 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTinySplat: Feedforward Approach for Generating Compact 3D Scene Representation
Jun 11, 2025



The recent development of feedforward 3D Gaussian Splatting (3DGS) presents a new paradigm to reconstruct 3D scenes. Using neural networks trained on large-scale multi-view datasets, it can directly infer 3DGS representations from sparse input views. Although the feedforward approach achieves high reconstruction speed, it still suffers from the substantial storage cost of 3D Gaussians. Existing 3DGS compression methods relying on scene-wise optimization are not applicable due to architectural incompatibilities. To overcome this limitation, we propose TinySplat, a complete feedforward approach for generating compact 3D scene representations. Built upon standard feedforward 3DGS methods, TinySplat integrates a training-free compression framework that systematically eliminates key sources of redundancy. Specifically, we introduce View-Projection Transformation (VPT) to reduce geometric redundancy by projecting geometric parameters into a more compact space. We further present Visibility-Aware Basis Reduction (VABR), which mitigates perceptual redundancy by aligning feature energy along dominant viewing directions via basis transformation. Lastly, spatial redundancy is addressed through an off-the-shelf video codec. Comprehensive experimental results on multiple benchmark datasets demonstrate that TinySplat achieves over 100x compression for 3D Gaussian data generated by feedforward methods. Compared to the state-of-the-art compression approach, we achieve comparable quality with only 6% of the storage size. Meanwhile, our compression framework requires only 25% of the encoding time and 1% of the decoding time.
ProSplat: Improved Feed-Forward 3D Gaussian Splatting for Wide-Baseline Sparse Views
Jun 09, 2025Feed-forward 3D Gaussian Splatting (3DGS) has recently demonstrated promising results for novel view synthesis (NVS) from sparse input views, particularly under narrow-baseline conditions. However, its performance significantly degrades in wide-baseline scenarios due to limited texture details and geometric inconsistencies across views. To address these challenges, in this paper, we propose ProSplat, a two-stage feed-forward framework designed for high-fidelity rendering under wide-baseline conditions. The first stage involves generating 3D Gaussian primitives via a 3DGS generator. In the second stage, rendered views from these primitives are enhanced through an improvement model. Specifically, this improvement model is based on a one-step diffusion model, further optimized by our proposed Maximum Overlap Reference view Injection (MORI) and Distance-Weighted Epipolar Attention (DWEA). MORI supplements missing texture and color by strategically selecting a reference view with maximum viewpoint overlap, while DWEA enforces geometric consistency using epipolar constraints. Additionally, we introduce a divide-and-conquer training strategy that aligns data distributions between the two stages through joint optimization. We evaluate ProSplat on the RealEstate10K and DL3DV-10K datasets under wide-baseline settings. Experimental results demonstrate that ProSplat achieves an average improvement of 1 dB in PSNR compared to recent SOTA methods.
Emerging Advances in Learned Video Compression: Models, Systems and Beyond
Apr 30, 2025Video compression is a fundamental topic in the visual intelligence, bridging visual signal sensing/capturing and high-level visual analytics. The broad success of artificial intelligence (AI) technology has enriched the horizon of video compression into novel paradigms by leveraging end-to-end optimized neural models. In this survey, we first provide a comprehensive and systematic overview of recent literature on end-to-end optimized learned video coding, covering the spectrum of pioneering efforts in both uni-directional and bi-directional prediction based compression model designation. We further delve into the optimization techniques employed in learned video compression (LVC), emphasizing their technical innovations, advantages. Some standardization progress is also reported. Furthermore, we investigate the system design and hardware implementation challenges of the LVC inclusively. Finally, we present the extensive simulation results to demonstrate the superior compression performance of LVC models, addressing the question that why learned codecs and AI-based video technology would have with broad impact on future visual intelligence research.
ShiftLIC: Lightweight Learned Image Compression with Spatial-Channel Shift Operations
Mar 29, 2025Learned Image Compression (LIC) has attracted considerable attention due to their outstanding rate-distortion (R-D) performance and flexibility. However, the substantial computational cost poses challenges for practical deployment. The issue of feature redundancy in LIC is rarely addressed. Our findings indicate that many features within the LIC backbone network exhibit similarities. This paper introduces ShiftLIC, a novel and efficient LIC framework that employs parameter-free shift operations to replace large-kernel convolutions, significantly reducing the model's computational burden and parameter count. Specifically, we propose the Spatial Shift Block (SSB), which combines shift operations with small-kernel convolutions to replace large-kernel. This approach maintains feature extraction efficiency while reducing both computational complexity and model size. To further enhance the representation capability in the channel dimension, we propose a channel attention module based on recursive feature fusion. This module enhances feature interaction while minimizing computational overhead. Additionally, we introduce an improved entropy model integrated with the SSB module, making the entropy estimation process more lightweight and thereby comprehensively reducing computational costs. Experimental results demonstrate that ShiftLIC outperforms leading compression methods, such as VVC Intra and GMM, in terms of computational cost, parameter count, and decoding latency. Additionally, ShiftLIC sets a new SOTA benchmark with a BD-rate gain per MACs/pixel of -102.6\%, showcasing its potential for practical deployment in resource-constrained environments. The code is released at https://github.com/baoyu2020/ShiftLIC.
A Joint Visual Compression and Perception Framework for Neuralmorphic Spiking Camera
Mar 04, 2025The advent of neuralmorphic spike cameras has garnered significant attention for their ability to capture continuous motion with unparalleled temporal resolution.However, this imaging attribute necessitates considerable resources for binary spike data storage and transmission.In light of compression and spike-driven intelligent applications, we present the notion of Spike Coding for Intelligence (SCI), wherein spike sequences are compressed and optimized for both bit-rate and task performance.Drawing inspiration from the mammalian vision system, we propose a dual-pathway architecture for separate processing of spatial semantics and motion information, which is then merged to produce features for compression.A refinement scheme is also introduced to ensure consistency between decoded features and motion vectors.We further propose a temporal regression approach that integrates various motion dynamics, capitalizing on the advancements in warping and deformation simultaneously.Comprehensive experiments demonstrate our scheme achieves state-of-the-art (SOTA) performance for spike compression and analysis.We achieve an average 17.25% BD-rate reduction compared to SOTA codecs and a 4.3% accuracy improvement over SpiReco for spike-based classification, with 88.26% complexity reduction and 42.41% inference time saving on the encoding side.
LL-ICM: Image Compression for Low-level Machine Vision via Large Vision-Language Model
Dec 05, 2024



Image Compression for Machines (ICM) aims to compress images for machine vision tasks rather than human viewing. Current works predominantly concentrate on high-level tasks like object detection and semantic segmentation. However, the quality of original images is usually not guaranteed in the real world, leading to even worse perceptual quality or downstream task performance after compression. Low-level (LL) machine vision models, like image restoration models, can help improve such quality, and thereby their compression requirements should also be considered. In this paper, we propose a pioneered ICM framework for LL machine vision tasks, namely LL-ICM. By jointly optimizing compression and LL tasks, the proposed LL-ICM not only enriches its encoding ability in generalizing to versatile LL tasks but also optimizes the processing ability of down-stream LL task models, achieving mutual adaptation for image codecs and LL task models. Furthermore, we integrate large-scale vision-language models into the LL-ICM framework to generate more universal and distortion-robust feature embeddings for LL vision tasks. Therefore, one LL-ICM codec can generalize to multiple tasks. We establish a solid benchmark to evaluate LL-ICM, which includes extensive objective experiments by using both full and no-reference image quality assessments. Experimental results show that LL-ICM can achieve 22.65% BD-rate reductions over the state-of-the-art methods.
Advanced Learning-Based Inter Prediction for Future Video Coding
Nov 24, 2024



In the fourth generation Audio Video coding Standard (AVS4), the Inter Prediction Filter (INTERPF) reduces discontinuities between prediction and adjacent reconstructed pixels in inter prediction. The paper proposes a low complexity learning-based inter prediction (LLIP) method to replace the traditional INTERPF. LLIP enhances the filtering process by leveraging a lightweight neural network model, where parameters can be exported for efficient inference. Specifically, we extract pixels and coordinates utilized by the traditional INTERPF to form the training dataset. Subsequently, we export the weights and biases of the trained neural network model and implement the inference process without any third-party dependency, enabling seamless integration into video codec without relying on Libtorch, thus achieving faster inference speed. Ultimately, we replace the traditional handcraft filtering parameters in INTERPF with the learned optimal filtering parameters. This practical solution makes the combination of deep learning encoding tools with traditional video encoding schemes more efficient. Experimental results show that our approach achieves 0.01%, 0.31%, and 0.25% coding gain for the Y, U, and V components under the random access (RA) configuration on average.
A Neural-network Enhanced Video Coding Framework beyond ECM
Feb 21, 2024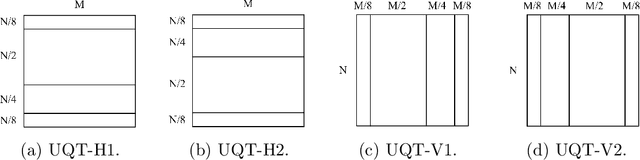

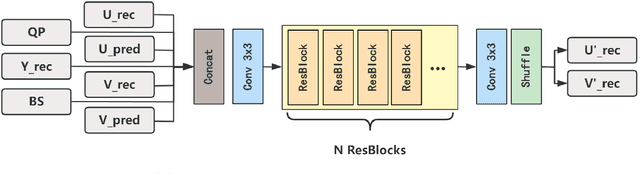
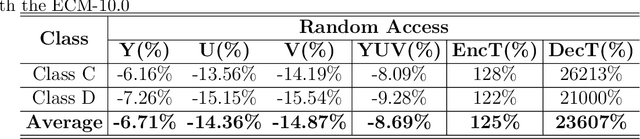
In this paper, a hybrid video compression framework is proposed that serves as a demonstrative showcase of deep learning-based approaches extending beyond the confines of traditional coding methodologies. The proposed hybrid framework is founded upon the Enhanced Compression Model (ECM), which is a further enhancement of the Versatile Video Coding (VVC) standard. We have augmented the latest ECM reference software with well-designed coding techniques, including block partitioning, deep learning-based loop filter, and the activation of block importance mapping (BIM) which was integrated but previously inactive within ECM, further enhancing coding performance. Compared with ECM-10.0, our method achieves 6.26, 13.33, and 12.33 BD-rate savings for the Y, U, and V components under random access (RA) configuration, respectively.
MPAI-EEV: Standardization Efforts of Artificial Intelligence based End-to-End Video Coding
Sep 14, 2023



The rapid advancement of artificial intelligence (AI) technology has led to the prioritization of standardizing the processing, coding, and transmission of video using neural networks. To address this priority area, the Moving Picture, Audio, and Data Coding by Artificial Intelligence (MPAI) group is developing a suite of standards called MPAI-EEV for "end-to-end optimized neural video coding." The aim of this AI-based video standard project is to compress the number of bits required to represent high-fidelity video data by utilizing data-trained neural coding technologies. This approach is not constrained by how data coding has traditionally been applied in the context of a hybrid framework. This paper presents an overview of recent and ongoing standardization efforts in this area and highlights the key technologies and design philosophy of EEV. It also provides a comparison and report on some primary efforts such as the coding efficiency of the reference model. Additionally, it discusses emerging activities such as learned Unmanned-Aerial-Vehicles (UAVs) video coding which are currently planned, under development, or in the exploration phase. With a focus on UAV video signals, this paper addresses the current status of these preliminary efforts. It also indicates development timelines, summarizes the main technical details, and provides pointers to further points of reference. The exploration experiment shows that the EEV model performs better than the state-of-the-art video coding standard H.266/VVC in terms of perceptual evaluation metric.
SpikeCodec: An End-to-end Learned Compression Framework for Spiking Camera
Jun 25, 2023

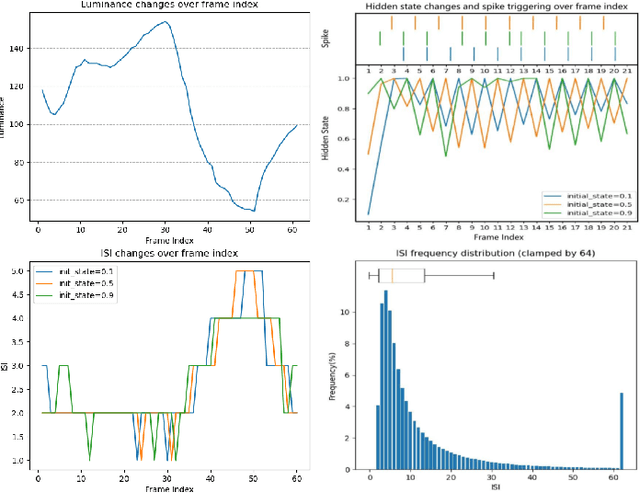

Recently, the bio-inspired spike camera with continuous motion recording capability has attracted tremendous attention due to its ultra high temporal resolution imaging characteristic. Such imaging feature results in huge data storage and transmission burden compared to that of traditional camera, raising severe challenge and imminent necessity in compression for spike camera captured content. Existing lossy data compression methods could not be applied for compressing spike streams efficiently due to integrate-and-fire characteristic and binarized data structure. Considering the imaging principle and information fidelity of spike cameras, we introduce an effective and robust representation of spike streams. Based on this representation, we propose a novel learned spike compression framework using scene recovery, variational auto-encoder plus spike simulator. To our knowledge, it is the first data-trained model for efficient and robust spike stream compression. Extensive experimental results show that our method outperforms the conventional and learning-based codecs, contributing a strong baseline for learned spike data compression.