 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHybridINR-PCGC: Hybrid Lossless Point Cloud Geometry Compression Bridging Pretrained Model and Implicit Neural Representation
Feb 25, 2026Learning-based point cloud compression presents superior performance to handcrafted codecs. However, pretrained-based methods, which are based on end-to-end training and expected to generalize to all the potential samples, suffer from training data dependency. Implicit neural representation (INR) based methods are distribution-agnostic and more robust, but they require time-consuming online training and suffer from the bitstream overhead from the overfitted model. To address these limitations, we propose HybridINR-PCGC, a novel hybrid framework that bridges the pretrained model and INR. Our framework retains distribution-agnostic properties while leveraging a pretrained network to accelerate convergence and reduce model overhead, which consists of two parts: the Pretrained Prior Network (PPN) and the Distribution Agnostic Refiner (DAR). We leverage the PPN, designed for fast inference and stable performance, to generate a robust prior for accelerating the DAR's convergence. The DAR is decomposed into a base layer and an enhancement layer, and only the enhancement layer needed to be packed into the bitstream. Finally, we propose a supervised model compression module to further supervise and minimize the bitrate of the enhancement layer parameters. Based on experiment results, HybridINR-PCGC achieves a significantly improved compression rate and encoding efficiency. Specifically, our method achieves a Bpp reduction of approximately 20.43% compared to G-PCC on 8iVFB. In the challenging out-of-distribution scenario Cat1B, our method achieves a Bpp reduction of approximately 57.85% compared to UniPCGC. And our method exhibits a superior time-rate trade-off, achieving an average Bpp reduction of 15.193% relative to the LINR-PCGC on 8iVFB.
RAP: Fast Feedforward Rendering-Free Attribute-Guided Primitive Importance Score Prediction for Efficient 3D Gaussian Splatting Processing
Feb 23, 20263D Gaussian Splatting (3DGS) has emerged as a leading technology for high-quality 3D scene reconstruction. However, the iterative refinement and densification process leads to the generation of a large number of primitives, each contributing to the reconstruction to a substantially different extent. Estimating primitive importance is thus crucial, both for removing redundancy during reconstruction and for enabling efficient compression and transmission. Existing methods typically rely on rendering-based analyses, where each primitive is evaluated through its contribution across multiple camera viewpoints. However, such methods are sensitive to the number and selection of views, rely on specialized differentiable rasterizers, and have long calculation times that grow linearly with view count, making them difficult to integrate as plug-and-play modules and limiting scalability and generalization. To address these issues, we propose RAP, a fast feedforward rendering-free attribute-guided method for efficient importance score prediction in 3DGS. RAP infers primitive significance directly from intrinsic Gaussian attributes and local neighborhood statistics, avoiding rendering-based or visibility-dependent computations. A compact MLP predicts per-primitive importance scores using rendering loss, pruning-aware loss, and significance distribution regularization. After training on a small set of scenes, RAP generalizes effectively to unseen data and can be seamlessly integrated into reconstruction, compression, and transmission pipelines. Our code is publicly available at https://github.com/yyyykf/RAP.
TVMC: Time-Varying Mesh Compression via Multi-Stage Anchor Mesh Generation
Oct 26, 2025Time-varying meshes, characterized by dynamic connectivity and varying vertex counts, hold significant promise for applications such as augmented reality. However, their practical utilization remains challenging due to the substantial data volume required for high-fidelity representation. While various compression methods attempt to leverage temporal redundancy between consecutive mesh frames, most struggle with topological inconsistency and motion-induced artifacts. To address these issues, we propose Time-Varying Mesh Compression (TVMC), a novel framework built on multi-stage coarse-to-fine anchor mesh generation for inter-frame prediction. Specifically, the anchor mesh is progressively constructed in three stages: initial, coarse, and fine. The initial anchor mesh is obtained through fast topology alignment to exploit temporal coherence. A Kalman filter-based motion estimation module then generates a coarse anchor mesh by accurately compensating inter-frame motions. Subsequently, a Quadric Error Metric-based refinement step optimizes vertex positions to form a fine anchor mesh with improved geometric fidelity. Based on the refined anchor mesh, the inter-frame motions relative to the reference base mesh are encoded, while the residual displacements between the subdivided fine anchor mesh and the input mesh are adaptively quantized and compressed. This hierarchical strategy preserves consistent connectivity and high-quality surface approximation, while achieving an efficient and compact representation of dynamic geometry. Extensive experiments on standard MPEG dynamic mesh sequences demonstrate that TVMC achieves state-of-the-art compression performance. Compared to the latest V-DMC standard, it delivers a significant BD-rate gain of 10.2% ~ 16.9%, while preserving high reconstruction quality. The code is available at https://github.com/H-Huang774/TVMC.
3DGS-VBench: A Comprehensive Video Quality Evaluation Benchmark for 3DGS Compression
Aug 09, 20253D Gaussian Splatting (3DGS) enables real-time novel view synthesis with high visual fidelity, but its substantial storage requirements hinder practical deployment, prompting state-of-the-art (SOTA) 3DGS methods to incorporate compression modules. However, these 3DGS generative compression techniques introduce unique distortions lacking systematic quality assessment research. To this end, we establish 3DGS-VBench, a large-scale Video Quality Assessment (VQA) Dataset and Benchmark with 660 compressed 3DGS models and video sequences generated from 11 scenes across 6 SOTA 3DGS compression algorithms with systematically designed parameter levels. With annotations from 50 participants, we obtained MOS scores with outlier removal and validated dataset reliability. We benchmark 6 3DGS compression algorithms on storage efficiency and visual quality, and evaluate 15 quality assessment metrics across multiple paradigms. Our work enables specialized VQA model training for 3DGS, serving as a catalyst for compression and quality assessment research. The dataset is available at https://github.com/YukeXing/3DGS-VBench.
3DGS-IEval-15K: A Large-scale Image Quality Evaluation Database for 3D Gaussian-Splatting
Jun 17, 20253D Gaussian Splatting (3DGS) has emerged as a promising approach for novel view synthesis, offering real-time rendering with high visual fidelity. However, its substantial storage requirements present significant challenges for practical applications. While recent state-of-the-art (SOTA) 3DGS methods increasingly incorporate dedicated compression modules, there is a lack of a comprehensive framework to evaluate their perceptual impact. Therefore we present 3DGS-IEval-15K, the first large-scale image quality assessment (IQA) dataset specifically designed for compressed 3DGS representations. Our dataset encompasses 15,200 images rendered from 10 real-world scenes through 6 representative 3DGS algorithms at 20 strategically selected viewpoints, with different compression levels leading to various distortion effects. Through controlled subjective experiments, we collect human perception data from 60 viewers. We validate dataset quality through scene diversity and MOS distribution analysis, and establish a comprehensive benchmark with 30 representative IQA metrics covering diverse types. As the largest-scale 3DGS quality assessment dataset to date, our work provides a foundation for developing 3DGS specialized IQA metrics, and offers essential data for investigating view-dependent quality distribution patterns unique to 3DGS. The database is publicly available at https://github.com/YukeXing/3DGS-IEval-15K.
Rasterizing Wireless Radiance Field via Deformable 2D Gaussian Splatting
Jun 15, 2025Modeling the wireless radiance field (WRF) is fundamental to modern communication systems, enabling key tasks such as localization, sensing, and channel estimation. Traditional approaches, which rely on empirical formulas or physical simulations, often suffer from limited accuracy or require strong scene priors. Recent neural radiance field (NeRF-based) methods improve reconstruction fidelity through differentiable volumetric rendering, but their reliance on computationally expensive multilayer perceptron (MLP) queries hinders real-time deployment. To overcome these challenges, we introduce Gaussian splatting (GS) to the wireless domain, leveraging its efficiency in modeling optical radiance fields to enable compact and accurate WRF reconstruction. Specifically, we propose SwiftWRF, a deformable 2D Gaussian splatting framework that synthesizes WRF spectra at arbitrary positions under single-sided transceiver mobility. SwiftWRF employs CUDA-accelerated rasterization to render spectra at over 100000 fps and uses a lightweight MLP to model the deformation of 2D Gaussians, effectively capturing mobility-induced WRF variations. In addition to novel spectrum synthesis, the efficacy of SwiftWRF is further underscored in its applications in angle-of-arrival (AoA) and received signal strength indicator (RSSI) prediction. Experiments conducted on both real-world and synthetic indoor scenes demonstrate that SwiftWRF can reconstruct WRF spectra up to 500x faster than existing state-of-the-art methods, while significantly enhancing its signal quality. Code and datasets will be released.
DPCD: A Quality Assessment Database for Dynamic Point Clouds
May 18, 2025
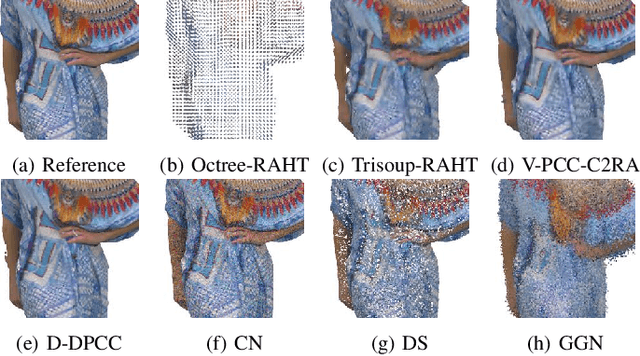
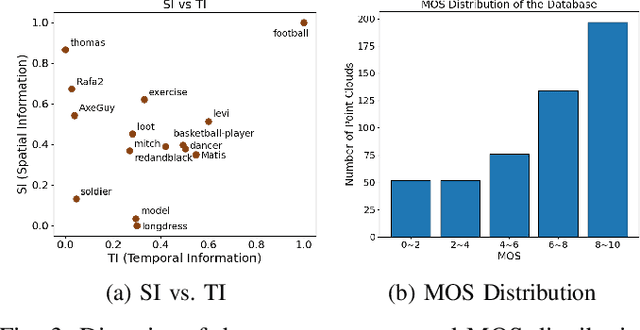
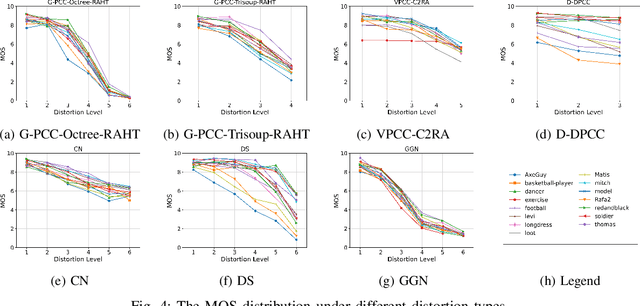
Recently, the advancements in Virtual/Augmented Reality (VR/AR) have driven the demand for Dynamic Point Clouds (DPC). Unlike static point clouds, DPCs are capable of capturing temporal changes within objects or scenes, offering a more accurate simulation of the real world. While significant progress has been made in the quality assessment research of static point cloud, little study has been done on Dynamic Point Cloud Quality Assessment (DPCQA), which hinders the development of quality-oriented applications, such as interframe compression and transmission in practical scenarios. In this paper, we introduce a large-scale DPCQA database, named DPCD, which includes 15 reference DPCs and 525 distorted DPCs from seven types of lossy compression and noise distortion. By rendering these samples to Processed Video Sequences (PVS), a comprehensive subjective experiment is conducted to obtain Mean Opinion Scores (MOS) from 21 viewers for analysis. The characteristic of contents, impact of various distortions, and accuracy of MOSs are presented to validate the heterogeneity and reliability of the proposed database. Furthermore, we evaluate the performance of several objective metrics on DPCD. The experiment results show that DPCQA is more challenge than that of static point cloud. The DPCD, which serves as a catalyst for new research endeavors on DPCQA, is publicly available at https://huggingface.co/datasets/Olivialyt/DPCD.
Textured mesh Quality Assessment using Geometry and Color Field Similarity
May 16, 2025Textured mesh quality assessment (TMQA) is critical for various 3D mesh applications. However, existing TMQA methods often struggle to provide accurate and robust evaluations. Motivated by the effectiveness of fields in representing both 3D geometry and color information, we propose a novel point-based TMQA method called field mesh quality metric (FMQM). FMQM utilizes signed distance fields and a newly proposed color field named nearest surface point color field to realize effective mesh feature description. Four features related to visual perception are extracted from the geometry and color fields: geometry similarity, geometry gradient similarity, space color distribution similarity, and space color gradient similarity. Experimental results on three benchmark datasets demonstrate that FMQM outperforms state-of-the-art (SOTA) TMQA metrics. Furthermore, FMQM exhibits low computational complexity, making it a practical and efficient solution for real-world applications in 3D graphics and visualization. Our code is publicly available at: https://github.com/yyyykf/FMQM.
ADC-GS: Anchor-Driven Deformable and Compressed Gaussian Splatting for Dynamic Scene Reconstruction
May 13, 2025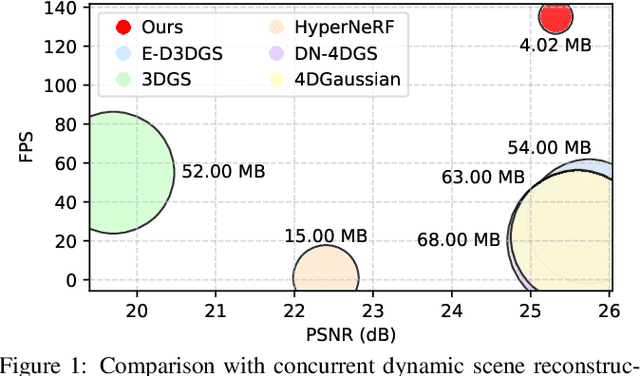


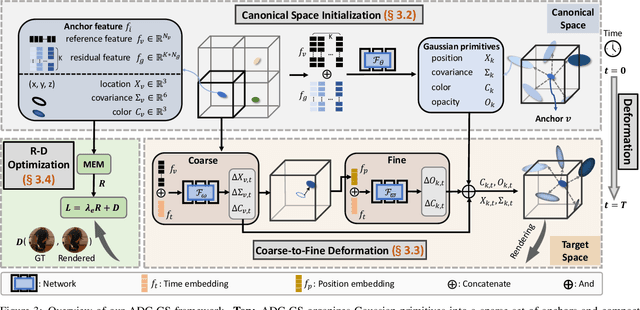
Existing 4D Gaussian Splatting methods rely on per-Gaussian deformation from a canonical space to target frames, which overlooks redundancy among adjacent Gaussian primitives and results in suboptimal performance. To address this limitation, we propose Anchor-Driven Deformable and Compressed Gaussian Splatting (ADC-GS), a compact and efficient representation for dynamic scene reconstruction. Specifically, ADC-GS organizes Gaussian primitives into an anchor-based structure within the canonical space, enhanced by a temporal significance-based anchor refinement strategy. To reduce deformation redundancy, ADC-GS introduces a hierarchical coarse-to-fine pipeline that captures motions at varying granularities. Moreover, a rate-distortion optimization is adopted to achieve an optimal balance between bitrate consumption and representation fidelity. Experimental results demonstrate that ADC-GS outperforms the per-Gaussian deformation approaches in rendering speed by 300%-800% while achieving state-of-the-art storage efficiency without compromising rendering quality. The code is released at https://github.com/H-Huang774/ADC-GS.git.
Light4GS: Lightweight Compact 4D Gaussian Splatting Generation via Context Model
Mar 18, 2025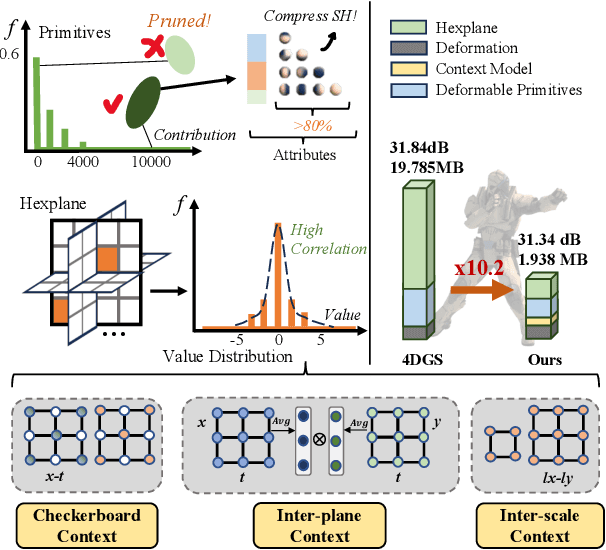



3D Gaussian Splatting (3DGS) has emerged as an efficient and high-fidelity paradigm for novel view synthesis. To adapt 3DGS for dynamic content, deformable 3DGS incorporates temporally deformable primitives with learnable latent embeddings to capture complex motions. Despite its impressive performance, the high-dimensional embeddings and vast number of primitives lead to substantial storage requirements. In this paper, we introduce a \textbf{Light}weight \textbf{4}D\textbf{GS} framework, called Light4GS, that employs significance pruning with a deep context model to provide a lightweight storage-efficient dynamic 3DGS representation. The proposed Light4GS is based on 4DGS that is a typical representation of deformable 3DGS. Specifically, our framework is built upon two core components: (1) a spatio-temporal significance pruning strategy that eliminates over 64\% of the deformable primitives, followed by an entropy-constrained spherical harmonics compression applied to the remainder; and (2) a deep context model that integrates intra- and inter-prediction with hyperprior into a coarse-to-fine context structure to enable efficient multiscale latent embedding compression. Our approach achieves over 120x compression and increases rendering FPS up to 20\% compared to the baseline 4DGS, and also superior to frame-wise state-of-the-art 3DGS compression methods, revealing the effectiveness of our Light4GS in terms of both intra- and inter-prediction methods without sacrificing rendering quality.