 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUniFault: A Fault Diagnosis Foundation Model from Bearing Data
Apr 02, 2025Machine fault diagnosis (FD) is a critical task for predictive maintenance, enabling early fault detection and preventing unexpected failures. Despite its importance, existing FD models are operation-specific with limited generalization across diverse datasets. Foundation models (FM) have demonstrated remarkable potential in both visual and language domains, achieving impressive generalization capabilities even with minimal data through few-shot or zero-shot learning. However, translating these advances to FD presents unique hurdles. Unlike the large-scale, cohesive datasets available for images and text, FD datasets are typically smaller and more heterogeneous, with significant variations in sampling frequencies and the number of channels across different systems and applications. This heterogeneity complicates the design of a universal architecture capable of effectively processing such diverse data while maintaining robust feature extraction and learning capabilities. In this paper, we introduce UniFault, a foundation model for fault diagnosis that systematically addresses these issues. Specifically, the model incorporates a comprehensive data harmonization pipeline featuring two key innovations. First, a unification scheme transforms multivariate inputs into standardized univariate sequences while retaining local inter-channel relationships. Second, a novel cross-domain temporal fusion strategy mitigates distribution shifts and enriches sample diversity and count, improving the model generalization across varying conditions. UniFault is pretrained on over 9 billion data points spanning diverse FD datasets, enabling superior few-shot performance. Extensive experiments on real-world FD datasets demonstrate that UniFault achieves SoTA performance, setting a new benchmark for fault diagnosis models and paving the way for more scalable and robust predictive maintenance solutions.
EverAdapt: Continuous Adaptation for Dynamic Machine Fault Diagnosis Environments
Jul 24, 2024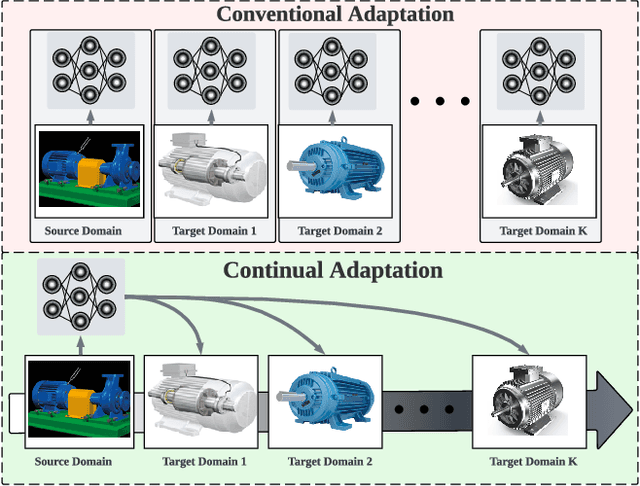
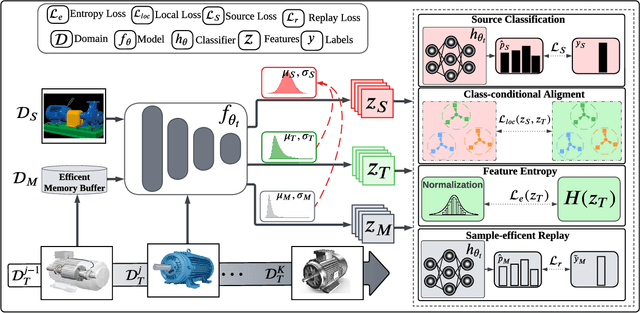
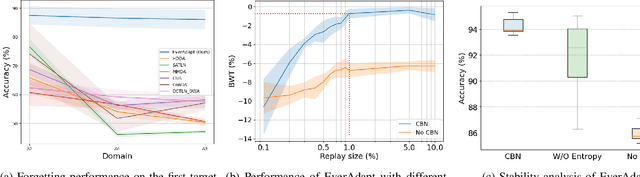
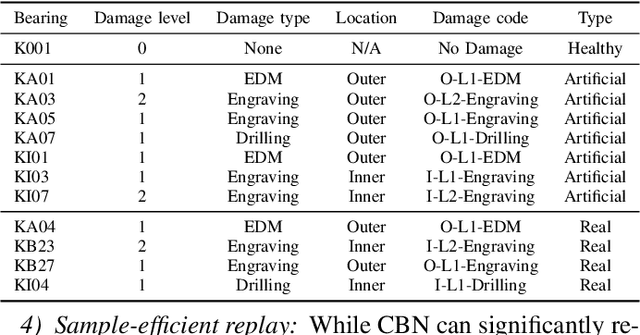
Unsupervised Domain Adaptation (UDA) has emerged as a key solution in data-driven fault diagnosis, addressing domain shift where models underperform in changing environments. However, under the realm of continually changing environments, UDA tends to underperform on previously seen domains when adapting to new ones - a problem known as catastrophic forgetting. To address this limitation, we introduce the EverAdapt framework, specifically designed for continuous model adaptation in dynamic environments. Central to EverAdapt is a novel Continual Batch Normalization (CBN), which leverages source domain statistics as a reference point to standardize feature representations across domains. EverAdapt not only retains statistical information from previous domains but also adapts effectively to new scenarios. Complementing CBN, we design a class-conditional domain alignment module for effective integration of target domains, and a Sample-efficient Replay strategy to reinforce memory retention. Experiments on real-world datasets demonstrate EverAdapt superiority in maintaining robust fault diagnosis in dynamic environments. Our code is available: https://github.com/mohamedr002/EverAdapt