 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeM4Human: A Large-Scale Multimodal mmWave Radar Benchmark for Human Mesh Reconstruction
Dec 17, 2025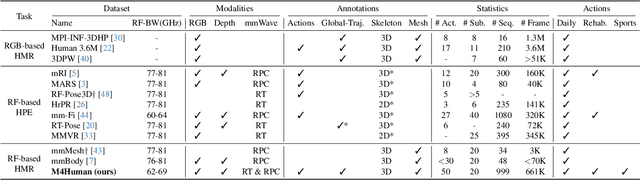
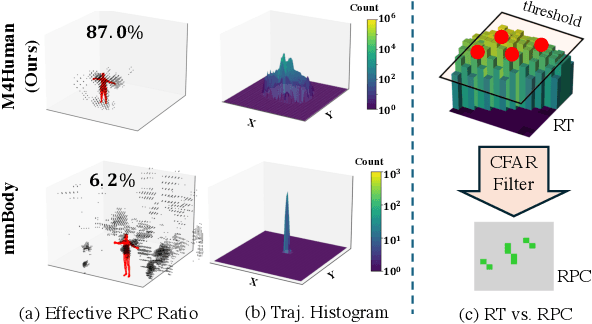

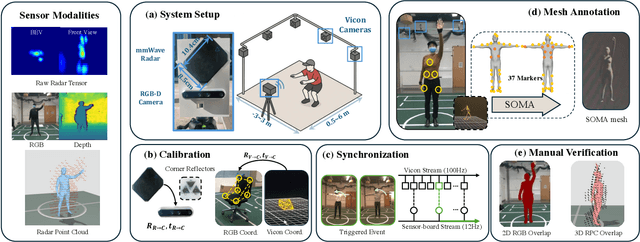
Human mesh reconstruction (HMR) provides direct insights into body-environment interaction, which enables various immersive applications. While existing large-scale HMR datasets rely heavily on line-of-sight RGB input, vision-based sensing is limited by occlusion, lighting variation, and privacy concerns. To overcome these limitations, recent efforts have explored radio-frequency (RF) mmWave radar for privacy-preserving indoor human sensing. However, current radar datasets are constrained by sparse skeleton labels, limited scale, and simple in-place actions. To advance the HMR research community, we introduce M4Human, the current largest-scale (661K-frame) ($9\times$ prior largest) multimodal benchmark, featuring high-resolution mmWave radar, RGB, and depth data. M4Human provides both raw radar tensors (RT) and processed radar point clouds (RPC) to enable research across different levels of RF signal granularity. M4Human includes high-quality motion capture (MoCap) annotations with 3D meshes and global trajectories, and spans 20 subjects and 50 diverse actions, including in-place, sit-in-place, and free-space sports or rehabilitation movements. We establish benchmarks on both RT and RPC modalities, as well as multimodal fusion with RGB-D modalities. Extensive results highlight the significance of M4Human for radar-based human modeling while revealing persistent challenges under fast, unconstrained motion. The dataset and code will be released after the paper publication.
Generative Dataset Distillation using Min-Max Diffusion Model
Mar 24, 2025In this paper, we address the problem of generative dataset distillation that utilizes generative models to synthesize images. The generator may produce any number of images under a preserved evaluation time. In this work, we leverage the popular diffusion model as the generator to compute a surrogate dataset, boosted by a min-max loss to control the dataset's diversity and representativeness during training. However, the diffusion model is time-consuming when generating images, as it requires an iterative generation process. We observe a critical trade-off between the number of image samples and the image quality controlled by the diffusion steps and propose Diffusion Step Reduction to achieve optimal performance. This paper details our comprehensive method and its performance. Our model achieved $2^{nd}$ place in the generative track of \href{https://www.dd-challenge.com/#/}{The First Dataset Distillation Challenge of ECCV2024}, demonstrating its superior performance.
Diffusion Model is a Good Pose Estimator from 3D RF-Vision
Mar 24, 2024Human pose estimation (HPE) from Radio Frequency vision (RF-vision) performs human sensing using RF signals that penetrate obstacles without revealing privacy (e.g., facial information). Recently, mmWave radar has emerged as a promising RF-vision sensor, providing radar point clouds by processing RF signals. However, the mmWave radar has a limited resolution with severe noise, leading to inaccurate and inconsistent human pose estimation. This work proposes mmDiff, a novel diffusion-based pose estimator tailored for noisy radar data. Our approach aims to provide reliable guidance as conditions to diffusion models. Two key challenges are addressed by mmDiff: (1) miss-detection of parts of human bodies, which is addressed by a module that isolates feature extraction from different body parts, and (2) signal inconsistency due to environmental interference, which is tackled by incorporating prior knowledge of body structure and motion. Several modules are designed to achieve these goals, whose features work as the conditions for the subsequent diffusion model, eliminating the miss-detection and instability of HPE based on RF-vision. Extensive experiments demonstrate that mmDiff outperforms existing methods significantly, achieving state-of-the-art performances on public datasets.