 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemantic Surgery: Zero-Shot Concept Erasure in Diffusion Models
Oct 26, 2025Concept erasure in text-to-image diffusion models is crucial for mitigating harmful content, yet existing methods often compromise generative quality. We introduce Semantic Surgery, a novel training-free, zero-shot framework for concept erasure that operates directly on text embeddings before the diffusion process. It dynamically estimates the presence of target concepts in a prompt and performs a calibrated vector subtraction to neutralize their influence at the source, enhancing both erasure completeness and locality. The framework includes a Co-Occurrence Encoding module for robust multi-concept erasure and a visual feedback loop to address latent concept persistence. As a training-free method, Semantic Surgery adapts dynamically to each prompt, ensuring precise interventions. Extensive experiments on object, explicit content, artistic style, and multi-celebrity erasure tasks show our method significantly outperforms state-of-the-art approaches. We achieve superior completeness and robustness while preserving locality and image quality (e.g., 93.58 H-score in object erasure, reducing explicit content to just 1 instance, and 8.09 H_a in style erasure with no quality degradation). This robustness also allows our framework to function as a built-in threat detection system, offering a practical solution for safer text-to-image generation.
Minute-Long Videos with Dual Parallelisms
May 29, 2025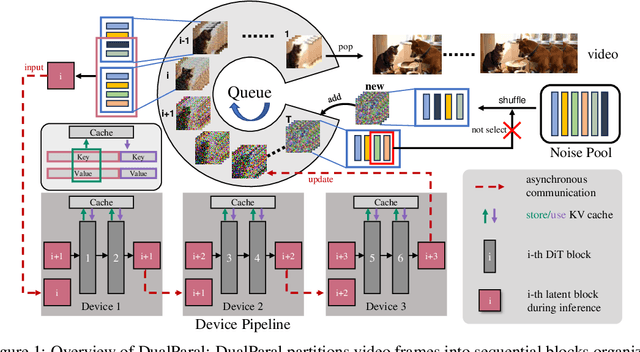



Diffusion Transformer (DiT)-based video diffusion models generate high-quality videos at scale but incur prohibitive processing latency and memory costs for long videos. To address this, we propose a novel distributed inference strategy, termed DualParal. The core idea is that, instead of generating an entire video on a single GPU, we parallelize both temporal frames and model layers across GPUs. However, a naive implementation of this division faces a key limitation: since diffusion models require synchronized noise levels across frames, this implementation leads to the serialization of original parallelisms. We leverage a block-wise denoising scheme to handle this. Namely, we process a sequence of frame blocks through the pipeline with progressively decreasing noise levels. Each GPU handles a specific block and layer subset while passing previous results to the next GPU, enabling asynchronous computation and communication. To further optimize performance, we incorporate two key enhancements. Firstly, a feature cache is implemented on each GPU to store and reuse features from the prior block as context, minimizing inter-GPU communication and redundant computation. Secondly, we employ a coordinated noise initialization strategy, ensuring globally consistent temporal dynamics by sharing initial noise patterns across GPUs without extra resource costs. Together, these enable fast, artifact-free, and infinitely long video generation. Applied to the latest diffusion transformer video generator, our method efficiently produces 1,025-frame videos with up to 6.54$\times$ lower latency and 1.48$\times$ lower memory cost on 8$\times$RTX 4090 GPUs.
Robust Unsupervised Domain Adaptation for 3D Point Cloud Segmentation Under Source Adversarial Attacks
Apr 03, 2025Unsupervised domain adaptation (UDA) frameworks have shown good generalization capabilities for 3D point cloud semantic segmentation models on clean data. However, existing works overlook adversarial robustness when the source domain itself is compromised. To comprehensively explore the robustness of the UDA frameworks, we first design a stealthy adversarial point cloud generation attack that can significantly contaminate datasets with only minor perturbations to the point cloud surface. Based on that, we propose a novel dataset, AdvSynLiDAR, comprising synthesized contaminated LiDAR point clouds. With the generated corrupted data, we further develop the Adversarial Adaptation Framework (AAF) as the countermeasure. Specifically, by extending the key point sensitive (KPS) loss towards the Robust Long-Tail loss (RLT loss) and utilizing a decoder branch, our approach enables the model to focus on long-tail classes during the pre-training phase and leverages high-confidence decoded point cloud information to restore point cloud structures during the adaptation phase. We evaluated our AAF method on the AdvSynLiDAR dataset, where the results demonstrate that our AAF method can mitigate performance degradation under source adversarial perturbations for UDA in the 3D point cloud segmentation application.
ProtoGuard-guided PROPEL: Class-Aware Prototype Enhancement and Progressive Labeling for Incremental 3D Point Cloud Segmentation
Apr 02, 2025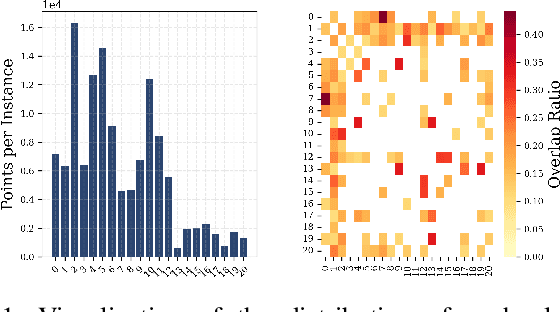



3D point cloud semantic segmentation technology has been widely used. However, in real-world scenarios, the environment is evolving. Thus, offline-trained segmentation models may lead to catastrophic forgetting of previously seen classes. Class-incremental learning (CIL) is designed to address the problem of catastrophic forgetting. While point clouds are common, we observe high similarity and unclear boundaries between different classes. Meanwhile, they are known to be imbalanced in class distribution. These lead to issues including misclassification between similar classes and the long-tail problem, which have not been adequately addressed in previous CIL methods. We thus propose ProtoGuard and PROPEL (Progressive Refinement Of PsEudo-Labels). In the base-class training phase, ProtoGuard maintains geometric and semantic prototypes for each class, which are combined into prototype features using an attention mechanism. In the novel-class training phase, PROPEL inherits the base feature extractor and classifier, guiding pseudo-label propagation and updates based on density distribution and semantic similarity. Extensive experiments show that our approach achieves remarkable results on both the S3DIS and ScanNet datasets, improving the mIoU of 3D point cloud segmentation by a maximum of 20.39% under the 5-step CIL scenario on S3DIS.
Overlap-Aware Feature Learning for Robust Unsupervised Domain Adaptation for 3D Semantic Segmentation
Apr 02, 2025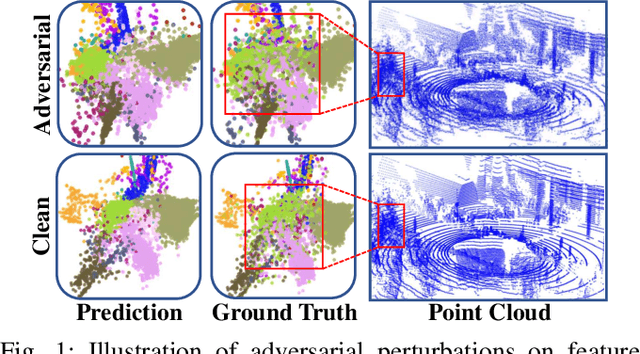
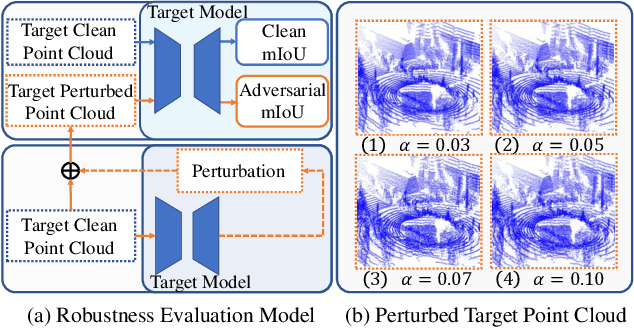


3D point cloud semantic segmentation (PCSS) is a cornerstone for environmental perception in robotic systems and autonomous driving, enabling precise scene understanding through point-wise classification. While unsupervised domain adaptation (UDA) mitigates label scarcity in PCSS, existing methods critically overlook the inherent vulnerability to real-world perturbations (e.g., snow, fog, rain) and adversarial distortions. This work first identifies two intrinsic limitations that undermine current PCSS-UDA robustness: (a) unsupervised features overlap from unaligned boundaries in shared-class regions and (b) feature structure erosion caused by domain-invariant learning that suppresses target-specific patterns. To address the proposed problems, we propose a tripartite framework consisting of: 1) a robustness evaluation model quantifying resilience against adversarial attack/corruption types through robustness metrics; 2) an invertible attention alignment module (IAAM) enabling bidirectional domain mapping while preserving discriminative structure via attention-guided overlap suppression; and 3) a contrastive memory bank with quality-aware contrastive learning that progressively refines pseudo-labels with feature quality for more discriminative representations. Extensive experiments on SynLiDAR-to-SemanticPOSS adaptation demonstrate a maximum mIoU improvement of 14.3\% under adversarial attack.
EverAdapt: Continuous Adaptation for Dynamic Machine Fault Diagnosis Environments
Jul 24, 2024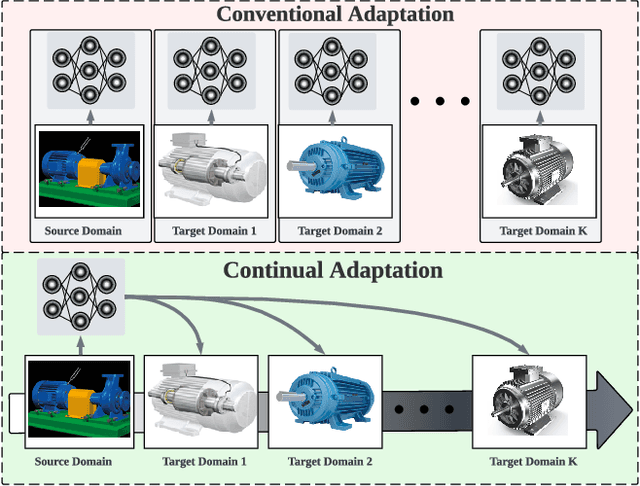
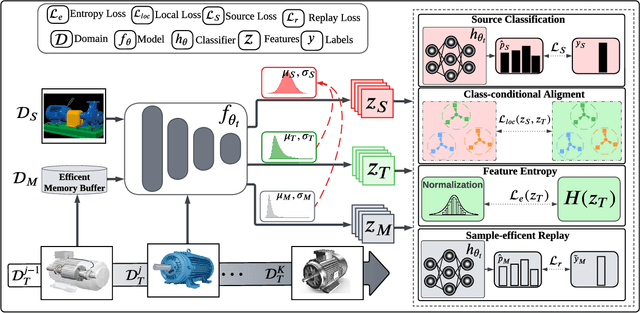
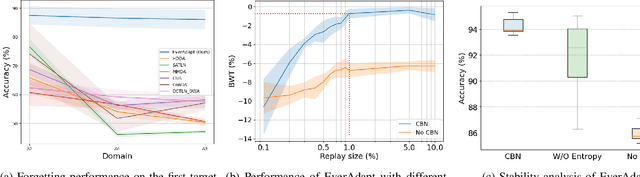
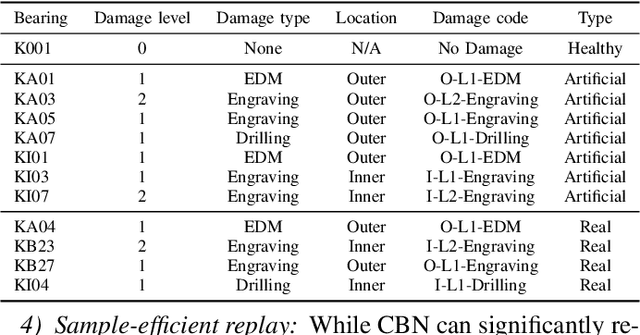
Unsupervised Domain Adaptation (UDA) has emerged as a key solution in data-driven fault diagnosis, addressing domain shift where models underperform in changing environments. However, under the realm of continually changing environments, UDA tends to underperform on previously seen domains when adapting to new ones - a problem known as catastrophic forgetting. To address this limitation, we introduce the EverAdapt framework, specifically designed for continuous model adaptation in dynamic environments. Central to EverAdapt is a novel Continual Batch Normalization (CBN), which leverages source domain statistics as a reference point to standardize feature representations across domains. EverAdapt not only retains statistical information from previous domains but also adapts effectively to new scenarios. Complementing CBN, we design a class-conditional domain alignment module for effective integration of target domains, and a Sample-efficient Replay strategy to reinforce memory retention. Experiments on real-world datasets demonstrate EverAdapt superiority in maintaining robust fault diagnosis in dynamic environments. Our code is available: https://github.com/mohamedr002/EverAdapt
LLM-based Knowledge Pruning for Time Series Data Analytics on Edge-computing Devices
Jun 13, 2024Limited by the scale and diversity of time series data, the neural networks trained on time series data often overfit and show unsatisfacotry performances. In comparison, large language models (LLMs) recently exhibit impressive generalization in diverse fields. Although massive LLM based approaches are proposed for time series tasks, these methods require to load the whole LLM in both training and reference. This high computational demands limit practical applications in resource-constrained settings, like edge-computing and IoT devices. To address this issue, we propose Knowledge Pruning (KP), a novel paradigm for time series learning in this paper. For a specific downstream task, we argue that the world knowledge learned by LLMs is much redundant and only the related knowledge termed as "pertinent knowledge" is useful. Unlike other methods, our KP targets to prune the redundant knowledge and only distill the pertinent knowledge into the target model. This reduces model size and computational costs significantly. Additionally, different from existing LLM based approaches, our KP does not require to load the LLM in the process of training and testing, further easing computational burdens. With our proposed KP, a lightweight network can effectively learn the pertinent knowledge, achieving satisfactory performances with a low computation cost. To verify the effectiveness of our KP, two fundamental tasks on edge-computing devices are investigated in our experiments, where eight diverse environments or benchmarks with different networks are used to verify the generalization of our KP. Through experiments, our KP demonstrates effective learning of pertinent knowledge, achieving notable performance improvements in regression (19.7% on average) and classification (up to 13.7%) tasks, showcasing state-of-the-art results.
Diffusion Model is a Good Pose Estimator from 3D RF-Vision
Mar 24, 2024Human pose estimation (HPE) from Radio Frequency vision (RF-vision) performs human sensing using RF signals that penetrate obstacles without revealing privacy (e.g., facial information). Recently, mmWave radar has emerged as a promising RF-vision sensor, providing radar point clouds by processing RF signals. However, the mmWave radar has a limited resolution with severe noise, leading to inaccurate and inconsistent human pose estimation. This work proposes mmDiff, a novel diffusion-based pose estimator tailored for noisy radar data. Our approach aims to provide reliable guidance as conditions to diffusion models. Two key challenges are addressed by mmDiff: (1) miss-detection of parts of human bodies, which is addressed by a module that isolates feature extraction from different body parts, and (2) signal inconsistency due to environmental interference, which is tackled by incorporating prior knowledge of body structure and motion. Several modules are designed to achieve these goals, whose features work as the conditions for the subsequent diffusion model, eliminating the miss-detection and instability of HPE based on RF-vision. Extensive experiments demonstrate that mmDiff outperforms existing methods significantly, achieving state-of-the-art performances on public datasets.
Reliable Spatial-Temporal Voxels For Multi-Modal Test-Time Adaptation
Mar 15, 2024Multi-modal test-time adaptation (MM-TTA) is proposed to adapt models to an unlabeled target domain by leveraging the complementary multi-modal inputs in an online manner. Previous MM-TTA methods rely on predictions of cross-modal information in each input frame, while they ignore the fact that predictions of geometric neighborhoods within consecutive frames are highly correlated, leading to unstable predictions across time. To fulfill this gap, we propose ReLiable Spatial-temporal Voxels (Latte), an MM-TTA method that leverages reliable cross-modal spatial-temporal correspondences for multi-modal 3D segmentation. Motivated by the fact that reliable predictions should be consistent with their spatial-temporal correspondences, Latte aggregates consecutive frames in a slide window manner and constructs ST voxel to capture temporally local prediction consistency for each modality. After filtering out ST voxels with high ST entropy, Latte conducts cross-modal learning for each point and pixel by attending to those with reliable and consistent predictions among both spatial and temporal neighborhoods. Experimental results show that Latte achieves state-of-the-art performance on three different MM-TTA benchmarks compared to previous MM-TTA or TTA methods.
MaskFi: Unsupervised Learning of WiFi and Vision Representations for Multimodal Human Activity Recognition
Feb 29, 2024



Human activity recognition (HAR) has been playing an increasingly important role in various domains such as healthcare, security monitoring, and metaverse gaming. Though numerous HAR methods based on computer vision have been developed to show prominent performance, they still suffer from poor robustness in adverse visual conditions in particular low illumination, which motivates WiFi-based HAR to serve as a good complementary modality. Existing solutions using WiFi and vision modalities rely on massive labeled data that are very cumbersome to collect. In this paper, we propose a novel unsupervised multimodal HAR solution, MaskFi, that leverages only unlabeled video and WiFi activity data for model training. We propose a new algorithm, masked WiFi-vision modeling (MI2M), that enables the model to learn cross-modal and single-modal features by predicting the masked sections in representation learning. Benefiting from our unsupervised learning procedure, the network requires only a small amount of annotated data for finetuning and can adapt to the new environment with better performance. We conduct extensive experiments on two WiFi-vision datasets collected in-house, and our method achieves human activity recognition and human identification in terms of both robustness and accuracy.