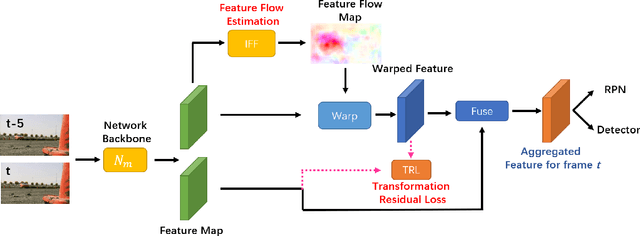
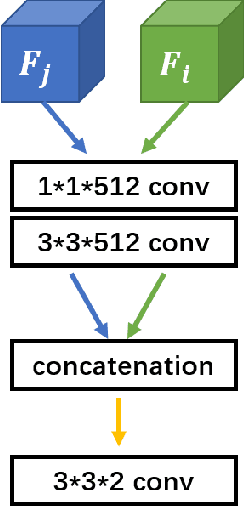
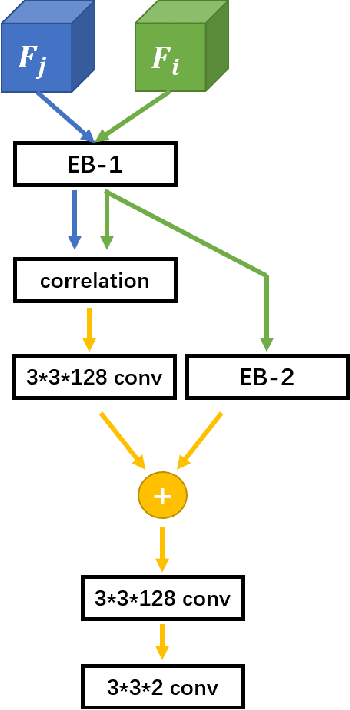
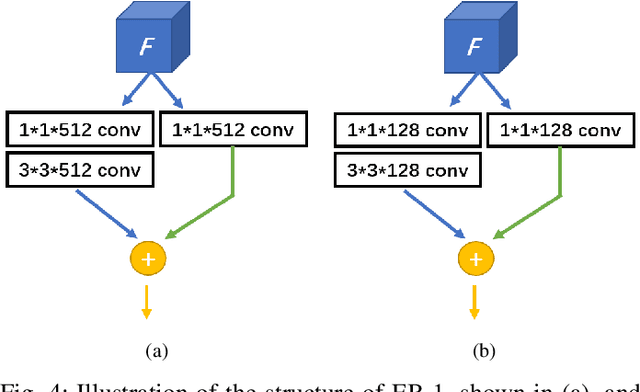
Optical flow, which expresses pixel displacement, is widely used in many computer vision tasks to provide pixel-level motion information. However, with the remarkable progress of the convolutional neural network, recent state-of-the-art approaches are proposed to solve problems directly on feature-level. Since the displacement of feature vector is not consistent to the pixel displacement, a common approach is to:forward optical flow to a neural network and fine-tune this network on the task dataset. With this method,they expect the fine-tuned network to produce tensors encoding feature-level motion information. In this paper, we rethink this de facto paradigm and analyze its drawbacks in the video object detection task. To mitigate these issues, we propose a novel network (IFF-Net) with an \textbf{I}n-network \textbf{F}eature \textbf{F}low estimation module (IFF module) for video object detection. Without resorting pre-training on any additional dataset, our IFF module is able to directly produce \textbf{feature flow} which indicates the feature displacement. Our IFF module consists of a shallow module, which shares the features with the detection branches. This compact design enables our IFF-Net to accurately detect objects, while maintaining a fast inference speed. Furthermore, we propose a transformation residual loss (TRL) based on \textit{self-supervision}, which further improves the performance of our IFF-Net. Our IFF-Net outperforms existing methods and sets a state-of-the-art performance on ImageNet VID.