 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Source Retrieval and Reasoning for Legal Sentencing Prediction
Feb 04, 2026Legal judgment prediction (LJP) aims to predict judicial outcomes from case facts and typically includes law article, charge, and sentencing prediction. While recent methods perform well on the first two subtasks, legal sentencing prediction (LSP) remains difficult due to its need for fine-grained objective knowledge and flexible subjective reasoning. To address these limitations, we propose $MSR^2$, a framework that integrates multi-source retrieval and reasoning in LLMs with reinforcement learning. $MSR^2$ enables LLMs to perform multi-source retrieval based on reasoning needs and applies a process-level reward to guide intermediate subjective reasoning steps. Experiments on two real-world datasets show that $MSR^2$ improves both accuracy and interpretability in LSP, providing a promising step toward practical legal AI. Our code is available at https://anonymous.4open.science/r/MSR2-FC3B.
LegalOne: A Family of Foundation Models for Reliable Legal Reasoning
Feb 03, 2026While Large Language Models (LLMs) have demonstrated impressive general capabilities, their direct application in the legal domain is often hindered by a lack of precise domain knowledge and complexity of performing rigorous multi-step judicial reasoning. To address this gap, we present LegalOne, a family of foundational models specifically tailored for the Chinese legal domain. LegalOne is developed through a comprehensive three-phase pipeline designed to master legal reasoning. First, during mid-training phase, we propose Plasticity-Adjusted Sampling (PAS) to address the challenge of domain adaptation. This perplexity-based scheduler strikes a balance between the acquisition of new knowledge and the retention of original capabilities, effectively establishing a robust legal foundation. Second, during supervised fine-tuning, we employ Legal Agentic CoT Distillation (LEAD) to distill explicit reasoning from raw legal texts. Unlike naive distillation, LEAD utilizes an agentic workflow to convert complex judicial processes into structured reasoning trajectories, thereby enforcing factual grounding and logical rigor. Finally, we implement a Curriculum Reinforcement Learning (RL) strategy. Through a progressive reinforcement process spanning memorization, understanding, and reasoning, LegalOne evolves from simple pattern matching to autonomous and reliable legal reasoning. Experimental results demonstrate that LegalOne achieves state-of-the-art performance across a wide range of legal tasks, surpassing general-purpose LLMs with vastly larger parameter counts through enhanced knowledge density and efficiency. We publicly release the LegalOne weights and the LegalKit evaluation framework to advance the field of Legal AI, paving the way for deploying trustworthy and interpretable foundation models in high-stakes judicial applications.
ATACompressor: Adaptive Task-Aware Compression for Efficient Long-Context Processing in LLMs
Feb 03, 2026Long-context inputs in large language models (LLMs) often suffer from the "lost in the middle" problem, where critical information becomes diluted or ignored due to excessive length. Context compression methods aim to address this by reducing input size, but existing approaches struggle with balancing information preservation and compression efficiency. We propose Adaptive Task-Aware Compressor (ATACompressor), which dynamically adjusts compression based on the specific requirements of the task. ATACompressor employs a selective encoder that compresses only the task-relevant portions of long contexts, ensuring that essential information is preserved while reducing unnecessary content. Its adaptive allocation controller perceives the length of relevant content and adjusts the compression rate accordingly, optimizing resource utilization. We evaluate ATACompressor on three QA datasets: HotpotQA, MSMARCO, and SQUAD-showing that it outperforms existing methods in terms of both compression efficiency and task performance. Our approach provides a scalable solution for long-context processing in LLMs. Furthermore, we perform a range of ablation studies and analysis experiments to gain deeper insights into the key components of ATACompressor.
Kimi K2.5: Visual Agentic Intelligence
Feb 02, 2026We introduce Kimi K2.5, an open-source multimodal agentic model designed to advance general agentic intelligence. K2.5 emphasizes the joint optimization of text and vision so that two modalities enhance each other. This includes a series of techniques such as joint text-vision pre-training, zero-vision SFT, and joint text-vision reinforcement learning. Building on this multimodal foundation, K2.5 introduces Agent Swarm, a self-directed parallel agent orchestration framework that dynamically decomposes complex tasks into heterogeneous sub-problems and executes them concurrently. Extensive evaluations show that Kimi K2.5 achieves state-of-the-art results across various domains including coding, vision, reasoning, and agentic tasks. Agent Swarm also reduces latency by up to $4.5\times$ over single-agent baselines. We release the post-trained Kimi K2.5 model checkpoint to facilitate future research and real-world applications of agentic intelligence.
MulFeRL: Enhancing Reinforcement Learning with Verbal Feedback in a Multi-turn Loop
Jan 30, 2026Reinforcement Learning with Verifiable Rewards (RLVR) is widely used to improve reasoning in multiple domains, yet outcome-only scalar rewards are often sparse and uninformative, especially on failed samples, where they merely indicate failure and provide no insight into why the reasoning fails. In this paper, we investigate how to leverage richer verbal feedback to guide RLVR training on failed samples, and how to convert such feedback into a trainable learning signal. Specifically, we propose a multi-turn feedback-guided reinforcement learning framework. It builds on three mechanisms: (1) dynamic multi-turn regeneration guided by feedback, triggered only on failed samples, (2) two complementary learning signals for within-turn and cross-turn optimization, and (3) structured feedback injection into the model's reasoning process. Trained on sampled OpenR1-Math, the approach outperforms supervised fine-tuning and RLVR baselines in-domain and generalizes well out-of-domain.
Beyond Experience Retrieval: Learning to Generate Utility-Optimized Structured Experience for Frozen LLMs
Jan 30, 2026Large language models (LLMs) are largely static and often redo reasoning or repeat mistakes. Prior experience reuse typically relies on external retrieval, which is similarity-based, can introduce noise, and adds latency. We introduce SEAM (Structured Experience Adapter Module), a lightweight, executor-specific plug-in that stores experience in its parameters and generates a structured, instance-tailored experience entry in a single forward pass to guide a frozen LLM executor. SEAM is trained for utility via executor rollouts and GRPO while keeping the executor frozen, and it can be further improved after deployment with supervised fine-tuning on logged successful trajectories. Experiments on mathematical reasoning benchmarks show consistent accuracy gains across executors with low overhead. Extensive ablations and analyses further elucidate the mechanisms underlying SEAM's effectiveness and robustness.
Evaluation of Large Language Models in Legal Applications: Challenges, Methods, and Future Directions
Jan 21, 2026Large language models (LLMs) are being increasingly integrated into legal applications, including judicial decision support, legal practice assistance, and public-facing legal services. While LLMs show strong potential in handling legal knowledge and tasks, their deployment in real-world legal settings raises critical concerns beyond surface-level accuracy, involving the soundness of legal reasoning processes and trustworthy issues such as fairness and reliability. Systematic evaluation of LLM performance in legal tasks has therefore become essential for their responsible adoption. This survey identifies key challenges in evaluating LLMs for legal tasks grounded in real-world legal practice. We analyze the major difficulties involved in assessing LLM performance in the legal domain, including outcome correctness, reasoning reliability, and trustworthiness. Building on these challenges, we review and categorize existing evaluation methods and benchmarks according to their task design, datasets, and evaluation metrics. We further discuss the extent to which current approaches address these challenges, highlight their limitations, and outline future research directions toward more realistic, reliable, and legally grounded evaluation frameworks for LLMs in legal domains.
ReStyle-TTS: Relative and Continuous Style Control for Zero-Shot Speech Synthesis
Jan 07, 2026Zero-shot text-to-speech models can clone a speaker's timbre from a short reference audio, but they also strongly inherit the speaking style present in the reference. As a result, synthesizing speech with a desired style often requires carefully selecting reference audio, which is impractical when only limited or mismatched references are available. While recent controllable TTS methods attempt to address this issue, they typically rely on absolute style targets and discrete textual prompts, and therefore do not support continuous and reference-relative style control. We propose ReStyle-TTS, a framework that enables continuous and reference-relative style control in zero-shot TTS. Our key insight is that effective style control requires first reducing the model's implicit dependence on reference style before introducing explicit control mechanisms. To this end, we introduce Decoupled Classifier-Free Guidance (DCFG), which independently controls text and reference guidance, reducing reliance on reference style while preserving text fidelity. On top of this, we apply style-specific LoRAs together with Orthogonal LoRA Fusion to enable continuous and disentangled multi-attribute control, and introduce a Timbre Consistency Optimization module to mitigate timbre drift caused by weakened reference guidance. Experiments show that ReStyle-TTS enables user-friendly, continuous, and relative control over pitch, energy, and multiple emotions while maintaining intelligibility and speaker timbre, and performs robustly in challenging mismatched reference-target style scenarios.
Chinese Court Simulation with LLM-Based Agent System
Aug 24, 2025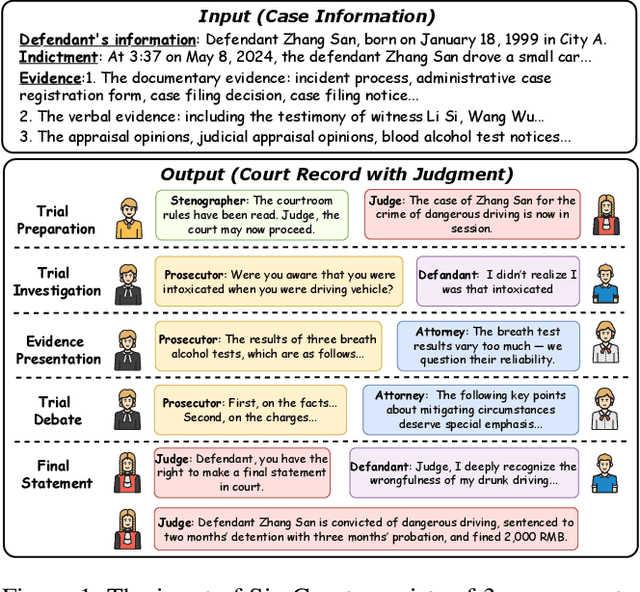

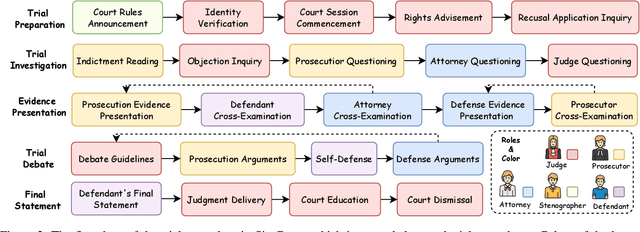

Mock trial has long served as an important platform for legal professional training and education. It not only helps students learn about realistic trial procedures, but also provides practical value for case analysis and judgment prediction. Traditional mock trials are difficult to access by the public because they rely on professional tutors and human participants. Fortunately, the rise of large language models (LLMs) provides new opportunities for creating more accessible and scalable court simulations. While promising, existing research mainly focuses on agent construction while ignoring the systematic design and evaluation of court simulations, which are actually more important for the credibility and usage of court simulation in practice. To this end, we present the first court simulation framework -- SimCourt -- based on the real-world procedure structure of Chinese courts. Our framework replicates all 5 core stages of a Chinese trial and incorporates 5 courtroom roles, faithfully following the procedural definitions in China. To simulate trial participants with different roles, we propose and craft legal agents equipped with memory, planning, and reflection abilities. Experiment on legal judgment prediction show that our framework can generate simulated trials that better guide the system to predict the imprisonment, probation, and fine of each case. Further annotations by human experts show that agents' responses under our simulation framework even outperformed judges and lawyers from the real trials in many scenarios. These further demonstrate the potential of LLM-based court simulation.
GLM-4.5: Agentic, Reasoning, and Coding (ARC) Foundation Models
Aug 08, 2025We present GLM-4.5, an open-source Mixture-of-Experts (MoE) large language model with 355B total parameters and 32B activated parameters, featuring a hybrid reasoning method that supports both thinking and direct response modes. Through multi-stage training on 23T tokens and comprehensive post-training with expert model iteration and reinforcement learning, GLM-4.5 achieves strong performance across agentic, reasoning, and coding (ARC) tasks, scoring 70.1% on TAU-Bench, 91.0% on AIME 24, and 64.2% on SWE-bench Verified. With much fewer parameters than several competitors, GLM-4.5 ranks 3rd overall among all evaluated models and 2nd on agentic benchmarks. We release both GLM-4.5 (355B parameters) and a compact version, GLM-4.5-Air (106B parameters), to advance research in reasoning and agentic AI systems. Code, models, and more information are available at https://github.com/zai-org/GLM-4.5.