 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBoosting Neural Video Representation via Online Structural Reparameterization
Nov 14, 2025Neural Video Representation~(NVR) is a promising paradigm for video compression, showing great potential in improving video storage and transmission efficiency. While recent advances have made efforts in architectural refinements to improve representational capability, these methods typically involve complex designs, which may incur increased computational overhead and lack the flexibility to integrate into other frameworks. Moreover, the inherent limitation in model capacity restricts the expressiveness of NVR networks, resulting in a performance bottleneck. To overcome these limitations, we propose Online-RepNeRV, a NVR framework based on online structural reparameterization. Specifically, we propose a universal reparameterization block named ERB, which incorporates multiple parallel convolutional paths to enhance the model capacity. To mitigate the overhead, an online reparameterization strategy is adopted to dynamically fuse the parameters during training, and the multi-branch structure is equivalently converted into a single-branch structure after training. As a result, the additional computational and parameter complexity is confined to the encoding stage, without affecting the decoding efficiency. Extensive experiments on mainstream video datasets demonstrate that our method achieves an average PSNR gain of 0.37-2.7 dB over baseline methods, while maintaining comparable training time and decoding speed.
* 15 pages, 7 figures
DynaQuant: Dynamic Mixed-Precision Quantization for Learned Image Compression
Nov 11, 2025Prevailing quantization techniques in Learned Image Compression (LIC) typically employ a static, uniform bit-width across all layers, failing to adapt to the highly diverse data distributions and sensitivity characteristics inherent in LIC models. This leads to a suboptimal trade-off between performance and efficiency. In this paper, we introduce DynaQuant, a novel framework for dynamic mixed-precision quantization that operates on two complementary levels. First, we propose content-aware quantization, where learnable scaling and offset parameters dynamically adapt to the statistical variations of latent features. This fine-grained adaptation is trained end-to-end using a novel Distance-aware Gradient Modulator (DGM), which provides a more informative learning signal than the standard Straight-Through Estimator. Second, we introduce a data-driven, dynamic bit-width selector that learns to assign an optimal bit precision to each layer, dynamically reconfiguring the network's precision profile based on the input data. Our fully dynamic approach offers substantial flexibility in balancing rate-distortion (R-D) performance and computational cost. Experiments demonstrate that DynaQuant achieves rd performance comparable to full-precision models while significantly reducing computational and storage requirements, thereby enabling the practical deployment of advanced LIC on diverse hardware platforms.
Dataset Distillation as Data Compression: A Rate-Utility Perspective
Jul 23, 2025Driven by the ``scale-is-everything'' paradigm, modern machine learning increasingly demands ever-larger datasets and models, yielding prohibitive computational and storage requirements. Dataset distillation mitigates this by compressing an original dataset into a small set of synthetic samples, while preserving its full utility. Yet, existing methods either maximize performance under fixed storage budgets or pursue suitable synthetic data representations for redundancy removal, without jointly optimizing both objectives. In this work, we propose a joint rate-utility optimization method for dataset distillation. We parameterize synthetic samples as optimizable latent codes decoded by extremely lightweight networks. We estimate the Shannon entropy of quantized latents as the rate measure and plug any existing distillation loss as the utility measure, trading them off via a Lagrange multiplier. To enable fair, cross-method comparisons, we introduce bits per class (bpc), a precise storage metric that accounts for sample, label, and decoder parameter costs. On CIFAR-10, CIFAR-100, and ImageNet-128, our method achieves up to $170\times$ greater compression than standard distillation at comparable accuracy. Across diverse bpc budgets, distillation losses, and backbone architectures, our approach consistently establishes better rate-utility trade-offs.
Motion Matters: Compact Gaussian Streaming for Free-Viewpoint Video Reconstruction
May 22, 20253D Gaussian Splatting (3DGS) has emerged as a high-fidelity and efficient paradigm for online free-viewpoint video (FVV) reconstruction, offering viewers rapid responsiveness and immersive experiences. However, existing online methods face challenge in prohibitive storage requirements primarily due to point-wise modeling that fails to exploit the motion properties. To address this limitation, we propose a novel Compact Gaussian Streaming (ComGS) framework, leveraging the locality and consistency of motion in dynamic scene, that models object-consistent Gaussian point motion through keypoint-driven motion representation. By transmitting only the keypoint attributes, this framework provides a more storage-efficient solution. Specifically, we first identify a sparse set of motion-sensitive keypoints localized within motion regions using a viewspace gradient difference strategy. Equipped with these keypoints, we propose an adaptive motion-driven mechanism that predicts a spatial influence field for propagating keypoint motion to neighboring Gaussian points with similar motion. Moreover, ComGS adopts an error-aware correction strategy for key frame reconstruction that selectively refines erroneous regions and mitigates error accumulation without unnecessary overhead. Overall, ComGS achieves a remarkable storage reduction of over 159 X compared to 3DGStream and 14 X compared to the SOTA method QUEEN, while maintaining competitive visual fidelity and rendering speed. Our code will be released.
NTIRE 2025 Challenge on Day and Night Raindrop Removal for Dual-Focused Images: Methods and Results
Apr 19, 2025



This paper reviews the NTIRE 2025 Challenge on Day and Night Raindrop Removal for Dual-Focused Images. This challenge received a wide range of impressive solutions, which are developed and evaluated using our collected real-world Raindrop Clarity dataset. Unlike existing deraining datasets, our Raindrop Clarity dataset is more diverse and challenging in degradation types and contents, which includes day raindrop-focused, day background-focused, night raindrop-focused, and night background-focused degradations. This dataset is divided into three subsets for competition: 14,139 images for training, 240 images for validation, and 731 images for testing. The primary objective of this challenge is to establish a new and powerful benchmark for the task of removing raindrops under varying lighting and focus conditions. There are a total of 361 participants in the competition, and 32 teams submitting valid solutions and fact sheets for the final testing phase. These submissions achieved state-of-the-art (SOTA) performance on the Raindrop Clarity dataset. The project can be found at https://lixinustc.github.io/CVPR-NTIRE2025-RainDrop-Competition.github.io/.
Content-Distortion High-Order Interaction for Blind Image Quality Assessment
Apr 07, 2025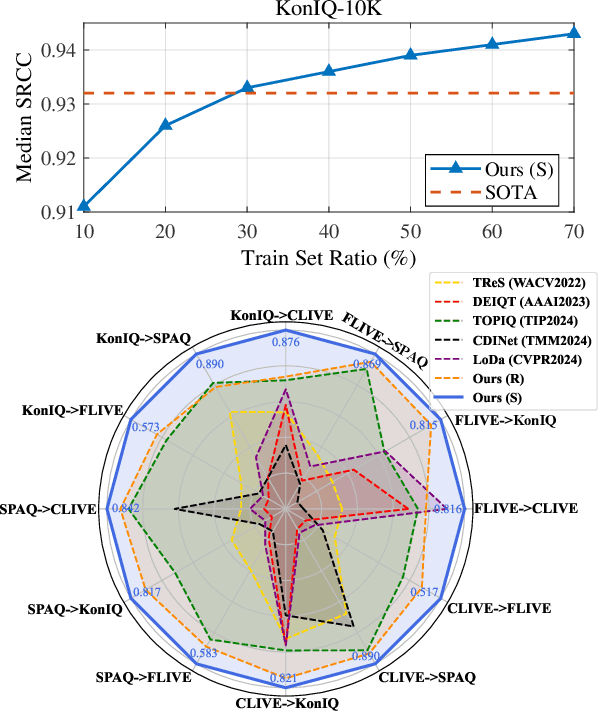
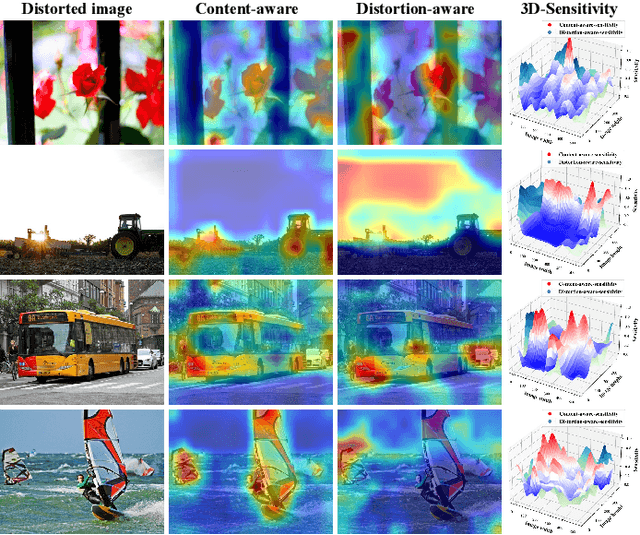
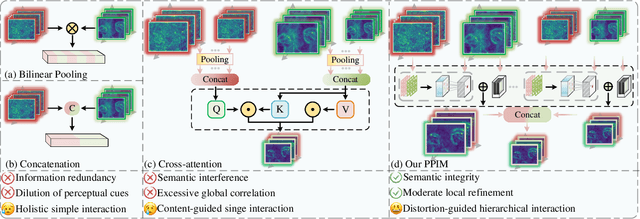
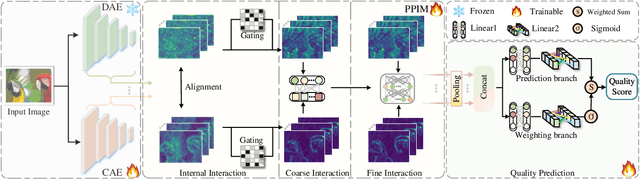
The content and distortion are widely recognized as the two primary factors affecting the visual quality of an image. While existing No-Reference Image Quality Assessment (NR-IQA) methods have modeled these factors, they fail to capture the complex interactions between content and distortions. This shortfall impairs their ability to accurately perceive quality. To confront this, we analyze the key properties required for interaction modeling and propose a robust NR-IQA approach termed CoDI-IQA (Content-Distortion high-order Interaction for NR-IQA), which aggregates local distortion and global content features within a hierarchical interaction framework. Specifically, a Progressive Perception Interaction Module (PPIM) is proposed to explicitly simulate how content and distortions independently and jointly influence image quality. By integrating internal interaction, coarse interaction, and fine interaction, it achieves high-order interaction modeling that allows the model to properly represent the underlying interaction patterns. To ensure sufficient interaction, multiple PPIMs are employed to hierarchically fuse multi-level content and distortion features at different granularities. We also tailor a training strategy suited for CoDI-IQA to maintain interaction stability. Extensive experiments demonstrate that the proposed method notably outperforms the state-of-the-art methods in terms of prediction accuracy, data efficiency, and generalization ability.
ShiftLIC: Lightweight Learned Image Compression with Spatial-Channel Shift Operations
Mar 29, 2025Learned Image Compression (LIC) has attracted considerable attention due to their outstanding rate-distortion (R-D) performance and flexibility. However, the substantial computational cost poses challenges for practical deployment. The issue of feature redundancy in LIC is rarely addressed. Our findings indicate that many features within the LIC backbone network exhibit similarities. This paper introduces ShiftLIC, a novel and efficient LIC framework that employs parameter-free shift operations to replace large-kernel convolutions, significantly reducing the model's computational burden and parameter count. Specifically, we propose the Spatial Shift Block (SSB), which combines shift operations with small-kernel convolutions to replace large-kernel. This approach maintains feature extraction efficiency while reducing both computational complexity and model size. To further enhance the representation capability in the channel dimension, we propose a channel attention module based on recursive feature fusion. This module enhances feature interaction while minimizing computational overhead. Additionally, we introduce an improved entropy model integrated with the SSB module, making the entropy estimation process more lightweight and thereby comprehensively reducing computational costs. Experimental results demonstrate that ShiftLIC outperforms leading compression methods, such as VVC Intra and GMM, in terms of computational cost, parameter count, and decoding latency. Additionally, ShiftLIC sets a new SOTA benchmark with a BD-rate gain per MACs/pixel of -102.6\%, showcasing its potential for practical deployment in resource-constrained environments. The code is released at https://github.com/baoyu2020/ShiftLIC.
Enhancing Adversarial Training with Prior Knowledge Distillation for Robust Image Compression
Mar 16, 2024



Deep neural network-based image compression (NIC) has achieved excellent performance, but NIC method models have been shown to be susceptible to backdoor attacks. Adversarial training has been validated in image compression models as a common method to enhance model robustness. However, the improvement effect of adversarial training on model robustness is limited. In this paper, we propose a prior knowledge-guided adversarial training framework for image compression models. Specifically, first, we propose a gradient regularization constraint for training robust teacher models. Subsequently, we design a knowledge distillation based strategy to generate a priori knowledge from the teacher model to the student model for guiding adversarial training. Experimental results show that our method improves the reconstruction quality by about 9dB when the Kodak dataset is elected as the backdoor attack object for psnr attack. Compared with Ma2023, our method has a 5dB higher PSNR output at high bitrate points.
Bandwidth-efficient Inference for Neural Image Compression
Sep 07, 2023



With neural networks growing deeper and feature maps growing larger, limited communication bandwidth with external memory (or DRAM) and power constraints become a bottleneck in implementing network inference on mobile and edge devices. In this paper, we propose an end-to-end differentiable bandwidth efficient neural inference method with the activation compressed by neural data compression method. Specifically, we propose a transform-quantization-entropy coding pipeline for activation compression with symmetric exponential Golomb coding and a data-dependent Gaussian entropy model for arithmetic coding. Optimized with existing model quantization methods, low-level task of image compression can achieve up to 19x bandwidth reduction with 6.21x energy saving.
Universal Learned Image Compression With Low Computational Cost
Jun 23, 2022


Recently, learned image compression methods have developed rapidly and exhibited excellent rate-distortion performance when compared to traditional standards, such as JPEG, JPEG2000 and BPG. However, the learning-based methods suffer from high computational costs, which is not beneficial for deployment on devices with limited resources. To this end, we propose shift-addition parallel modules (SAPMs), including SAPM-E for the encoder and SAPM-D for the decoder, to largely reduce the energy consumption. To be specific, they can be taken as plug-and-play components to upgrade existing CNN-based architectures, where the shift branch is used to extract large-grained features as compared to small-grained features learned by the addition branch. Furthermore, we thoroughly analyze the probability distribution of latent representations and propose to use Laplace Mixture Likelihoods for more accurate entropy estimation. Experimental results demonstrate that the proposed methods can achieve comparable or even better performance on both PSNR and MS-SSIM metrics to that of the convolutional counterpart with an about 2x energy reduction.