 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUFO-DETR: Frequency-Guided End-to-End Detector for UAV Tiny Objects
Feb 26, 2026Small target detection in UAV imagery faces significant challenges such as scale variations, dense distribution, and the dominance of small targets. Existing algorithms rely on manually designed components, and general-purpose detectors are not optimized for UAV images, making it difficult to balance accuracy and complexity. To address these challenges, this paper proposes an end-to-end object detection framework, UFO-DETR, which integrates an LSKNet-based backbone network to optimize the receptive field and reduce the number of parameters. By combining the DAttention and AIFI modules, the model flexibly models multi-scale spatial relationships, improving multi-scale target detection performance. Additionally, the DynFreq-C3 module is proposed to enhance small target detection capability through cross-space frequency feature enhancement. Experimental results show that, compared to RT-DETR-L, the proposed method offers significant advantages in both detection performance and computational efficiency, providing an efficient solution for UAV edge computing.
PoAct: Policy and Action Dual-Control Agent for Generalized Applications
Jan 13, 2025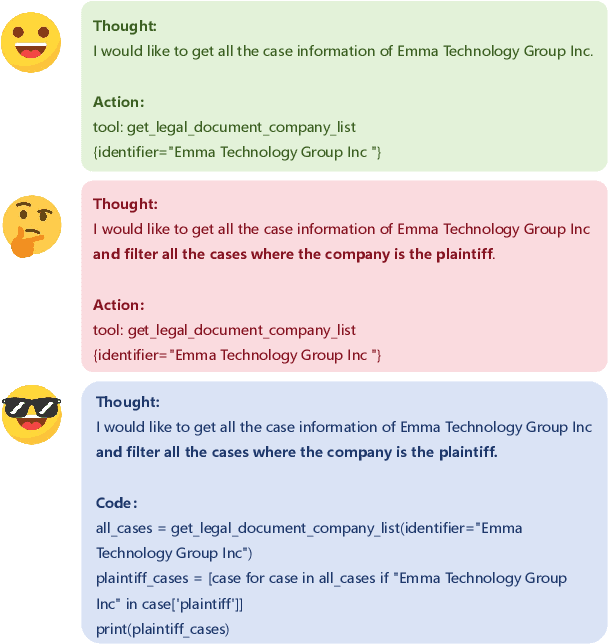



Based on their superior comprehension and reasoning capabilities, Large Language Model (LLM) driven agent frameworks have achieved significant success in numerous complex reasoning tasks. ReAct-like agents can solve various intricate problems step-by-step through progressive planning and tool calls, iteratively optimizing new steps based on environmental feedback. However, as the planning capabilities of LLMs improve, the actions invoked by tool calls in ReAct-like frameworks often misalign with complex planning and challenging data organization. Code Action addresses these issues while also introducing the challenges of a more complex action space and more difficult action organization. To leverage Code Action and tackle the challenges of its complexity, this paper proposes Policy and Action Dual-Control Agent (PoAct) for generalized applications. The aim is to achieve higher-quality code actions and more accurate reasoning paths by dynamically switching reasoning policies and modifying the action space. Experimental results on the Agent Benchmark for both legal and generic scenarios demonstrate the superior reasoning capabilities and reduced token consumption of our approach in complex tasks. On the LegalAgentBench, our method shows a 20 percent improvement over the baseline while requiring fewer tokens. We conducted experiments and analyses on the GPT-4o and GLM-4 series models, demonstrating the significant potential and scalability of our approach to solve complex problems.
LegalAgentBench: Evaluating LLM Agents in Legal Domain
Dec 23, 2024With the increasing intelligence and autonomy of LLM agents, their potential applications in the legal domain are becoming increasingly apparent. However, existing general-domain benchmarks cannot fully capture the complexity and subtle nuances of real-world judicial cognition and decision-making. Therefore, we propose LegalAgentBench, a comprehensive benchmark specifically designed to evaluate LLM Agents in the Chinese legal domain. LegalAgentBench includes 17 corpora from real-world legal scenarios and provides 37 tools for interacting with external knowledge. We designed a scalable task construction framework and carefully annotated 300 tasks. These tasks span various types, including multi-hop reasoning and writing, and range across different difficulty levels, effectively reflecting the complexity of real-world legal scenarios. Moreover, beyond evaluating final success, LegalAgentBench incorporates keyword analysis during intermediate processes to calculate progress rates, enabling more fine-grained evaluation. We evaluated eight popular LLMs, highlighting the strengths, limitations, and potential areas for improvement of existing models and methods. LegalAgentBench sets a new benchmark for the practical application of LLMs in the legal domain, with its code and data available at \url{https://github.com/CSHaitao/LegalAgentBench}.
Hierarchical B-frame Video Coding for Long Group of Pictures
Jun 24, 2024Learned video compression methods already outperform VVC in the low-delay (LD) case, but the random-access (RA) scenario remains challenging. Most works on learned RA video compression either use HEVC as an anchor or compare it to VVC in specific test conditions, using RGB-PSNR metric instead of Y-PSNR and avoiding comprehensive evaluation. Here, we present an end-to-end learned video codec for random access that combines training on long sequences of frames, rate allocation designed for hierarchical coding and content adaptation on inference. We show that under common test conditions (JVET-CTC), it achieves results comparable to VTM (VVC reference software) in terms of YUV-PSNR BD-Rate on some classes of videos, and outperforms it on almost all test sets in terms of VMAF BD-Rate. On average it surpasses open LD and RA end-to-end solutions in terms of VMAF and YUV BD-Rates.
End-to-End Optimized Image Compression with the Frequency-Oriented Transform
Jan 16, 2024Image compression constitutes a significant challenge amidst the era of information explosion. Recent studies employing deep learning methods have demonstrated the superior performance of learning-based image compression methods over traditional codecs. However, an inherent challenge associated with these methods lies in their lack of interpretability. Following an analysis of the varying degrees of compression degradation across different frequency bands, we propose the end-to-end optimized image compression model facilitated by the frequency-oriented transform. The proposed end-to-end image compression model consists of four components: spatial sampling, frequency-oriented transform, entropy estimation, and frequency-aware fusion. The frequency-oriented transform separates the original image signal into distinct frequency bands, aligning with the human-interpretable concept. Leveraging the non-overlapping hypothesis, the model enables scalable coding through the selective transmission of arbitrary frequency components. Extensive experiments are conducted to demonstrate that our model outperforms all traditional codecs including next-generation standard H.266/VVC on MS-SSIM metric. Moreover, visual analysis tasks (i.e., object detection and semantic segmentation) are conducted to verify the proposed compression method could preserve semantic fidelity besides signal-level precision.
MPAI-EEV: Standardization Efforts of Artificial Intelligence based End-to-End Video Coding
Sep 14, 2023



The rapid advancement of artificial intelligence (AI) technology has led to the prioritization of standardizing the processing, coding, and transmission of video using neural networks. To address this priority area, the Moving Picture, Audio, and Data Coding by Artificial Intelligence (MPAI) group is developing a suite of standards called MPAI-EEV for "end-to-end optimized neural video coding." The aim of this AI-based video standard project is to compress the number of bits required to represent high-fidelity video data by utilizing data-trained neural coding technologies. This approach is not constrained by how data coding has traditionally been applied in the context of a hybrid framework. This paper presents an overview of recent and ongoing standardization efforts in this area and highlights the key technologies and design philosophy of EEV. It also provides a comparison and report on some primary efforts such as the coding efficiency of the reference model. Additionally, it discusses emerging activities such as learned Unmanned-Aerial-Vehicles (UAVs) video coding which are currently planned, under development, or in the exploration phase. With a focus on UAV video signals, this paper addresses the current status of these preliminary efforts. It also indicates development timelines, summarizes the main technical details, and provides pointers to further points of reference. The exploration experiment shows that the EEV model performs better than the state-of-the-art video coding standard H.266/VVC in terms of perceptual evaluation metric.
VRConvMF: Visual Recurrent Convolutional Matrix Factorization for Movie Recommendation
Feb 16, 2022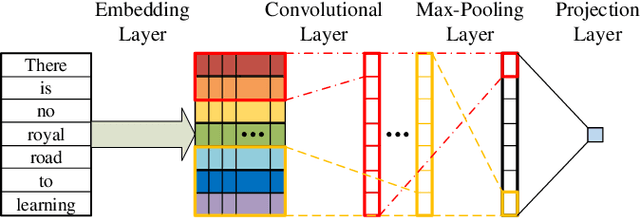
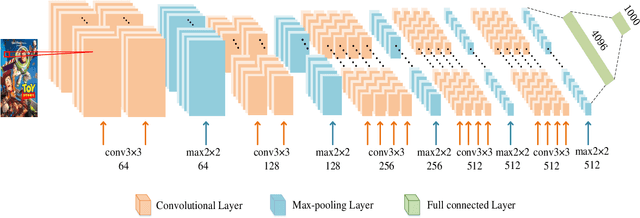
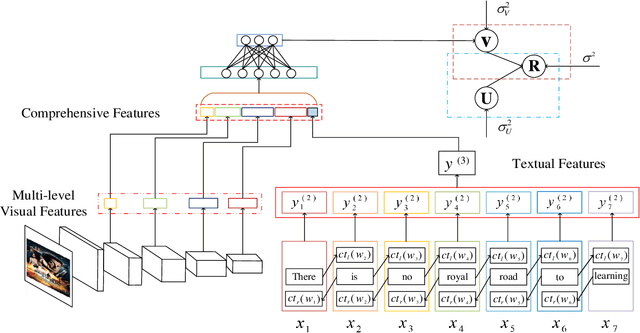
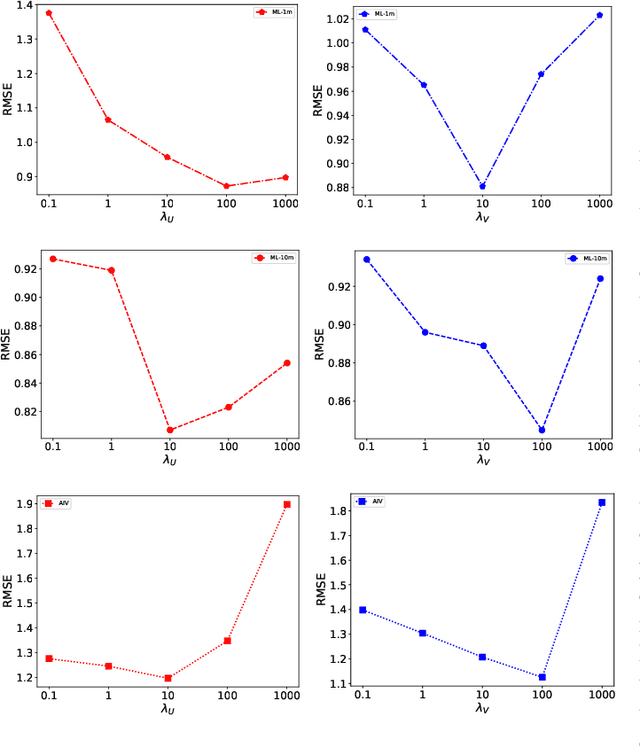
Sparsity of user-to-item rating data becomes one of challenging issues in the recommender systems, which severely deteriorates the recommendation performance. Fortunately, context-aware recommender systems can alleviate the sparsity problem by making use of some auxiliary information, such as the information of both the users and items. In particular, the visual information of items, such as the movie poster, can be considered as the supplement for item description documents, which helps to obtain more item features. In this paper, we focus on movie recommender system and propose a probabilistic matrix factorization based recommendation scheme called visual recurrent convolutional matrix factorization (VRConvMF), which utilizes the textual and multi-level visual features extracted from the descriptive texts and posters respectively. We implement the proposed VRConvMF and conduct extensive experiments on three commonly used real world datasets to validate its effectiveness. The experimental results illustrate that the proposed VRConvMF outperforms the existing schemes.
Complementary Fourier single-pixel imaging
Aug 02, 2021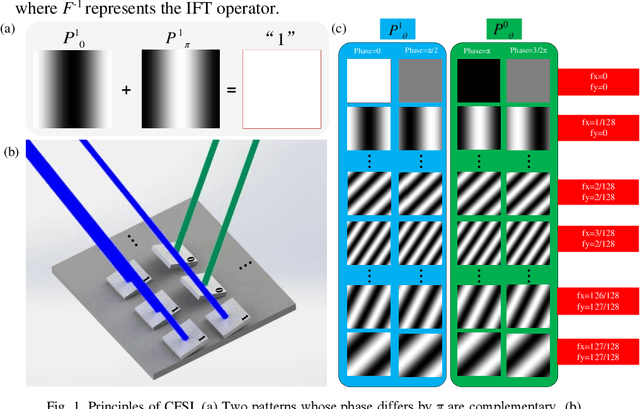
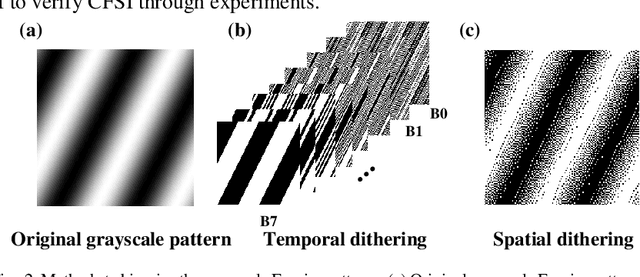


Single-pixel imaging, with the advantages of a wide spectrum, beyond-visual-field imaging, and robustness to light scattering, has attracted increasing attention in recent years. Fourier single-pixel imaging (FSI) can reconstruct sharp images under sub-Nyquist sampling. However, the conventional FSI has difficulty with balancing the imaging quality and efficiency. To overcome this issue, we proposed a novel approach called complementary Fourier single-pixel imaging (CFSI) to reduce measurements while retaining its robustness. The complementary nature of Fourier patterns based on a four-step phase-shift algorithm is combined with the complementary nature of a digital micromirror device. CFSI only requires two phase-shifted patterns to obtain one Fourier spectral value. Four light intensity values are obtained by load the two patterns, and the spectral value is calculated through differential measurement, which has good robustness to noise. The proposed method is verified by simulations and experiments compared with FSI based on two-, three-, and four-step phase shift algorithms. CFSI performed better than the other methods under the condition that the best imaging quality of CFSI is not reached. The reported technique provides an alternative approach to realize real-time and high-quality imaging.
Deeply Matting-based Dual Generative Adversarial Network for Image and Document Label Supervision
Sep 19, 2019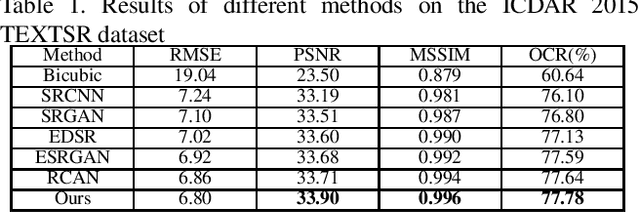
Although many methods have been proposed to deal with nature image super-resolution (SR) and get impressive performance, the text images SR is not good due to their ignorance of document images. In this paper, we propose a matting-based dual generative adversarial network (mdGAN) for document image SR. Firstly, the input image is decomposed into document text, foreground and background layers using deep image matting. Then two parallel branches are constructed to recover text boundary information and color information respectively. Furthermore, in order to improve the restoration accuracy of characters in output image, we use the input image's corresponding ground truth text label as extra supervise information to refine the two-branch networks during training. Experiments on real text images demonstrate that our method outperforms several state-of-the-art methods quantitatively and qualitatively.
Label-less Learning for Traffic Control in an Edge Network
Aug 29, 2018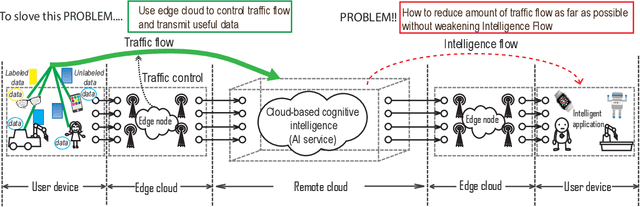
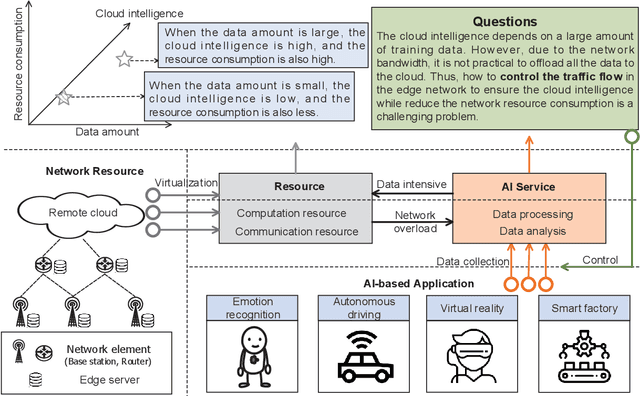
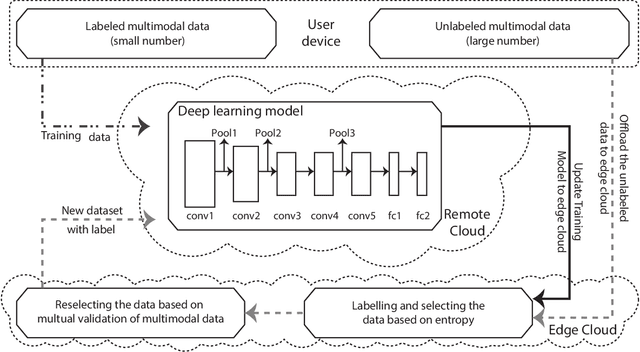
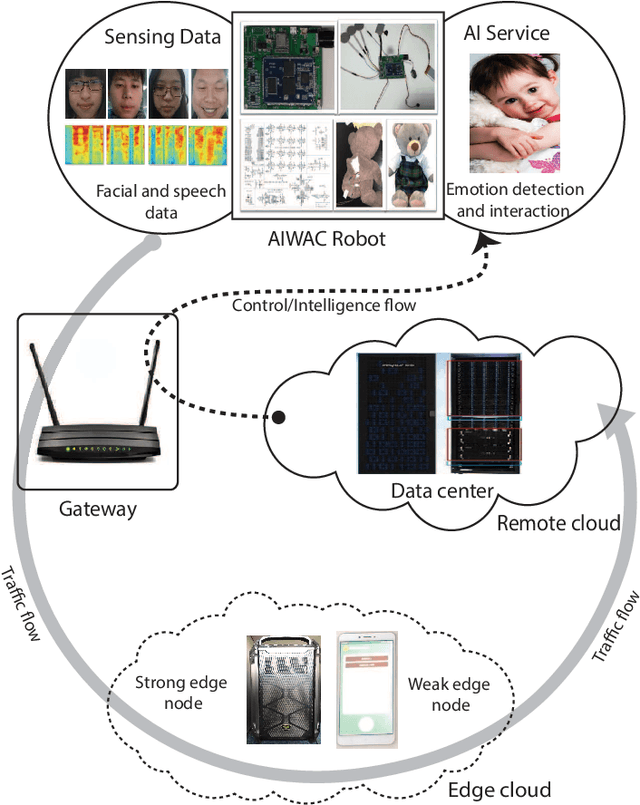
With the development of intelligent applications (e.g., self-driving, real-time emotion recognition, etc), there are higher requirements for the cloud intelligence. However, cloud intelligence depends on the multi-modal data collected by user equipments (UEs). Due to the limited capacity of network bandwidth, offloading all data generated from the UEs to the remote cloud is impractical. Thus, in this article, we consider the challenging issue of achieving a certain level of cloud intelligence while reducing network traffic. In order to solve this problem, we design a traffic control algorithm based on label-less learning on the edge cloud, which is dubbed as LLTC. By the use of the limited computing and storage resources at edge cloud, LLTC evaluates the value of data, which will be offloaded. Specifically, we first give a statement of the problem and the system architecture. Then, we design the LLTC algorithm in detail. Finally, we set up the system testbed. Experimental results show that the proposed LLTC can guarantee the required cloud intelligence while minimizing the amount of data transmission.