 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContext-aware Visual Tracking with Joint Meta-updating
Paper and Code
Apr 04, 2022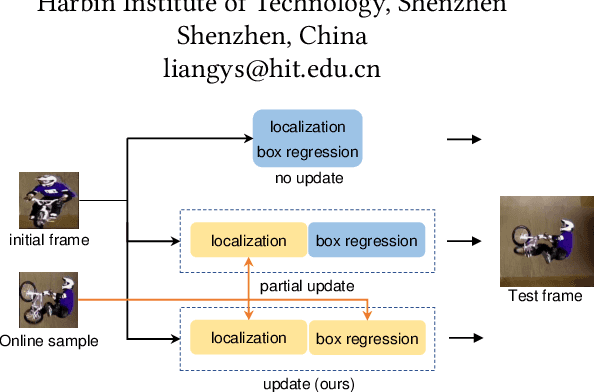
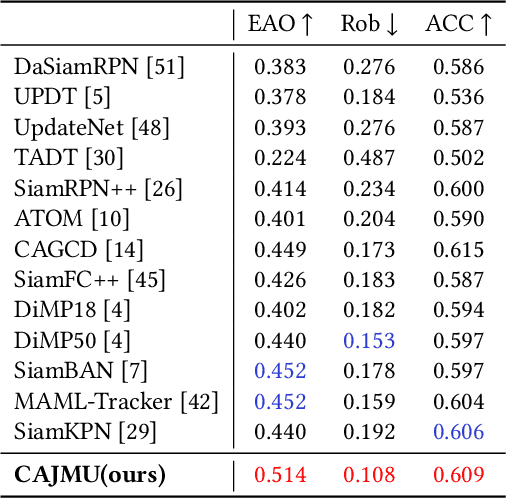


Visual object tracking acts as a pivotal component in various emerging video applications. Despite the numerous developments in visual tracking, existing deep trackers are still likely to fail when tracking against objects with dramatic variation. These deep trackers usually do not perform online update or update single sub-branch of the tracking model, for which they cannot adapt to the appearance variation of objects. Efficient updating methods are therefore crucial for tracking while previous meta-updater optimizes trackers directly over parameter space, which is prone to over-fit even collapse on longer sequences. To address these issues, we propose a context-aware tracking model to optimize the tracker over the representation space, which jointly meta-update both branches by exploiting information along the whole sequence, such that it can avoid the over-fitting problem. First, we note that the embedded features of the localization branch and the box-estimation branch, focusing on the local and global information of the target, are effective complements to each other. Based on this insight, we devise a context-aggregation module to fuse information in historical frames, followed by a context-aware module to learn affinity vectors for both branches of the tracker. Besides, we develop a dedicated meta-learning scheme, on account of fast and stable updating with limited training samples. The proposed tracking method achieves an EAO score of 0.514 on VOT2018 with the speed of 40FPS, demonstrating its capability of improving the accuracy and robustness of the underlying tracker with little speed drop.