 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Source Retrieval and Reasoning for Legal Sentencing Prediction
Feb 04, 2026Legal judgment prediction (LJP) aims to predict judicial outcomes from case facts and typically includes law article, charge, and sentencing prediction. While recent methods perform well on the first two subtasks, legal sentencing prediction (LSP) remains difficult due to its need for fine-grained objective knowledge and flexible subjective reasoning. To address these limitations, we propose $MSR^2$, a framework that integrates multi-source retrieval and reasoning in LLMs with reinforcement learning. $MSR^2$ enables LLMs to perform multi-source retrieval based on reasoning needs and applies a process-level reward to guide intermediate subjective reasoning steps. Experiments on two real-world datasets show that $MSR^2$ improves both accuracy and interpretability in LSP, providing a promising step toward practical legal AI. Our code is available at https://anonymous.4open.science/r/MSR2-FC3B.
DELTA: Deliberative Multi-Agent Reasoning with Reinforcement Learning for Multimodal Psychological Counseling
Feb 04, 2026Psychological counseling is a fundamentally multimodal cognitive process in which clinicians integrate verbal content with visual and vocal cues to infer clients' mental states and respond empathically. However, most existing language-model-based counseling systems operate on text alone and rely on implicit mental state inference. We introduce DELTA, a deliberative multi-agent framework that models counseling as a structured reasoning process over multimodal signals, separating evidence grounding, mental state abstraction, and response generation. DELTA further incorporates reinforcement learning guided by a distribution-level Emotion Attunement Score to encourage emotionally attuned responses. Experiments on a multimodal counseling benchmark show that DELTA improves both counseling quality and emotion attunement across models. Ablation and qualitative analyses suggest that explicit multimodal reasoning and structured mental state representations play complementary roles in supporting empathic human-AI interaction.
LegalOne: A Family of Foundation Models for Reliable Legal Reasoning
Feb 03, 2026While Large Language Models (LLMs) have demonstrated impressive general capabilities, their direct application in the legal domain is often hindered by a lack of precise domain knowledge and complexity of performing rigorous multi-step judicial reasoning. To address this gap, we present LegalOne, a family of foundational models specifically tailored for the Chinese legal domain. LegalOne is developed through a comprehensive three-phase pipeline designed to master legal reasoning. First, during mid-training phase, we propose Plasticity-Adjusted Sampling (PAS) to address the challenge of domain adaptation. This perplexity-based scheduler strikes a balance between the acquisition of new knowledge and the retention of original capabilities, effectively establishing a robust legal foundation. Second, during supervised fine-tuning, we employ Legal Agentic CoT Distillation (LEAD) to distill explicit reasoning from raw legal texts. Unlike naive distillation, LEAD utilizes an agentic workflow to convert complex judicial processes into structured reasoning trajectories, thereby enforcing factual grounding and logical rigor. Finally, we implement a Curriculum Reinforcement Learning (RL) strategy. Through a progressive reinforcement process spanning memorization, understanding, and reasoning, LegalOne evolves from simple pattern matching to autonomous and reliable legal reasoning. Experimental results demonstrate that LegalOne achieves state-of-the-art performance across a wide range of legal tasks, surpassing general-purpose LLMs with vastly larger parameter counts through enhanced knowledge density and efficiency. We publicly release the LegalOne weights and the LegalKit evaluation framework to advance the field of Legal AI, paving the way for deploying trustworthy and interpretable foundation models in high-stakes judicial applications.
A Comprehensive Study of Deep Learning Model Fixing Approaches
Dec 26, 2025Deep Learning (DL) has been widely adopted in diverse industrial domains, including autonomous driving, intelligent healthcare, and aided programming. Like traditional software, DL systems are also prone to faults, whose malfunctioning may expose users to significant risks. Consequently, numerous approaches have been proposed to address these issues. In this paper, we conduct a large-scale empirical study on 16 state-of-the-art DL model fixing approaches, spanning model-level, layer-level, and neuron-level categories, to comprehensively evaluate their performance. We assess not only their fixing effectiveness (their primary purpose) but also their impact on other critical properties, such as robustness, fairness, and backward compatibility. To ensure comprehensive and fair evaluation, we employ a diverse set of datasets, model architectures, and application domains within a uniform experimental setup for experimentation. We summarize several key findings with implications for both industry and academia. For example, model-level approaches demonstrate superior fixing effectiveness compared to others. No single approach can achieve the best fixing performance while improving accuracy and maintaining all other properties. Thus, academia should prioritize research on mitigating these side effects. These insights highlight promising directions for future exploration in this field.
Towards Seamless Interaction: Causal Turn-Level Modeling of Interactive 3D Conversational Head Dynamics
Dec 17, 2025



Human conversation involves continuous exchanges of speech and nonverbal cues such as head nods, gaze shifts, and facial expressions that convey attention and emotion. Modeling these bidirectional dynamics in 3D is essential for building expressive avatars and interactive robots. However, existing frameworks often treat talking and listening as independent processes or rely on non-causal full-sequence modeling, hindering temporal coherence across turns. We present TIMAR (Turn-level Interleaved Masked AutoRegression), a causal framework for 3D conversational head generation that models dialogue as interleaved audio-visual contexts. It fuses multimodal information within each turn and applies turn-level causal attention to accumulate conversational history, while a lightweight diffusion head predicts continuous 3D head dynamics that captures both coordination and expressive variability. Experiments on the DualTalk benchmark show that TIMAR reduces Fréchet Distance and MSE by 15-30% on the test set, and achieves similar gains on out-of-distribution data. The source code will be released in the GitHub repository https://github.com/CoderChen01/towards-seamleass-interaction.
Clarifying Semantics of In-Context Examples for Unit Test Generation
Oct 02, 2025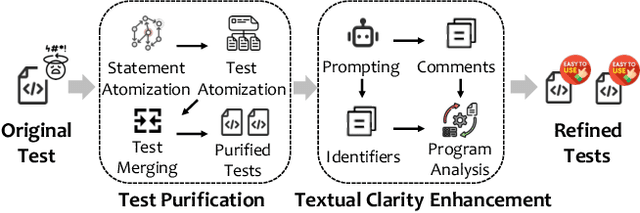
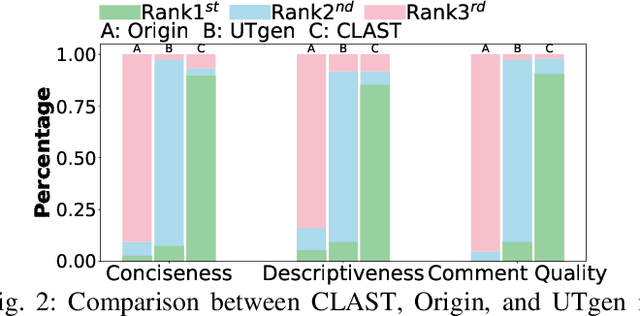
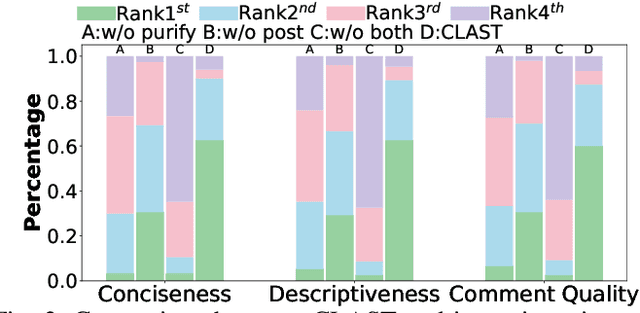

Recent advances in large language models (LLMs) have enabled promising performance in unit test generation through in-context learning (ICL). However, the quality of in-context examples significantly influences the effectiveness of generated tests-poorly structured or semantically unclear test examples often lead to suboptimal outputs. In this paper, we propose CLAST, a novel technique that systematically refines unit tests to improve their semantic clarity, thereby enhancing their utility as in-context examples. The approach decomposes complex tests into logically clearer ones and improves semantic clarity through a combination of program analysis and LLM-based rewriting. We evaluated CLAST on four open-source and three industrial projects. The results demonstrate that CLAST largely outperforms UTgen, the state-of-the-art refinement technique, in both preserving test effectiveness and enhancing semantic clarity. Specifically, CLAST fully retains the original effectiveness of unit tests, while UTgen reduces compilation success rate (CSR), pass rate (PR), test coverage (Cov), and mutation score (MS) by an average of 12.90%, 35.82%, 4.65%, and 5.07%, respectively. Over 85.33% of participants in our user study preferred the semantic clarity of CLAST-refined tests. Notably, incorporating CLAST-refined tests as examples effectively improves ICL-based unit test generation approaches such as RAGGen and TELPA, resulting in an average increase of 25.97% in CSR, 28.22% in PR, and 45.99% in Cov for generated tests, compared to incorporating UTgen-refined tests. The insights from the follow-up user study not only reinforce CLAST's potential impact in software testing practice but also illuminate avenues for future research.
AgenTracer: Who Is Inducing Failure in the LLM Agentic Systems?
Sep 04, 2025Large Language Model (LLM)-based agentic systems, often comprising multiple models, complex tool invocations, and orchestration protocols, substantially outperform monolithic agents. Yet this very sophistication amplifies their fragility, making them more prone to system failure. Pinpointing the specific agent or step responsible for an error within long execution traces defines the task of agentic system failure attribution. Current state-of-the-art reasoning LLMs, however, remain strikingly inadequate for this challenge, with accuracy generally below 10%. To address this gap, we propose AgenTracer, the first automated framework for annotating failed multi-agent trajectories via counterfactual replay and programmed fault injection, producing the curated dataset TracerTraj. Leveraging this resource, we develop AgenTracer-8B, a lightweight failure tracer trained with multi-granular reinforcement learning, capable of efficiently diagnosing errors in verbose multi-agent interactions. On the Who&When benchmark, AgenTracer-8B outperforms giant proprietary LLMs like Gemini-2.5-Pro and Claude-4-Sonnet by up to 18.18%, setting a new standard in LLM agentic failure attribution. More importantly, AgenTracer-8B delivers actionable feedback to off-the-shelf multi-agent systems like MetaGPT and MaAS with 4.8-14.2% performance gains, empowering self-correcting and self-evolving agentic AI.
HiCache: Training-free Acceleration of Diffusion Models via Hermite Polynomial-based Feature Caching
Aug 23, 2025Diffusion models have achieved remarkable success in content generation but suffer from prohibitive computational costs due to iterative sampling. While recent feature caching methods tend to accelerate inference through temporal extrapolation, these methods still suffer from server quality loss due to the failure in modeling the complex dynamics of feature evolution. To solve this problem, this paper presents HiCache, a training-free acceleration framework that fundamentally improves feature prediction by aligning mathematical tools with empirical properties. Our key insight is that feature derivative approximations in Diffusion Transformers exhibit multivariate Gaussian characteristics, motivating the use of Hermite polynomials-the potentially theoretically optimal basis for Gaussian-correlated processes. Besides, We further introduce a dual-scaling mechanism that ensures numerical stability while preserving predictive accuracy. Extensive experiments demonstrate HiCache's superiority: achieving 6.24x speedup on FLUX.1-dev while exceeding baseline quality, maintaining strong performance across text-to-image, video generation, and super-resolution tasks. Core implementation is provided in the appendix, with complete code to be released upon acceptance.
GLM-4.1V-Thinking: Towards Versatile Multimodal Reasoning with Scalable Reinforcement Learning
Jul 02, 2025



We present GLM-4.1V-Thinking, a vision-language model (VLM) designed to advance general-purpose multimodal understanding and reasoning. In this report, we share our key findings in the development of the reasoning-centric training framework. We first develop a capable vision foundation model with significant potential through large-scale pre-training, which arguably sets the upper bound for the final performance. We then propose Reinforcement Learning with Curriculum Sampling (RLCS) to unlock the full potential of the model, leading to comprehensive capability enhancement across a diverse range of tasks, including STEM problem solving, video understanding, content recognition, coding, grounding, GUI-based agents, and long document understanding. We open-source GLM-4.1V-9B-Thinking, which achieves state-of-the-art performance among models of comparable size. In a comprehensive evaluation across 28 public benchmarks, our model outperforms Qwen2.5-VL-7B on nearly all tasks and achieves comparable or even superior performance on 18 benchmarks relative to the significantly larger Qwen2.5-VL-72B. Notably, GLM-4.1V-9B-Thinking also demonstrates competitive or superior performance compared to closed-source models such as GPT-4o on challenging tasks including long document understanding and STEM reasoning, further underscoring its strong capabilities. Code, models and more information are released at https://github.com/THUDM/GLM-4.1V-Thinking.
TACTIC: Translation Agents with Cognitive-Theoretic Interactive Collaboration
Jun 11, 2025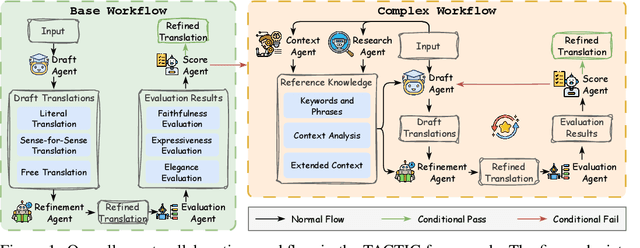
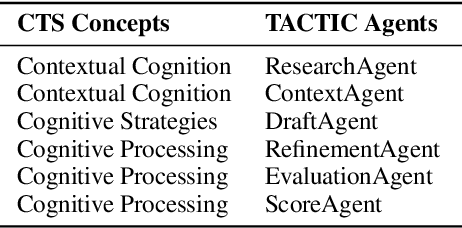
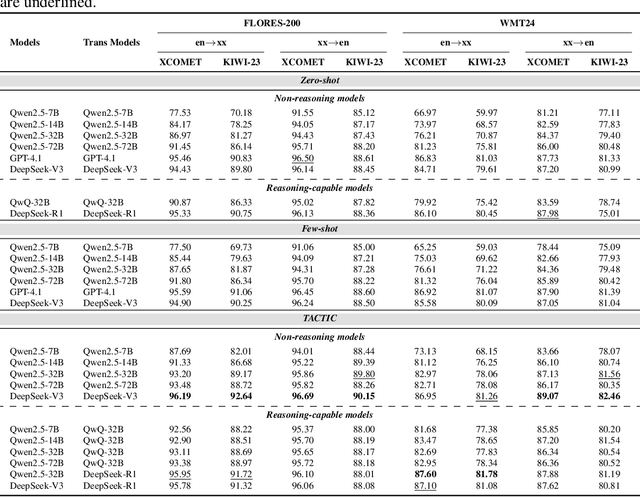

Machine translation has long been a central task in natural language processing. With the rapid advancement of large language models (LLMs), there has been remarkable progress in translation quality. However, fully realizing the translation potential of LLMs remains an open challenge. Recent studies have explored multi-agent systems to decompose complex translation tasks into collaborative subtasks, showing initial promise in enhancing translation quality through agent cooperation and specialization. Nevertheless, existing multi-agent translation frameworks largely neglect foundational insights from cognitive translation studies. These insights emphasize how human translators employ different cognitive strategies, such as balancing literal and free translation, refining expressions based on context, and iteratively evaluating outputs. To address this limitation, we propose a cognitively informed multi-agent framework called TACTIC, which stands for T ranslation A gents with Cognitive- T heoretic Interactive Collaboration. The framework comprises six functionally distinct agents that mirror key cognitive processes observed in human translation behavior. These include agents for drafting, refinement, evaluation, scoring, context reasoning, and external knowledge gathering. By simulating an interactive and theory-grounded translation workflow, TACTIC effectively leverages the full capacity of LLMs for high-quality translation. Experimental results on diverse language pairs from the FLORES-200 and WMT24 benchmarks show that our method consistently achieves state-of-the-art performance. Using DeepSeek-V3 as the base model, TACTIC surpasses GPT-4.1 by an average of +0.6 XCOMET and +1.18 COMETKIWI-23. Compared to DeepSeek-R1, it further improves by +0.84 XCOMET and +2.99 COMETKIWI-23. Code is available at https://github.com/weiyali126/TACTIC.