 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOverview of the NTCIR-18 Automatic Evaluation of LLMs (AEOLLM) Task
Mar 17, 2025In this paper, we provide an overview of the NTCIR-18 Automatic Evaluation of LLMs (AEOLLM) task. As large language models (LLMs) grow popular in both academia and industry, how to effectively evaluate the capacity of LLMs becomes an increasingly critical but still challenging issue. Existing methods can be divided into two types: manual evaluation, which is expensive, and automatic evaluation, which faces many limitations including task format (the majority belong to multiple-choice questions) and evaluation criteria (occupied by reference-based metrics). To advance the innovation of automatic evaluation, we propose the AEOLLM task which focuses on generative tasks and encourages reference-free methods. Besides, we set up diverse subtasks such as dialogue generation, text expansion, summary generation and non-factoid question answering to comprehensively test different methods. This year, we received 48 runs from 4 teams in total. This paper will describe the background of the task, the data set, the evaluation measures and the evaluation results, respectively.
CalibraEval: Calibrating Prediction Distribution to Mitigate Selection Bias in LLMs-as-Judges
Oct 20, 2024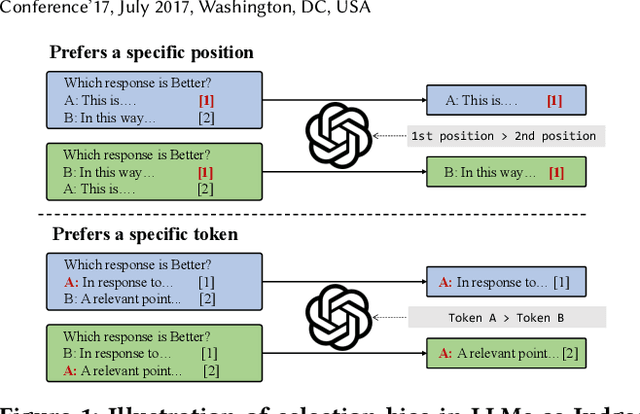
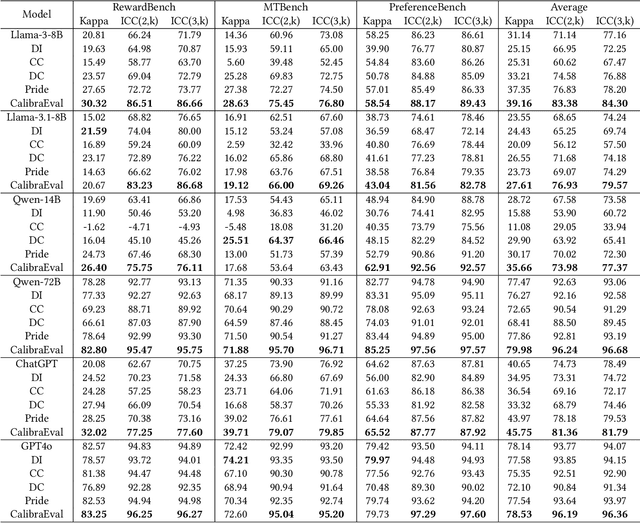
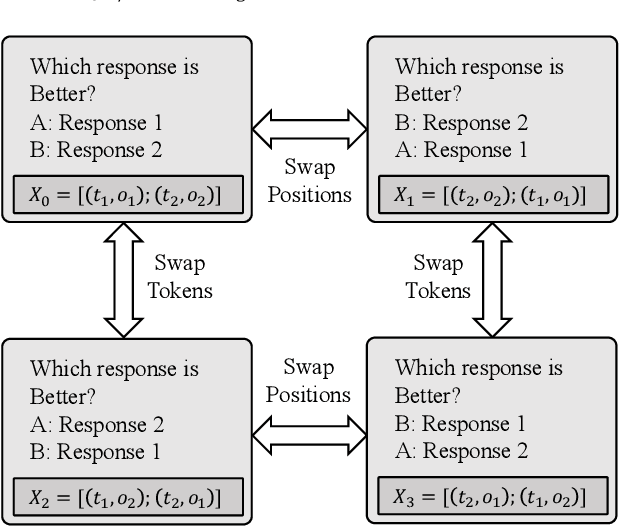
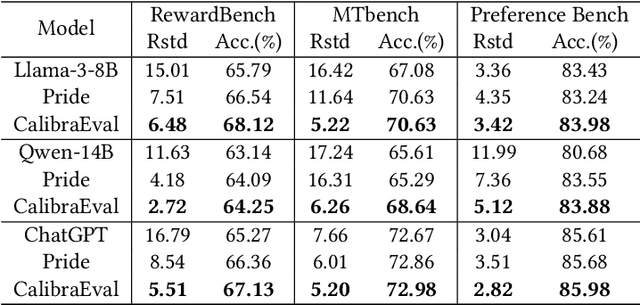
The use of large language models (LLMs) as automated evaluation tools to assess the quality of generated natural language, known as LLMs-as-Judges, has demonstrated promising capabilities and is rapidly gaining widespread attention. However, when applied to pairwise comparisons of candidate responses, LLM-based evaluators often exhibit selection bias. Specifically, their judgments may become inconsistent when the option positions or ID tokens are swapped, compromising the effectiveness and fairness of the evaluation result. To address this challenge, we introduce CalibraEval, a novel label-free method for mitigating selection bias during inference. Specifically, CalibraEval reformulates debiasing as an optimization task aimed at adjusting observed prediction distributions to align with unbiased prediction distributions. To solve this optimization problem, we propose a non-parametric order-preserving algorithm (NOA). This algorithm leverages the partial order relationships between model prediction distributions, thereby eliminating the need for explicit labels and precise mathematical function modeling.Empirical evaluations of LLMs in multiple representative benchmarks demonstrate that CalibraEval effectively mitigates selection bias and improves performance compared to existing debiasing methods. This work marks a step toward building more robust and unbiased automated evaluation frameworks, paving the way for improved reliability in AI-driven assessments
An Automatic and Cost-Efficient Peer-Review Framework for Language Generation Evaluation
Oct 16, 2024
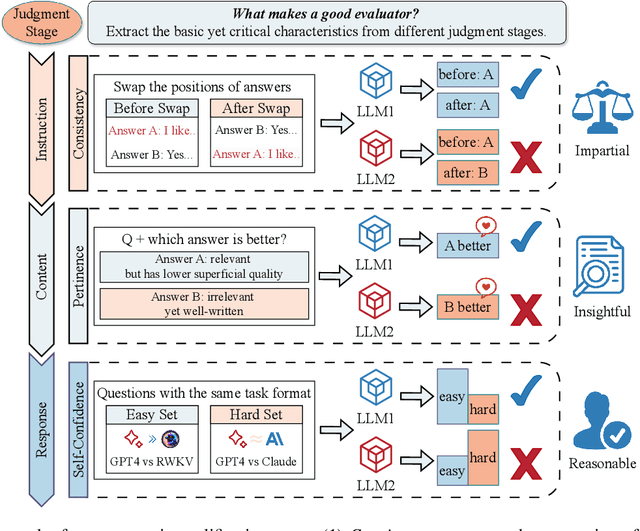

With the rapid development of large language models (LLMs), how to efficiently evaluate them has become an important research question. Existing evaluation methods often suffer from high costs, limited test formats, the need of human references, and systematic evaluation biases. To address these limitations, our study introduces the Auto-PRE, an automatic LLM evaluation framework based on peer review. In contrast to previous studies that rely on human annotations, Auto-PRE selects evaluator LLMs automatically based on their inherent traits including consistency, self-confidence, and pertinence. We conduct extensive experiments on three tasks: summary generation, non-factoid question-answering, and dialogue generation. Experimental results indicate our Auto-PRE achieves state-of-the-art performance at a lower cost. Moreover, our study highlights the impact of prompt strategies and evaluation formats on evaluation performance, offering guidance for method optimization in the future.
PRE: A Peer Review Based Large Language Model Evaluator
Jan 28, 2024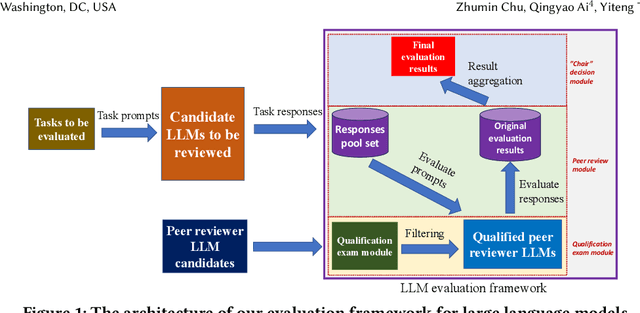
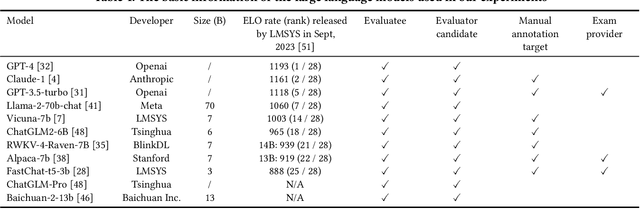
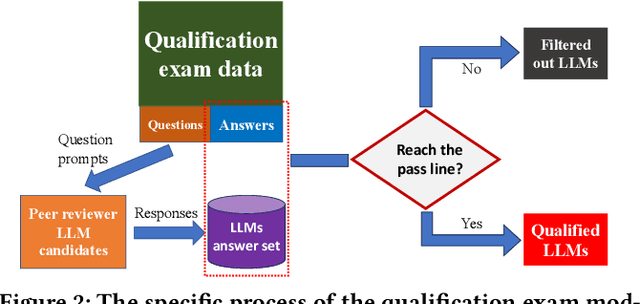
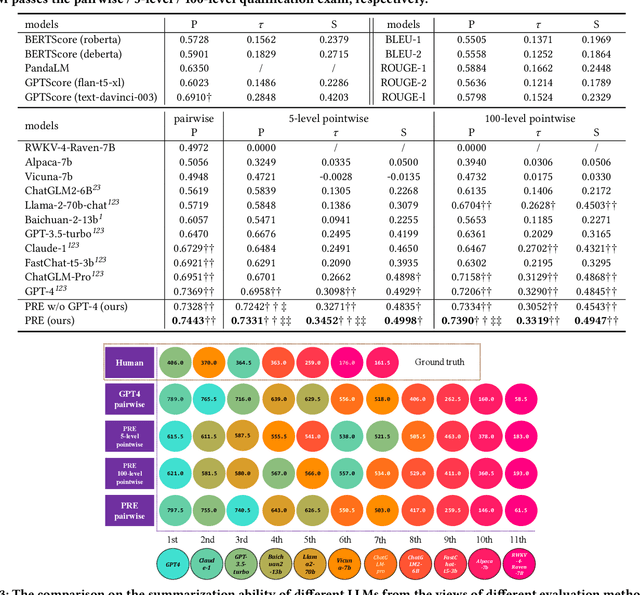
The impressive performance of large language models (LLMs) has attracted considerable attention from the academic and industrial communities. Besides how to construct and train LLMs, how to effectively evaluate and compare the capacity of LLMs has also been well recognized as an important yet difficult problem. Existing paradigms rely on either human annotators or model-based evaluators to evaluate the performance of LLMs on different tasks. However, these paradigms often suffer from high cost, low generalizability, and inherited biases in practice, which make them incapable of supporting the sustainable development of LLMs in long term. In order to address these issues, inspired by the peer review systems widely used in academic publication process, we propose a novel framework that can automatically evaluate LLMs through a peer-review process. Specifically, for the evaluation of a specific task, we first construct a small qualification exam to select "reviewers" from a couple of powerful LLMs. Then, to actually evaluate the "submissions" written by different candidate LLMs, i.e., the evaluatees, we use the reviewer LLMs to rate or compare the submissions. The final ranking of evaluatee LLMs is generated based on the results provided by all reviewers. We conducted extensive experiments on text summarization tasks with eleven LLMs including GPT-4. The results demonstrate the existence of biasness when evaluating using a single LLM. Also, our PRE model outperforms all the baselines, illustrating the effectiveness of the peer review mechanism.
Corrected Evaluation Results of the NTCIR WWW-2, WWW-3, and WWW-4 English Subtasks
Oct 19, 2022



Unfortunately, the official English (sub)task results reported in the NTCIR-14 WWW-2, NTCIR-15 WWW-3, and NTCIR-16 WWW-4 overview papers are incorrect due to noise in the official qrels files; this paper reports results based on the corrected qrels files. The noise is due to a fatal bug in the backend of our relevance assessment interface. More specifically, at WWW-2, WWW-3, and WWW-4, two versions of pool files were created for each English topic: a PRI ("prioritised") file, which uses the NTCIRPOOL script to prioritise likely relevant documents, and a RND ("randomised") file, which randomises the pooled documents. This was done for the purpose of studying the effect of document ordering for relevance assessors. However, the programmer who wrote the interface backend assumed that a combination of a topic ID and a document rank in the pool file uniquely determines a document ID; this is obviously incorrect as we have two versions of pool files. The outcome is that all the PRI-based relevance labels for the WWW-2 test collection are incorrect (while all the RND-based relevance labels are correct), and all the RND-based relevance labels for the WWW-3 and WWW-4 test collections are incorrect (while all the PRI-based relevance labels are correct). This bug was finally discovered at the NTCIR-16 WWW-4 task when the first seven authors of this paper served as Gold assessors (i.e., topic creators who define what is relevant) and closely examined the disagreements with Bronze assessors (i.e., non-topic-creators; non-experts). We would like to apologise to the WWW participants and the NTCIR chairs for the inconvenience and confusion caused due to this bug.
ConvSearch: A Open-Domain Conversational Search Behavior Dataset
Apr 06, 2022
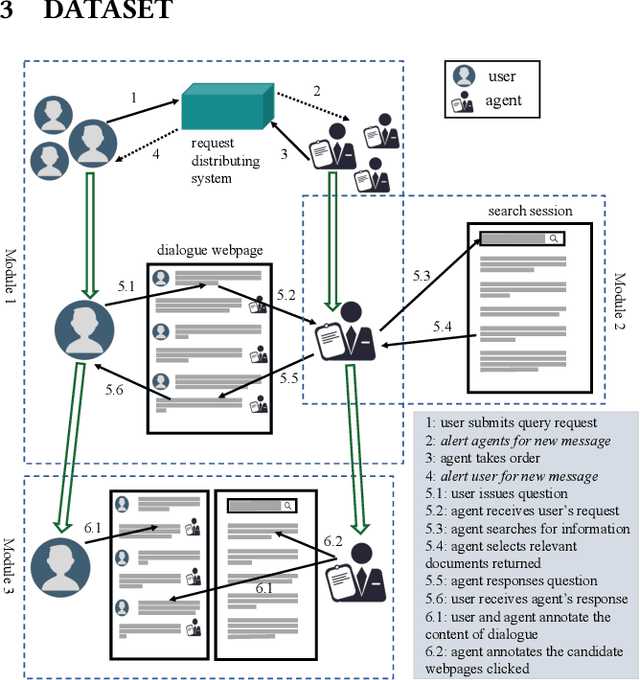
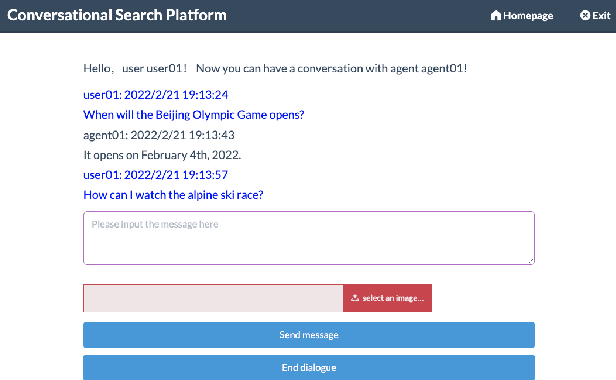
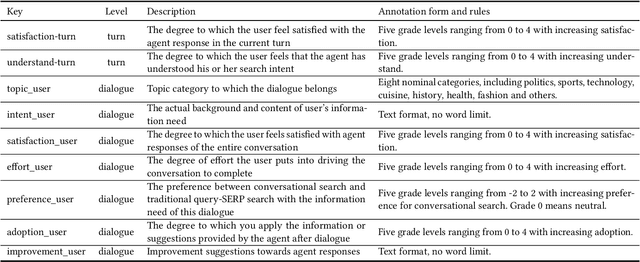
Conversational Search has been paid much attention recently with the increasing popularity of intelligent user interfaces. However, compared with the endeavour in designing effective conversational search algorithms, relatively much fewer researchers have focused on the construction of benchmark datasets. For most existing datasets, the information needs are defined by researchers and search requests are not proposed by actual users. Meanwhile, these datasets usually focus on the conversations between users and agents (systems), while largely ignores the search behaviors of agents before they return response to users. To overcome these problems, we construct a Chinese Open-Domain Conversational Search Behavior Dataset (ConvSearch) based on Wizard-of-Oz paradigm in the field study scenario. We develop a novel conversational search platform to collect dialogue contents, annotate dialogue quality and candidate search results and record agent search behaviors. 25 search agents and 51 users are recruited for the field study that lasts about 45 days. The ConvSearch dataset contains 1,131 dialogues together with annotated search results and corresponding search behaviors. We also provide the intent labels of each search behavior iteration to support intent understanding related researches. The dataset is already open to public for academic usage.