 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDockAnywhere: Data-Efficient Visuomotor Policy Learning for Mobile Manipulation via Novel Demonstration Generation
Apr 16, 2026Mobile manipulation is a fundamental capability that enables robots to interact in expansive environments such as homes and factories. Most existing approaches follow a two-stage paradigm, where the robot first navigates to a docking point and then performs fixed-base manipulation using powerful visuomotor policies. However, real-world mobile manipulation often suffers from the view generalization problem due to shifts of docking points. To address this issue, we propose a novel low-cost demonstration generation framework named DockAnywhere, which improves viewpoint generalization under docking variability by lifting a single demonstration to diverse feasible docking configurations. Specifically, DockAnywhere lifts a trajectory to any feasible docking points by decoupling docking-dependent base motions from contact-rich manipulation skills that remain invariant across viewpoints. Feasible docking proposals are sampled under feasibility constraints, and corresponding trajectories are generated via structure-preserving augmentation. Visual observations are synthesized in 3D space by representing the robot and objects as point clouds and applying point-level spatial editing to ensure the consistency of observation and action across viewpoints. Extensive experiments on ManiSkill and real-world platforms demonstrate that DockAnywhere substantially improves policy success rates and easily generalizes to novel viewpoints from unseen docking points during training, significantly enhancing the generalization capability of mobile manipulation policy in real-world deployment.
RoCo Challenge at AAAI 2026: Benchmarking Robotic Collaborative Manipulation for Assembly Towards Industrial Automation
Mar 16, 2026Embodied Artificial Intelligence (EAI) is rapidly developing, gradually subverting previous autonomous systems' paradigms from isolated perception to integrated, continuous action. This transition is highly significant for industrial robotic manipulation, promising to free human workers from repetitive, dangerous daily labor. To benchmark and advance this capability, we introduce the Robotic Collaborative Assembly Assistance (RoCo) Challenge with a dataset towards simulation and real-world assembly manipulation. Set against the backdrop of human-centered manufacturing, this challenge focuses on a high-precision planetary gearbox assembly task, a demanding yet highly representative operation in modern industry. Built upon a self-developed data collection, training, and evaluation system in Isaac Sim, and utilizing a dual-arm robot for real-world deployment, the challenge operates in two phases. The Simulation Round defines fine-grained task phases for step-wise scoring to handle the long-horizon nature of the assembly. The Real-World Round mirrors this evaluation with physical gearbox components and high-quality teleoperated datasets. The core tasks require assembling an epicyclic gearbox from scratch, including mounting three planet gears, a sun gear, and a ring gear. Attracting over 60 teams and 170+ participants from more than 10 countries, the challenge yielded highly effective solutions, most notably ARC-VLA and RoboCola. Results demonstrate that a dual-model framework for long-horizon multi-task learning is highly effective, and the strategic utilization of recovery-from-failure curriculum data is a critical insight for successful deployment. This report outlines the competition setup, evaluation approach, key findings, and future directions for industrial EAI. Our dataset, CAD files, code, and evaluation results can be found at: https://rocochallenge.github.io/RoCo2026/.
CLIP-PCQA: Exploring Subjective-Aligned Vision-Language Modeling for Point Cloud Quality Assessment
Jan 17, 2025



In recent years, No-Reference Point Cloud Quality Assessment (NR-PCQA) research has achieved significant progress. However, existing methods mostly seek a direct mapping function from visual data to the Mean Opinion Score (MOS), which is contradictory to the mechanism of practical subjective evaluation. To address this, we propose a novel language-driven PCQA method named CLIP-PCQA. Considering that human beings prefer to describe visual quality using discrete quality descriptions (e.g., "excellent" and "poor") rather than specific scores, we adopt a retrieval-based mapping strategy to simulate the process of subjective assessment. More specifically, based on the philosophy of CLIP, we calculate the cosine similarity between the visual features and multiple textual features corresponding to different quality descriptions, in which process an effective contrastive loss and learnable prompts are introduced to enhance the feature extraction. Meanwhile, given the personal limitations and bias in subjective experiments, we further covert the feature similarities into probabilities and consider the Opinion Score Distribution (OSD) rather than a single MOS as the final target. Experimental results show that our CLIP-PCQA outperforms other State-Of-The-Art (SOTA) approaches.
Asynchronous Feedback Network for Perceptual Point Cloud Quality Assessment
Jul 13, 2024



Recent years have witnessed the success of the deep learning-based technique in research of no-reference point cloud quality assessment (NR-PCQA). For a more accurate quality prediction, many previous studies have attempted to capture global and local feature in a bottom-up manner, but ignored the interaction and promotion between them. To solve this problem, we propose a novel asynchronous feedback network (AFNet). Motivated by human visual perception mechanisms, AFNet employs a dual-branch structure to deal with global and local feature, simulating the left and right hemispheres of the human brain, and constructs a feedback module between them. Specifically, the input point clouds are first fed into a transformer-based global encoder to generate the attention maps that highlight these semantically rich regions, followed by being merged into the global feature. Then, we utilize the generated attention maps to perform dynamic convolution for different semantic regions and obtain the local feature. Finally, a coarse-to-fine strategy is adopted to merge the two features into the final quality score. We conduct comprehensive experiments on three datasets and achieve superior performance over the state-of-the-art approaches on all of these datasets. The code will be available at https://github.com/zhangyujie-1998/AFNet.
Contrastive Pre-Training with Multi-View Fusion for No-Reference Point Cloud Quality Assessment
Mar 27, 2024

No-reference point cloud quality assessment (NR-PCQA) aims to automatically evaluate the perceptual quality of distorted point clouds without available reference, which have achieved tremendous improvements due to the utilization of deep neural networks. However, learning-based NR-PCQA methods suffer from the scarcity of labeled data and usually perform suboptimally in terms of generalization. To solve the problem, we propose a novel contrastive pre-training framework tailored for PCQA (CoPA), which enables the pre-trained model to learn quality-aware representations from unlabeled data. To obtain anchors in the representation space, we project point clouds with different distortions into images and randomly mix their local patches to form mixed images with multiple distortions. Utilizing the generated anchors, we constrain the pre-training process via a quality-aware contrastive loss following the philosophy that perceptual quality is closely related to both content and distortion. Furthermore, in the model fine-tuning stage, we propose a semantic-guided multi-view fusion module to effectively integrate the features of projected images from multiple perspectives. Extensive experiments show that our method outperforms the state-of-the-art PCQA methods on popular benchmarks. Further investigations demonstrate that CoPA can also benefit existing learning-based PCQA models.
PAME: Self-Supervised Masked Autoencoder for No-Reference Point Cloud Quality Assessment
Mar 15, 2024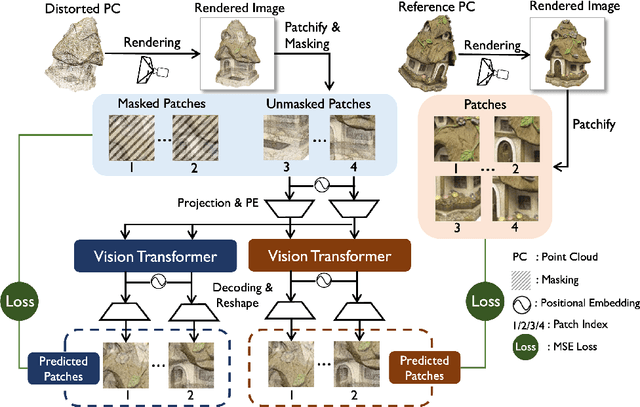
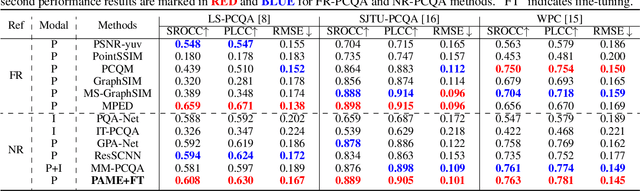
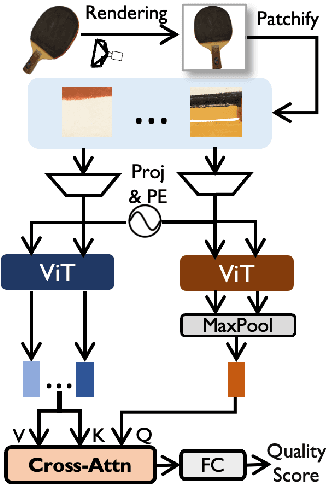
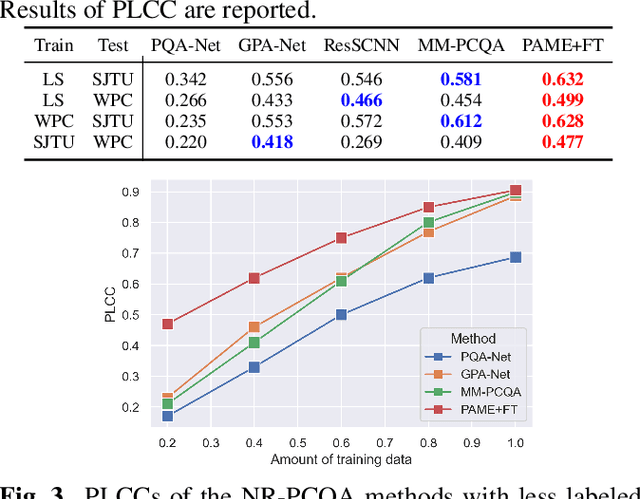
No-reference point cloud quality assessment (NR-PCQA) aims to automatically predict the perceptual quality of point clouds without reference, which has achieved remarkable performance due to the utilization of deep learning-based models. However, these data-driven models suffer from the scarcity of labeled data and perform unsatisfactorily in cross-dataset evaluations. To address this problem, we propose a self-supervised pre-training framework using masked autoencoders (PAME) to help the model learn useful representations without labels. Specifically, after projecting point clouds into images, our PAME employs dual-branch autoencoders, reconstructing masked patches from distorted images into the original patches within reference and distorted images. In this manner, the two branches can separately learn content-aware features and distortion-aware features from the projected images. Furthermore, in the model fine-tuning stage, the learned content-aware features serve as a guide to fuse the point cloud quality features extracted from different perspectives. Extensive experiments show that our method outperforms the state-of-the-art NR-PCQA methods on popular benchmarks in terms of prediction accuracy and generalizability.
GPA-Net:No-Reference Point Cloud Quality Assessment with Multi-task Graph Convolutional Network
Nov 17, 2022



With the rapid development of 3D vision, point cloud has become an increasingly popular 3D visual media content. Due to the irregular structure, point cloud has posed novel challenges to the related research, such as compression, transmission, rendering and quality assessment. In these latest researches, point cloud quality assessment (PCQA) has attracted wide attention due to its significant role in guiding practical applications, especially in many cases where the reference point cloud is unavailable. However, current no-reference metrics which based on prevalent deep neural network have apparent disadvantages. For example, to adapt to the irregular structure of point cloud, they require preprocessing such as voxelization and projection that introduce extra distortions, and the applied grid-kernel networks, such as Convolutional Neural Networks, fail to extract effective distortion-related features. Besides, they rarely consider the various distortion patterns and the philosophy that PCQA should exhibit shifting, scaling, and rotational invariance. In this paper, we propose a novel no-reference PCQA metric named the Graph convolutional PCQA network (GPA-Net). To extract effective features for PCQA, we propose a new graph convolution kernel, i.e., GPAConv, which attentively captures the perturbation of structure and texture. Then, we propose the multi-task framework consisting of one main task (quality regression) and two auxiliary tasks (distortion type and degree predictions). Finally, we propose a coordinate normalization module to stabilize the results of GPAConv under shift, scale and rotation transformations. Experimental results on two independent databases show that GPA-Net achieves the best performance compared to the state-of-the-art no-reference PCQA metrics, even better than some full-reference metrics in some cases.