 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Energy-Efficient Edge Coprocessor for Neural Rendering with Explicit Data Reuse Strategies
Oct 09, 2025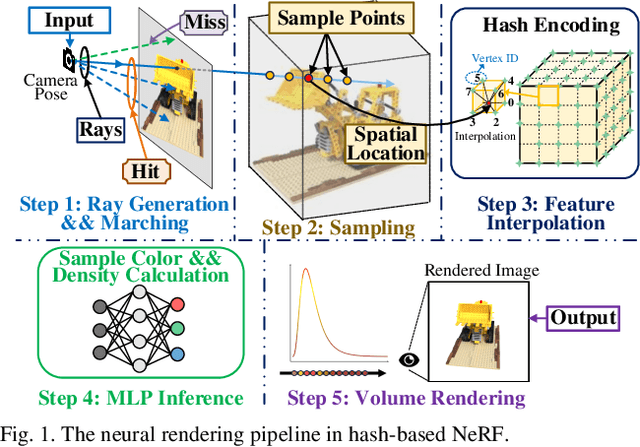
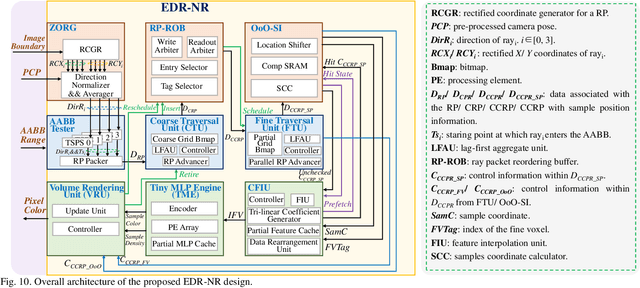
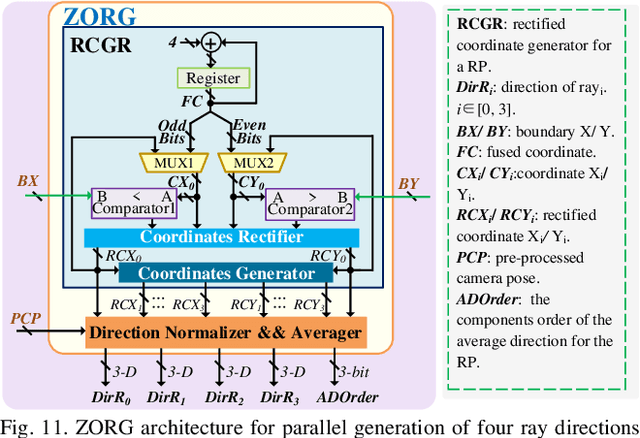
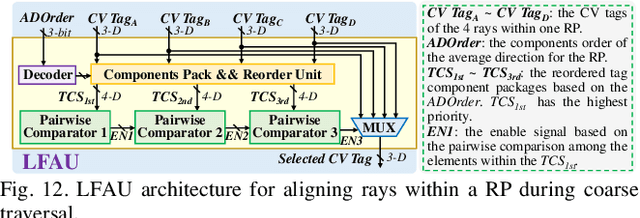
Neural radiance fields (NeRF) have transformed 3D reconstruction and rendering, facilitating photorealistic image synthesis from sparse viewpoints. This work introduces an explicit data reuse neural rendering (EDR-NR) architecture, which reduces frequent external memory accesses (EMAs) and cache misses by exploiting the spatial locality from three phases, including rays, ray packets (RPs), and samples. The EDR-NR architecture features a four-stage scheduler that clusters rays on the basis of Z-order, prioritize lagging rays when ray divergence happens, reorders RPs based on spatial proximity, and issues samples out-of-orderly (OoO) according to the availability of on-chip feature data. In addition, a four-tier hierarchical RP marching (HRM) technique is integrated with an axis-aligned bounding box (AABB) to facilitate spatial skipping (SS), reducing redundant computations and improving throughput. Moreover, a balanced allocation strategy for feature storage is proposed to mitigate SRAM bank conflicts. Fabricated using a 40 nm process with a die area of 10.5 mmX, the EDR-NR chip demonstrates a 2.41X enhancement in normalized energy efficiency, a 1.21X improvement in normalized area efficiency, a 1.20X increase in normalized throughput, and a 53.42% reduction in on-chip SRAM consumption compared to state-of-the-art accelerators.
A Rate-Distortion-Classification Approach for Lossy Image Compression
May 06, 2024
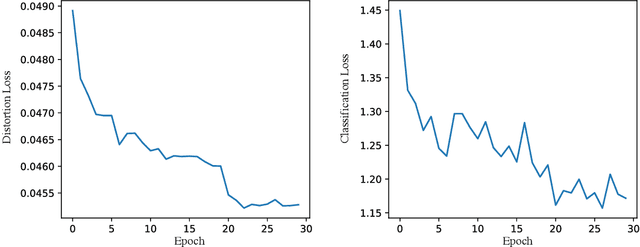

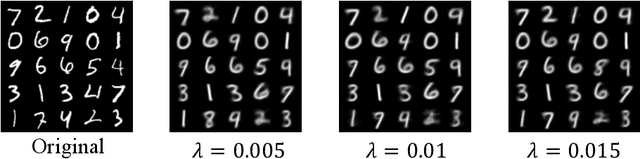
In lossy image compression, the objective is to achieve minimal signal distortion while compressing images to a specified bit rate. The increasing demand for visual analysis applications, particularly in classification tasks, has emphasized the significance of considering semantic distortion in compressed images. To bridge the gap between image compression and visual analysis, we propose a Rate-Distortion-Classification (RDC) model for lossy image compression, offering a unified framework to optimize the trade-off between rate, distortion, and classification accuracy. The RDC model is extensively analyzed both statistically on a multi-distribution source and experimentally on the widely used MNIST dataset. The findings reveal that the RDC model exhibits desirable properties, including monotonic non-increasing and convex functions, under certain conditions. This work provides insights into the development of human-machine friendly compression methods and Video Coding for Machine (VCM) approaches, paving the way for end-to-end image compression techniques in real-world applications.
* 15 pages
End-to-End Optimized Image Compression with the Frequency-Oriented Transform
Jan 16, 2024Image compression constitutes a significant challenge amidst the era of information explosion. Recent studies employing deep learning methods have demonstrated the superior performance of learning-based image compression methods over traditional codecs. However, an inherent challenge associated with these methods lies in their lack of interpretability. Following an analysis of the varying degrees of compression degradation across different frequency bands, we propose the end-to-end optimized image compression model facilitated by the frequency-oriented transform. The proposed end-to-end image compression model consists of four components: spatial sampling, frequency-oriented transform, entropy estimation, and frequency-aware fusion. The frequency-oriented transform separates the original image signal into distinct frequency bands, aligning with the human-interpretable concept. Leveraging the non-overlapping hypothesis, the model enables scalable coding through the selective transmission of arbitrary frequency components. Extensive experiments are conducted to demonstrate that our model outperforms all traditional codecs including next-generation standard H.266/VVC on MS-SSIM metric. Moreover, visual analysis tasks (i.e., object detection and semantic segmentation) are conducted to verify the proposed compression method could preserve semantic fidelity besides signal-level precision.
Machine Perception-Driven Image Compression: A Layered Generative Approach
Apr 14, 2023
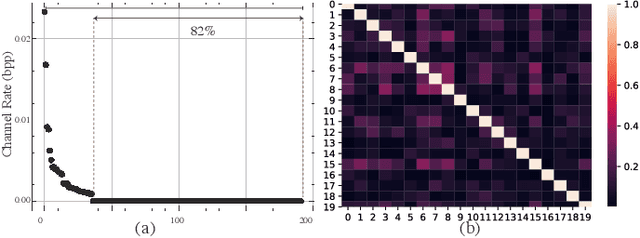


In this age of information, images are a critical medium for storing and transmitting information. With the rapid growth of image data amount, visual compression and visual data perception are two important research topics attracting a lot attention. However, those two topics are rarely discussed together and follow separate research path. Due to the compact compressed domain representation offered by learning-based image compression methods, there exists possibility to have one stream targeting both efficient data storage and compression, and machine perception tasks. In this paper, we propose a layered generative image compression model achieving high human vision-oriented image reconstructed quality, even at extreme compression ratios. To obtain analysis efficiency and flexibility, a task-agnostic learning-based compression model is proposed, which effectively supports various compressed domain-based analytical tasks while reserves outstanding reconstructed perceptual quality, compared with traditional and learning-based codecs. In addition, joint optimization schedule is adopted to acquire best balance point among compression ratio, reconstructed image quality, and downstream perception performance. Experimental results verify that our proposed compressed domain-based multi-task analysis method can achieve comparable analysis results against the RGB image-based methods with up to 99.6% bit rate saving (i.e., compared with taking original RGB image as the analysis model input). The practical ability of our model is further justified from model size and information fidelity aspects.
An Introduction to Matrix factorization and Factorization Machines in Recommendation System, and Beyond
Mar 12, 2022

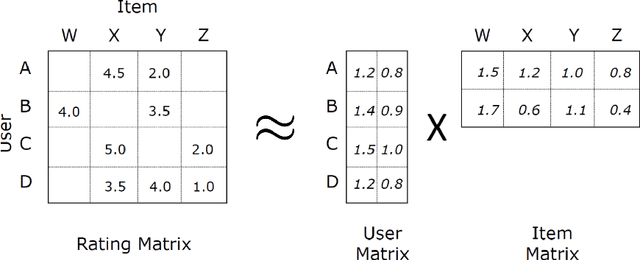
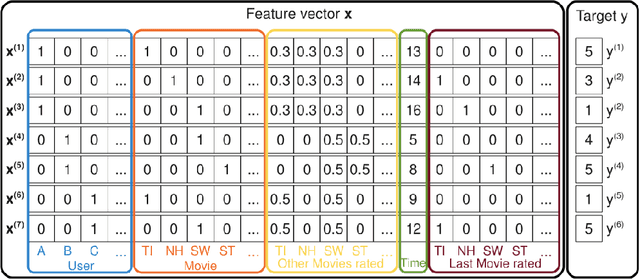
This paper aims at a better understanding of matrix factorization (MF), factorization machines (FM), and their combination with deep algorithms' application in recommendation systems. Specifically, this paper will focus on Singular Value Decomposition (SVD) and its derivations, e.g Funk-SVD, SVD++, etc. Step-by-step formula calculation and explainable pictures are displayed. What's more, we explain the DeepFM model in which FM is assisted by deep learning. Through numerical examples, we attempt to tie the theory to real-world problems.