 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerative Models at the Frontier of Compression: A Survey on Generative Face Video Coding
Jun 09, 2025The rise of deep generative models has greatly advanced video compression, reshaping the paradigm of face video coding through their powerful capability for semantic-aware representation and lifelike synthesis. Generative Face Video Coding (GFVC) stands at the forefront of this revolution, which could characterize complex facial dynamics into compact latent codes for bitstream compactness at the encoder side and leverages powerful deep generative models to reconstruct high-fidelity face signal from the compressed latent codes at the decoder side. As such, this well-designed GFVC paradigm could enable high-fidelity face video communication at ultra-low bitrate ranges, far surpassing the capabilities of the latest Versatile Video Coding (VVC) standard. To pioneer foundational research and accelerate the evolution of GFVC, this paper presents the first comprehensive survey of GFVC technologies, systematically bridging critical gaps between theoretical innovation and industrial standardization. In particular, we first review a broad range of existing GFVC methods with different feature representations and optimization strategies, and conduct a thorough benchmarking analysis. In addition, we construct a large-scale GFVC-compressed face video database with subjective Mean Opinion Scores (MOSs) based on human perception, aiming to identify the most appropriate quality metrics tailored to GFVC. Moreover, we summarize the GFVC standardization potentials with a unified high-level syntax and develop a low-complexity GFVC system which are both expected to push forward future practical deployments and applications. Finally, we envision the potential of GFVC in industrial applications and deliberate on the current challenges and future opportunities.
Compressing Human Body Video with Interactive Semantics: A Generative Approach
May 22, 2025In this paper, we propose to compress human body video with interactive semantics, which can facilitate video coding to be interactive and controllable by manipulating semantic-level representations embedded in the coded bitstream. In particular, the proposed encoder employs a 3D human model to disentangle nonlinear dynamics and complex motion of human body signal into a series of configurable embeddings, which are controllably edited, compactly compressed, and efficiently transmitted. Moreover, the proposed decoder can evolve the mesh-based motion fields from these decoded semantics to realize the high-quality human body video reconstruction. Experimental results illustrate that the proposed framework can achieve promising compression performance for human body videos at ultra-low bitrate ranges compared with the state-of-the-art video coding standard Versatile Video Coding (VVC) and the latest generative compression schemes. Furthermore, the proposed framework enables interactive human body video coding without any additional pre-/post-manipulation processes, which is expected to shed light on metaverse-related digital human communication in the future.
Pleno-Generation: A Scalable Generative Face Video Compression Framework with Bandwidth Intelligence
Feb 24, 2025



Generative model based compact video compression is typically operated within a relative narrow range of bitrates, and often with an emphasis on ultra-low rate applications. There has been an increasing consensus in the video communication industry that full bitrate coverage should be enabled by generative coding. However, this is an extremely difficult task, largely because generation and compression, although related, have distinct goals and trade-offs. The proposed Pleno-Generation (PGen) framework distinguishes itself through its exceptional capabilities in ensuring the robustness of video coding by utilizing a wider range of bandwidth for generation via bandwidth intelligence. In particular, we initiate our research of PGen with face video coding, and PGen offers a paradigm shift that prioritizes high-fidelity reconstruction over pursuing compact bitstream. The novel PGen framework leverages scalable representation and layered reconstruction for Generative Face Video Compression (GFVC), in an attempt to imbue the bitstream with intelligence in different granularity. Experimental results illustrate that the proposed PGen framework can facilitate existing GFVC algorithms to better deliver high-fidelity and faithful face videos. In addition, the proposed framework can allow a greater space of flexibility for coding applications and show superior RD performance with a much wider bitrate range in terms of various quality evaluations. Moreover, in comparison with the latest Versatile Video Coding (VVC) codec, the proposed scheme achieves competitive Bj{\o}ntegaard-delta-rate savings for perceptual-level evaluations.
Standardizing Generative Face Video Compression using Supplemental Enhancement Information
Oct 19, 2024This paper proposes a Generative Face Video Compression (GFVC) approach using Supplemental Enhancement Information (SEI), where a series of compact spatial and temporal representations of a face video signal (i.e., 2D/3D key-points, facial semantics and compact features) can be coded using SEI message and inserted into the coded video bitstream. At the time of writing, the proposed GFVC approach is an official "technology under consideration" (TuC) for standardization by the Joint Video Experts Team (JVET) of ISO/IEC JVT 1/SC 29 and ITU-T SG16. To the best of the authors' knowledge, the JVET work on the proposed SEI-based GFVC approach is the first standardization activity for generative video compression. The proposed SEI approach has not only advanced the reconstruction quality of early-day Model-Based Coding (MBC) via the state-of-the-art generative technique, but also established a new SEI definition for future GFVC applications and deployment. Experimental results illustrate that the proposed SEI-based GFVC approach can achieve remarkable rate-distortion performance compared with the latest Versatile Video Coding (VVC) standard, whilst also potentially enabling a wide variety of functionalities including user-specified animation/filtering and metaverse-related applications.
Generative Human Video Compression with Multi-granularity Temporal Trajectory Factorization
Oct 14, 2024



In this paper, we propose a novel Multi-granularity Temporal Trajectory Factorization framework for generative human video compression, which holds great potential for bandwidth-constrained human-centric video communication. In particular, the proposed motion factorization strategy can facilitate to implicitly characterize the high-dimensional visual signal into compact motion vectors for representation compactness and further transform these vectors into a fine-grained field for motion expressibility. As such, the coded bit-stream can be entailed with enough visual motion information at the lowest representation cost. Meanwhile, a resolution-expandable generative module is developed with enhanced background stability, such that the proposed framework can be optimized towards higher reconstruction robustness and more flexible resolution adaptation. Experimental results show that proposed method outperforms latest generative models and the state-of-the-art video coding standard Versatile Video Coding (VVC) on both talking-face videos and moving-body videos in terms of both objective and subjective quality. The project page can be found at https://github.com/xyzysz/Extreme-Human-Video-Compression-with-MTTF.
Compressing Scene Dynamics: A Generative Approach
Oct 13, 2024This paper proposes to learn generative priors from the motion patterns instead of video contents for generative video compression. The priors are derived from small motion dynamics in common scenes such as swinging trees in the wind and floating boat on the sea. Utilizing such compact motion priors, a novel generative scene dynamics compression framework is built to realize ultra-low bit-rate communication and high-quality reconstruction for diverse scene contents. At the encoder side, motion priors are characterized into compact representations in a dense-to-sparse manner. At the decoder side, the decoded motion priors serve as the trajectory hints for scene dynamics reconstruction via a diffusion-based flow-driven generator. The experimental results illustrate that the proposed method can achieve superior rate-distortion performance and outperform the state-of-the-art conventional video codec Versatile Video Coding (VVC) on scene dynamics sequences. The project page can be found at https://github.com/xyzysz/GNVDC.
Beyond GFVC: A Progressive Face Video Compression Framework with Adaptive Visual Tokens
Oct 11, 2024Recently, deep generative models have greatly advanced the progress of face video coding towards promising rate-distortion performance and diverse application functionalities. Beyond traditional hybrid video coding paradigms, Generative Face Video Compression (GFVC) relying on the strong capabilities of deep generative models and the philosophy of early Model-Based Coding (MBC) can facilitate the compact representation and realistic reconstruction of visual face signal, thus achieving ultra-low bitrate face video communication. However, these GFVC algorithms are sometimes faced with unstable reconstruction quality and limited bitrate ranges. To address these problems, this paper proposes a novel Progressive Face Video Compression framework, namely PFVC, that utilizes adaptive visual tokens to realize exceptional trade-offs between reconstruction robustness and bandwidth intelligence. In particular, the encoder of the proposed PFVC projects the high-dimensional face signal into adaptive visual tokens in a progressive manner, whilst the decoder can further reconstruct these adaptive visual tokens for motion estimation and signal synthesis with different granularity levels. Experimental results demonstrate that the proposed PFVC framework can achieve better coding flexibility and superior rate-distortion performance in comparison with the latest Versatile Video Coding (VVC) codec and the state-of-the-art GFVC algorithms. The project page can be found at https://github.com/Berlin0610/PFVC.
Generative Visual Compression: A Review
Feb 03, 2024Artificial Intelligence Generated Content (AIGC) is leading a new technical revolution for the acquisition of digital content and impelling the progress of visual compression towards competitive performance gains and diverse functionalities over traditional codecs. This paper provides a thorough review on the recent advances of generative visual compression, illustrating great potentials and promising applications in ultra-low bitrate communication, user-specified reconstruction/filtering, and intelligent machine analysis. In particular, we review the visual data compression methodologies with deep generative models, and summarize how compact representation and high-fidelity reconstruction could be actualized via generative techniques. In addition, we generalize related generative compression technologies for machine vision and intelligent analytics. Finally, we discuss the fundamental challenges on generative visual compression techniques and envision their future research directions.
Bandwidth-efficient Inference for Neural Image Compression
Sep 07, 2023



With neural networks growing deeper and feature maps growing larger, limited communication bandwidth with external memory (or DRAM) and power constraints become a bottleneck in implementing network inference on mobile and edge devices. In this paper, we propose an end-to-end differentiable bandwidth efficient neural inference method with the activation compressed by neural data compression method. Specifically, we propose a transform-quantization-entropy coding pipeline for activation compression with symmetric exponential Golomb coding and a data-dependent Gaussian entropy model for arithmetic coding. Optimized with existing model quantization methods, low-level task of image compression can achieve up to 19x bandwidth reduction with 6.21x energy saving.
Exploring Structural Sparsity in Neural Image Compression
Feb 24, 2022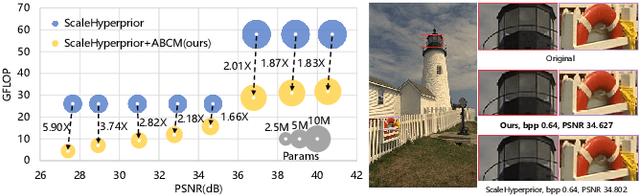
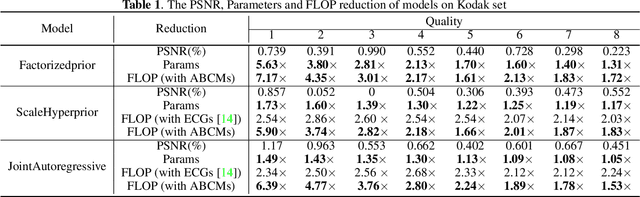
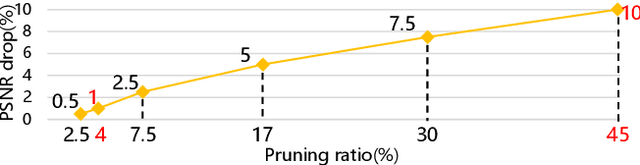

Neural image compression have reached or out-performed traditional methods (such as JPEG, BPG, WebP). However,their sophisticated network structures with cascaded convolution layers bring heavy computational burden for practical deployment. In this paper, we explore the structural sparsity in neural image compression network to obtain real-time acceleration without any specialized hardware design or algorithm. We propose a simple plug-in adaptive binary channel masking(ABCM) to judge the importance of each convolution channel and introduce sparsity during training. During inference, the unimportant channels are pruned to obtain slimmer network and less computation. We implement our method into three neural image compression networks with different entropy models to verify its effectiveness and generalization, the experiment results show that up to 7x computation reduction and 3x acceleration can be achieved with negligible performance drop.