 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReStyle-TTS: Relative and Continuous Style Control for Zero-Shot Speech Synthesis
Jan 07, 2026Zero-shot text-to-speech models can clone a speaker's timbre from a short reference audio, but they also strongly inherit the speaking style present in the reference. As a result, synthesizing speech with a desired style often requires carefully selecting reference audio, which is impractical when only limited or mismatched references are available. While recent controllable TTS methods attempt to address this issue, they typically rely on absolute style targets and discrete textual prompts, and therefore do not support continuous and reference-relative style control. We propose ReStyle-TTS, a framework that enables continuous and reference-relative style control in zero-shot TTS. Our key insight is that effective style control requires first reducing the model's implicit dependence on reference style before introducing explicit control mechanisms. To this end, we introduce Decoupled Classifier-Free Guidance (DCFG), which independently controls text and reference guidance, reducing reliance on reference style while preserving text fidelity. On top of this, we apply style-specific LoRAs together with Orthogonal LoRA Fusion to enable continuous and disentangled multi-attribute control, and introduce a Timbre Consistency Optimization module to mitigate timbre drift caused by weakened reference guidance. Experiments show that ReStyle-TTS enables user-friendly, continuous, and relative control over pitch, energy, and multiple emotions while maintaining intelligibility and speaker timbre, and performs robustly in challenging mismatched reference-target style scenarios.
Fine-Grained ECG-Text Contrastive Learning via Waveform Understanding Enhancement
May 17, 2025Electrocardiograms (ECGs) are essential for diagnosing cardiovascular diseases. While previous ECG-text contrastive learning methods have shown promising results, they often overlook the incompleteness of the reports. Given an ECG, the report is generated by first identifying key waveform features and then inferring the final diagnosis through these features. Despite their importance, these waveform features are often not recorded in the report as intermediate results. Aligning ECGs with such incomplete reports impedes the model's ability to capture the ECG's waveform features and limits its understanding of diagnostic reasoning based on those features. To address this, we propose FG-CLEP (Fine-Grained Contrastive Language ECG Pre-training), which aims to recover these waveform features from incomplete reports with the help of large language models (LLMs), under the challenges of hallucinations and the non-bijective relationship between waveform features and diagnoses. Additionally, considering the frequent false negatives due to the prevalence of common diagnoses in ECGs, we introduce a semantic similarity matrix to guide contrastive learning. Furthermore, we adopt a sigmoid-based loss function to accommodate the multi-label nature of ECG-related tasks. Experiments on six datasets demonstrate that FG-CLEP outperforms state-of-the-art methods in both zero-shot prediction and linear probing across these datasets.
DC-Seg: Disentangled Contrastive Learning for Brain Tumor Segmentation with Missing Modalities
May 17, 2025Accurate segmentation of brain images typically requires the integration of complementary information from multiple image modalities. However, clinical data for all modalities may not be available for every patient, creating a significant challenge. To address this, previous studies encode multiple modalities into a shared latent space. While somewhat effective, it remains suboptimal, as each modality contains distinct and valuable information. In this study, we propose DC-Seg (Disentangled Contrastive Learning for Segmentation), a new method that explicitly disentangles images into modality-invariant anatomical representation and modality-specific representation, by using anatomical contrastive learning and modality contrastive learning respectively. This solution improves the separation of anatomical and modality-specific features by considering the modality gaps, leading to more robust representations. Furthermore, we introduce a segmentation-based regularizer that enhances the model's robustness to missing modalities. Extensive experiments on the BraTS 2020 and a private white matter hyperintensity(WMH) segmentation dataset demonstrate that DC-Seg outperforms state-of-the-art methods in handling incomplete multimodal brain tumor segmentation tasks with varying missing modalities, while also demonstrate strong generalizability in WMH segmentation. The code is available at https://github.com/CuCl-2/DC-Seg.
Phenotype-Guided Generative Model for High-Fidelity Cardiac MRI Synthesis: Advancing Pretraining and Clinical Applications
May 06, 2025



Cardiac Magnetic Resonance (CMR) imaging is a vital non-invasive tool for diagnosing heart diseases and evaluating cardiac health. However, the limited availability of large-scale, high-quality CMR datasets poses a major challenge to the effective application of artificial intelligence (AI) in this domain. Even the amount of unlabeled data and the health status it covers are difficult to meet the needs of model pretraining, which hinders the performance of AI models on downstream tasks. In this study, we present Cardiac Phenotype-Guided CMR Generation (CPGG), a novel approach for generating diverse CMR data that covers a wide spectrum of cardiac health status. The CPGG framework consists of two stages: in the first stage, a generative model is trained using cardiac phenotypes derived from CMR data; in the second stage, a masked autoregressive diffusion model, conditioned on these phenotypes, generates high-fidelity CMR cine sequences that capture both structural and functional features of the heart in a fine-grained manner. We synthesized a massive amount of CMR to expand the pretraining data. Experimental results show that CPGG generates high-quality synthetic CMR data, significantly improving performance on various downstream tasks, including diagnosis and cardiac phenotypes prediction. These gains are demonstrated across both public and private datasets, highlighting the effectiveness of our approach. Code is availabel at https://anonymous.4open.science/r/CPGG.
De-biased Multimodal Electrocardiogram Analysis
Nov 22, 2024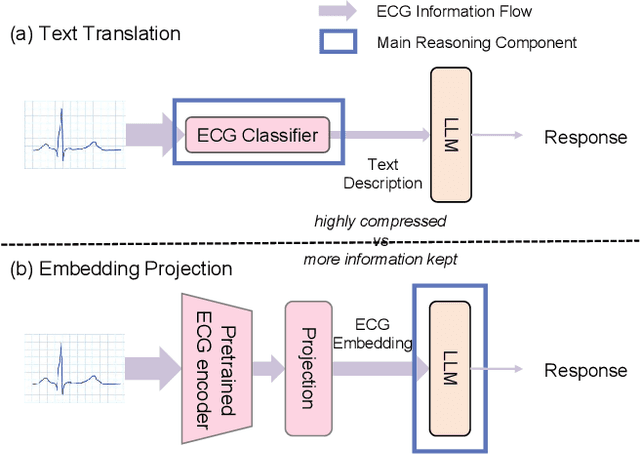

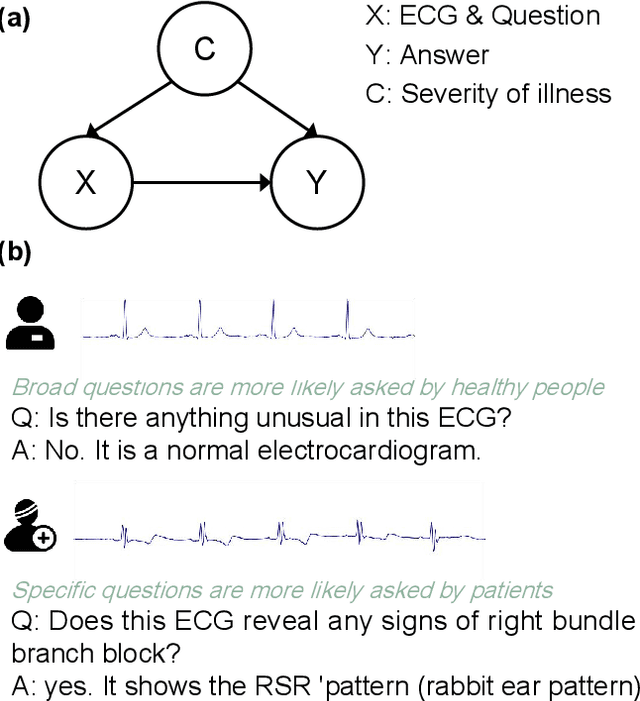

Multimodal large language models (MLLMs) are increasingly being applied in the medical field, particularly in medical imaging. However, developing MLLMs for ECG signals, which are crucial in clinical settings, has been a significant challenge beyond medical imaging. Previous studies have attempted to address this by converting ECGs into several text tags using an external classifier in a training-free manner. However, this approach significantly compresses the information in ECGs and underutilizes the reasoning capabilities of LLMs. In this work, we directly feed the embeddings of ECGs into the LLM through a projection layer, retaining more information about ECGs and better leveraging the reasoning abilities of LLMs. Our method can also effectively handle a common situation in clinical practice where it is necessary to compare two ECGs taken at different times. Recent studies found that MLLMs may rely solely on text input to provide answers, ignoring inputs from other modalities. We analyzed this phenomenon from a causal perspective in the context of ECG MLLMs and discovered that the confounder, severity of illness, introduces a spurious correlation between the question and answer, leading the model to rely on this spurious correlation and ignore the ECG input. Such models do not comprehend the ECG input and perform poorly in adversarial tests where different expressions of the same question are used in the training and testing sets. We designed a de-biased pre-training method to eliminate the confounder's effect according to the theory of backdoor adjustment. Our model performed well on the ECG-QA task under adversarial testing and demonstrated zero-shot capabilities. An interesting random ECG test further validated that our model effectively understands and utilizes the input ECG signal.
Large-scale cross-modality pretrained model enhances cardiovascular state estimation and cardiomyopathy detection from electrocardiograms: An AI system development and multi-center validation study
Nov 19, 2024



Cardiovascular diseases (CVDs) present significant challenges for early and accurate diagnosis. While cardiac magnetic resonance imaging (CMR) is the gold standard for assessing cardiac function and diagnosing CVDs, its high cost and technical complexity limit accessibility. In contrast, electrocardiography (ECG) offers promise for large-scale early screening. This study introduces CardiacNets, an innovative model that enhances ECG analysis by leveraging the diagnostic strengths of CMR through cross-modal contrastive learning and generative pretraining. CardiacNets serves two primary functions: (1) it evaluates detailed cardiac function indicators and screens for potential CVDs, including coronary artery disease, cardiomyopathy, pericarditis, heart failure and pulmonary hypertension, using ECG input; and (2) it enhances interpretability by generating high-quality CMR images from ECG data. We train and validate the proposed CardiacNets on two large-scale public datasets (the UK Biobank with 41,519 individuals and the MIMIC-IV-ECG comprising 501,172 samples) as well as three private datasets (FAHZU with 410 individuals, SAHZU with 464 individuals, and QPH with 338 individuals), and the findings demonstrate that CardiacNets consistently outperforms traditional ECG-only models, substantially improving screening accuracy. Furthermore, the generated CMR images provide valuable diagnostic support for physicians of all experience levels. This proof-of-concept study highlights how ECG can facilitate cross-modal insights into cardiac function assessment, paving the way for enhanced CVD screening and diagnosis at a population level.
Rapid and Accurate Diagnosis of Acute Aortic Syndrome using Non-contrast CT: A Large-scale, Retrospective, Multi-center and AI-based Study
Jun 25, 2024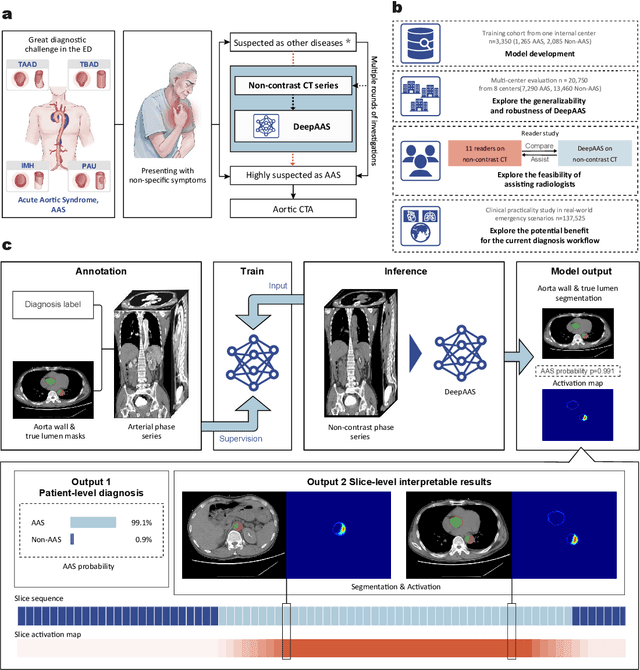
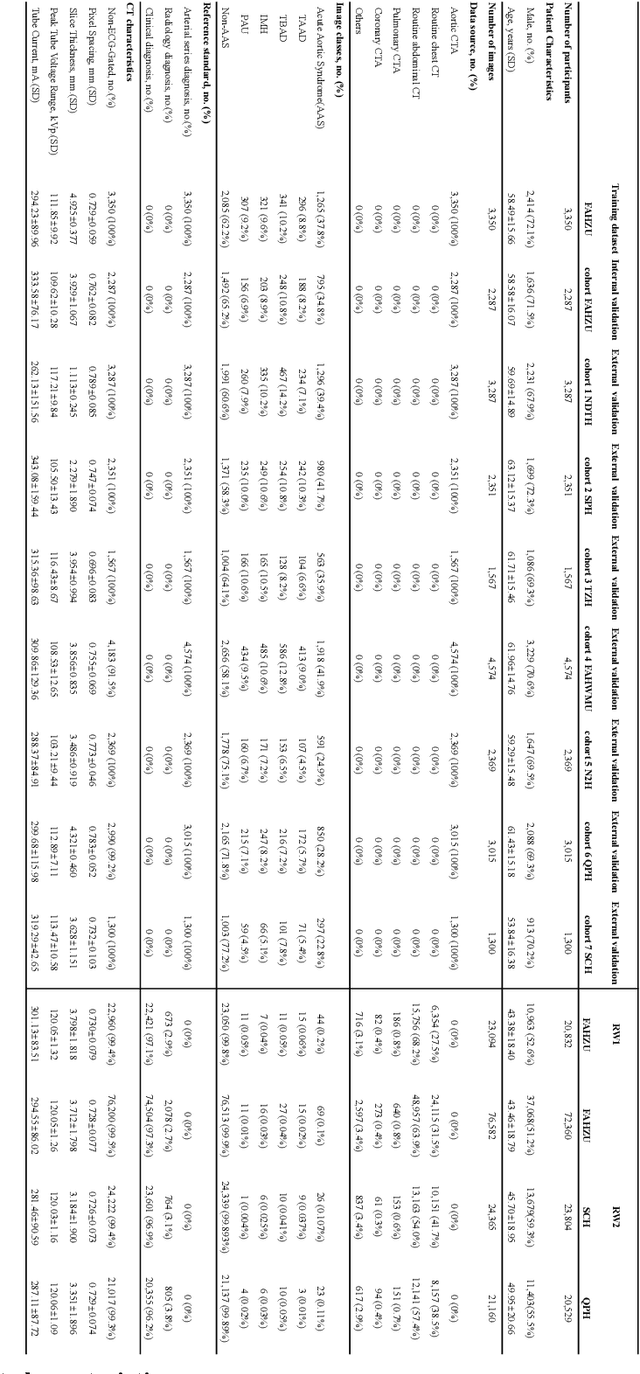
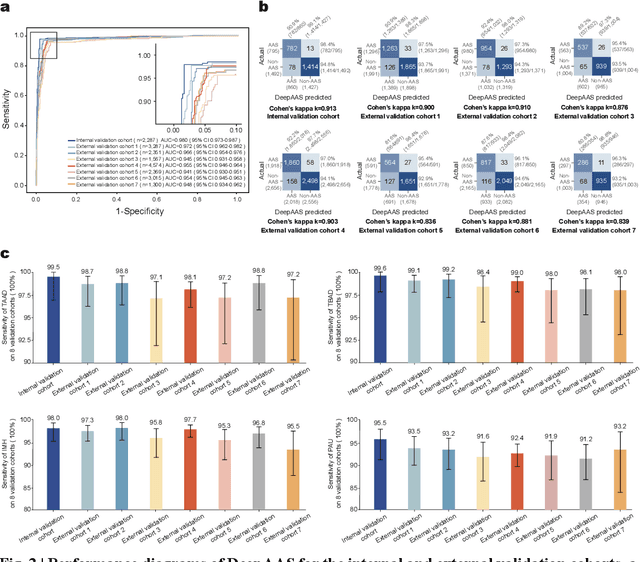
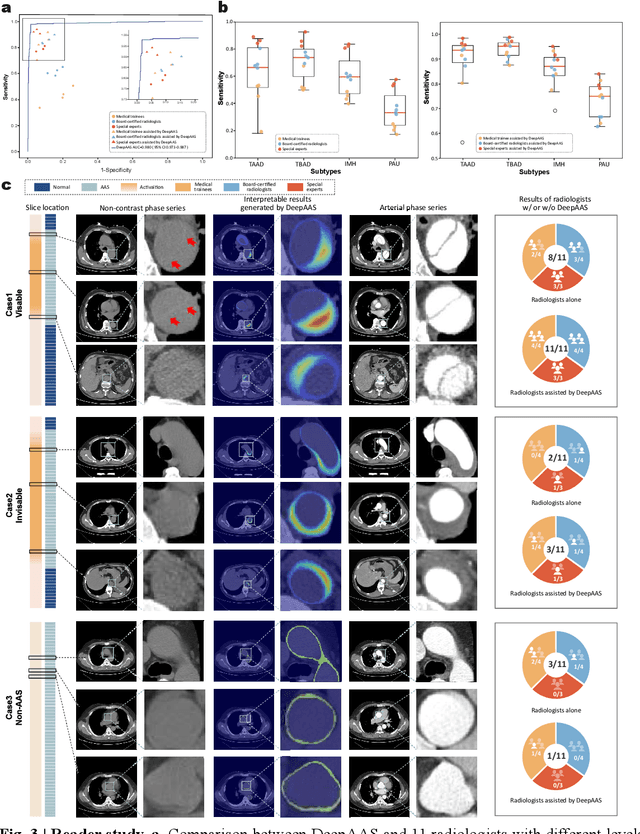
Chest pain symptoms are highly prevalent in emergency departments (EDs), where acute aortic syndrome (AAS) is a catastrophic cardiovascular emergency with a high fatality rate, especially when timely and accurate treatment is not administered. However, current triage practices in the ED can cause up to approximately half of patients with AAS to have an initially missed diagnosis or be misdiagnosed as having other acute chest pain conditions. Subsequently, these AAS patients will undergo clinically inaccurate or suboptimal differential diagnosis. Fortunately, even under these suboptimal protocols, nearly all these patients underwent non-contrast CT covering the aorta anatomy at the early stage of differential diagnosis. In this study, we developed an artificial intelligence model (DeepAAS) using non-contrast CT, which is highly accurate for identifying AAS and provides interpretable results to assist in clinical decision-making. Performance was assessed in two major phases: a multi-center retrospective study (n = 20,750) and an exploration in real-world emergency scenarios (n = 137,525). In the multi-center cohort, DeepAAS achieved a mean area under the receiver operating characteristic curve of 0.958 (95% CI 0.950-0.967). In the real-world cohort, DeepAAS detected 109 AAS patients with misguided initial suspicion, achieving 92.6% (95% CI 76.2%-97.5%) in mean sensitivity and 99.2% (95% CI 99.1%-99.3%) in mean specificity. Our AI model performed well on non-contrast CT at all applicable early stages of differential diagnosis workflows, effectively reduced the overall missed diagnosis and misdiagnosis rate from 48.8% to 4.8% and shortened the diagnosis time for patients with misguided initial suspicion from an average of 681.8 (74-11,820) mins to 68.5 (23-195) mins. DeepAAS could effectively fill the gap in the current clinical workflow without requiring additional tests.
Conversational Disease Diagnosis via External Planner-Controlled Large Language Models
Apr 04, 2024



The advancement of medical artificial intelligence (AI) has set the stage for the realization of conversational diagnosis, where AI systems mimic human doctors by engaging in dialogue with patients to deduce diagnoses. This study introduces an innovative approach using external planners augmented with large language models (LLMs) to develop a medical task-oriented dialogue system. This system comprises a policy module for information gathering, a LLM based module for natural language understanding and generation, addressing the limitations of previous AI systems in these areas. By emulating the two-phase decision-making process of doctors disease screening and differential diagnosis. we designed two distinct planners. The first focuses on collecting patient symptoms to identify potential diseases, while the second delves into specific inquiries to confirm or exclude these diseases. Utilizing reinforcement learning and active learning with LLMs, we trained these planners to navigate medical dialogues effectively. Our evaluation on the MIMIC-IV dataset demonstrated the system's capability to outperform existing models, indicating a significant step towards achieving automated conversational disease diagnostics and enhancing the precision and accessibility of medical diagnoses.
Causal Interpretable Progression Trajectory Analysis of Chronic Disease
Aug 18, 2023Chronic disease is the leading cause of death, emphasizing the need for accurate prediction of disease progression trajectories and informed clinical decision-making. Machine learning (ML) models have shown promise in this domain by capturing non-linear patterns within patient features. However, existing ML-based models lack the ability to provide causal interpretable predictions and estimate treatment effects, limiting their decision-assisting perspective. In this study, we propose a novel model called causal trajectory prediction (CTP) to tackle the limitation. The CTP model combines trajectory prediction and causal discovery to enable accurate prediction of disease progression trajectories and uncovering causal relationships between features. By incorporating a causal graph into the prediction process, CTP ensures that ancestor features are not influenced by treatment on descendant features, thereby enhancing the interpretability of the model. By estimating the bounds of treatment effects, even in the presence of unmeasured confounders, the CTP provides valuable insights for clinical decision-making. We evaluate the performance of the CTP using simulated and real medical datasets. Experimental results demonstrate that our model achieves satisfactory performance, highlighting its potential to assist clinical decisions.
Replicating Complex Dialogue Policy of Humans via Offline Imitation Learning with Supervised Regularization
May 06, 2023Policy learning (PL) is a module of a task-oriented dialogue system that trains an agent to make actions in each dialogue turn. Imitating human action is a fundamental problem of PL. However, both supervised learning (SL) and reinforcement learning (RL) frameworks cannot imitate humans well. Training RL models require online interactions with user simulators, while simulating complex human policy is hard. Performances of SL-based models are restricted because of the covariate shift problem. Specifically, a dialogue is a sequential decision-making process where slight differences in current utterances and actions will cause significant differences in subsequent utterances. Therefore, the generalize ability of SL models is restricted because statistical characteristics of training and testing dialogue data gradually become different. This study proposed an offline imitation learning model that learns policy from real dialogue datasets and does not require user simulators. It also utilizes state transition information, which alleviates the influence of the covariate shift problem. We introduced a regularization trick to make our model can be effectively optimized. We investigated the performance of our model on four independent public dialogue datasets. The experimental result showed that our model performed better in the action prediction task.