 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDe-biased Multimodal Electrocardiogram Analysis
Paper and Code
Nov 22, 2024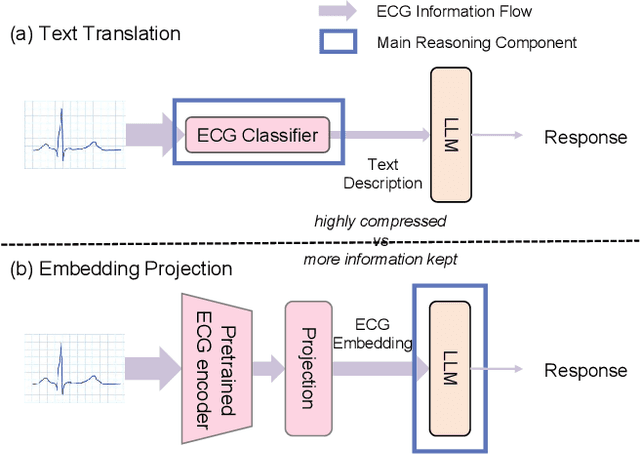

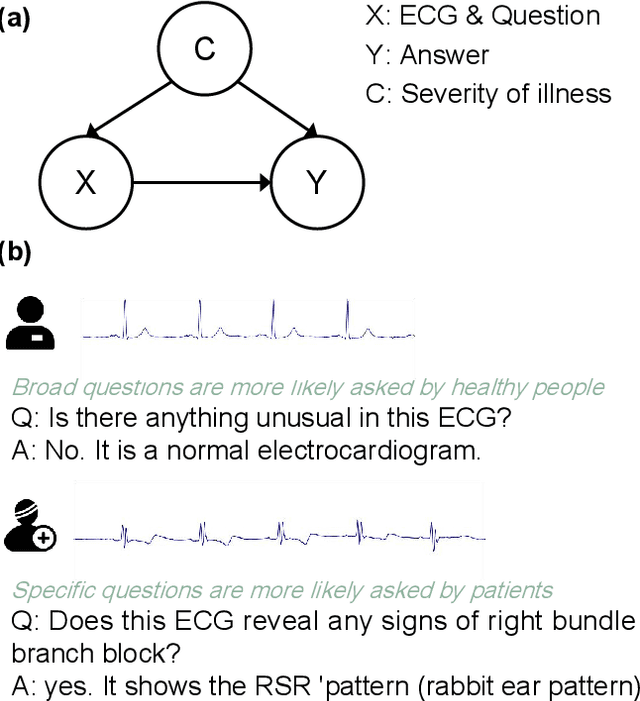

Multimodal large language models (MLLMs) are increasingly being applied in the medical field, particularly in medical imaging. However, developing MLLMs for ECG signals, which are crucial in clinical settings, has been a significant challenge beyond medical imaging. Previous studies have attempted to address this by converting ECGs into several text tags using an external classifier in a training-free manner. However, this approach significantly compresses the information in ECGs and underutilizes the reasoning capabilities of LLMs. In this work, we directly feed the embeddings of ECGs into the LLM through a projection layer, retaining more information about ECGs and better leveraging the reasoning abilities of LLMs. Our method can also effectively handle a common situation in clinical practice where it is necessary to compare two ECGs taken at different times. Recent studies found that MLLMs may rely solely on text input to provide answers, ignoring inputs from other modalities. We analyzed this phenomenon from a causal perspective in the context of ECG MLLMs and discovered that the confounder, severity of illness, introduces a spurious correlation between the question and answer, leading the model to rely on this spurious correlation and ignore the ECG input. Such models do not comprehend the ECG input and perform poorly in adversarial tests where different expressions of the same question are used in the training and testing sets. We designed a de-biased pre-training method to eliminate the confounder's effect according to the theory of backdoor adjustment. Our model performed well on the ECG-QA task under adversarial testing and demonstrated zero-shot capabilities. An interesting random ECG test further validated that our model effectively understands and utilizes the input ECG signal.