 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePlug-In Classification of Drift Functions in Diffusion Processes Using Neural Networks
Feb 02, 2026We study a supervised multiclass classification problem for diffusion processes, where each class is characterized by a distinct drift function and trajectories are observed at discrete times. Extending the one-dimensional multiclass framework of Denis et al. (2024) to multidimensional diffusions, we propose a neural network-based plug-in classifier that estimates the drift functions for each class from independent sample paths and assigns labels based on a Bayes-type decision rule. Under standard regularity assumptions, we establish convergence rates for the excess misclassification risk, explicitly capturing the effects of drift estimation error and time discretization. Numerical experiments demonstrate that the proposed method achieves faster convergence and improved classification performance compared to Denis et al. (2024) in the one-dimensional setting, remains effective in higher dimensions when the underlying drift functions admit a compositional structure, and consistently outperforms direct neural network classifiers trained end-to-end on trajectories without exploiting the diffusion model structure.
Probing Scientific General Intelligence of LLMs with Scientist-Aligned Workflows
Dec 18, 2025Despite advances in scientific AI, a coherent framework for Scientific General Intelligence (SGI)-the ability to autonomously conceive, investigate, and reason across scientific domains-remains lacking. We present an operational SGI definition grounded in the Practical Inquiry Model (PIM: Deliberation, Conception, Action, Perception) and operationalize it via four scientist-aligned tasks: deep research, idea generation, dry/wet experiments, and experimental reasoning. SGI-Bench comprises over 1,000 expert-curated, cross-disciplinary samples inspired by Science's 125 Big Questions, enabling systematic evaluation of state-of-the-art LLMs. Results reveal gaps: low exact match (10--20%) in deep research despite step-level alignment; ideas lacking feasibility and detail; high code executability but low execution result accuracy in dry experiments; low sequence fidelity in wet protocols; and persistent multimodal comparative-reasoning challenges. We further introduce Test-Time Reinforcement Learning (TTRL), which optimizes retrieval-augmented novelty rewards at inference, enhancing hypothesis novelty without reference answer. Together, our PIM-grounded definition, workflow-centric benchmark, and empirical insights establish a foundation for AI systems that genuinely participate in scientific discovery.
Drift Estimation for Diffusion Processes Using Neural Networks Based on Discretely Observed Independent Paths
Nov 14, 2025This paper addresses the nonparametric estimation of the drift function over a compact domain for a time-homogeneous diffusion process, based on high-frequency discrete observations from $N$ independent trajectories. We propose a neural network-based estimator and derive a non-asymptotic convergence rate, decomposed into a training error, an approximation error, and a diffusion-related term scaling as ${\log N}/{N}$. For compositional drift functions, we establish an explicit rate. In the numerical experiments, we consider a drift function with local fluctuations generated by a double-layer compositional structure featuring local oscillations, and show that the empirical convergence rate becomes independent of the input dimension $d$. Compared to the $B$-spline method, the neural network estimator achieves better convergence rates and more effectively captures local features, particularly in higher-dimensional settings.
Consistency Change Detection Framework for Unsupervised Remote Sensing Change Detection
Nov 12, 2025Unsupervised remote sensing change detection aims to monitor and analyze changes from multi-temporal remote sensing images in the same geometric region at different times, without the need for labeled training data. Previous unsupervised methods attempt to achieve style transfer across multi-temporal remote sensing images through reconstruction by a generator network, and then capture the unreconstructable areas as the changed regions. However, it often leads to poor performance due to generator overfitting. In this paper, we propose a novel Consistency Change Detection Framework (CCDF) to address this challenge. Specifically, we introduce a Cycle Consistency (CC) module to reduce the overfitting issues in the generator-based reconstruction. Additionally, we propose a Semantic Consistency (SC) module to enable detail reconstruction. Extensive experiments demonstrate that our method outperforms other state-of-the-art approaches.
IC-Custom: Diverse Image Customization via In-Context Learning
Jul 02, 2025Image customization, a crucial technique for industrial media production, aims to generate content that is consistent with reference images. However, current approaches conventionally separate image customization into position-aware and position-free customization paradigms and lack a universal framework for diverse customization, limiting their applications across various scenarios. To overcome these limitations, we propose IC-Custom, a unified framework that seamlessly integrates position-aware and position-free image customization through in-context learning. IC-Custom concatenates reference images with target images to a polyptych, leveraging DiT's multi-modal attention mechanism for fine-grained token-level interactions. We introduce the In-context Multi-Modal Attention (ICMA) mechanism with learnable task-oriented register tokens and boundary-aware positional embeddings to enable the model to correctly handle different task types and distinguish various inputs in polyptych configurations. To bridge the data gap, we carefully curated a high-quality dataset of 12k identity-consistent samples with 8k from real-world sources and 4k from high-quality synthetic data, avoiding the overly glossy and over-saturated synthetic appearance. IC-Custom supports various industrial applications, including try-on, accessory placement, furniture arrangement, and creative IP customization. Extensive evaluations on our proposed ProductBench and the publicly available DreamBench demonstrate that IC-Custom significantly outperforms community workflows, closed-source models, and state-of-the-art open-source approaches. IC-Custom achieves approximately 73% higher human preference across identity consistency, harmonicity, and text alignment metrics, while training only 0.4% of the original model parameters. Project page: https://liyaowei-stu.github.io/project/IC_Custom
DPCD: A Quality Assessment Database for Dynamic Point Clouds
May 18, 2025
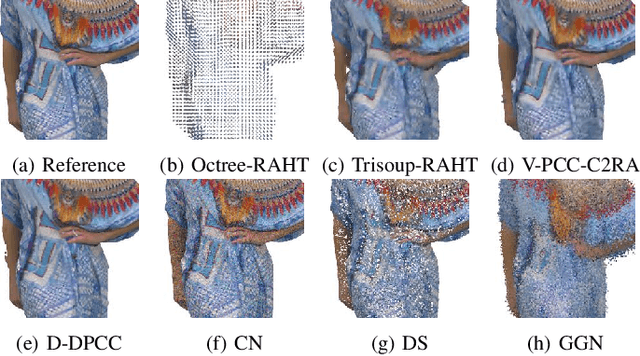
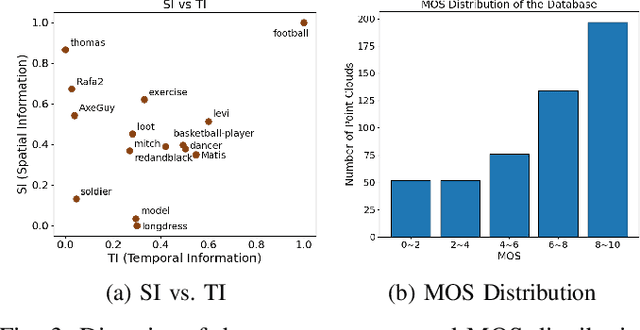
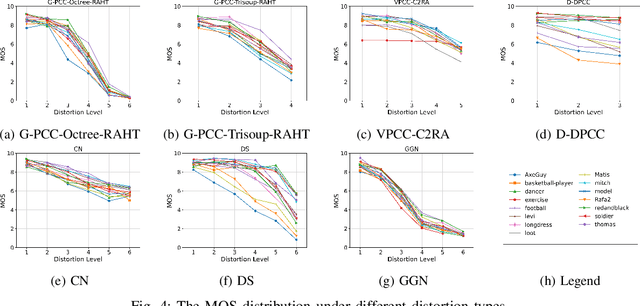
Recently, the advancements in Virtual/Augmented Reality (VR/AR) have driven the demand for Dynamic Point Clouds (DPC). Unlike static point clouds, DPCs are capable of capturing temporal changes within objects or scenes, offering a more accurate simulation of the real world. While significant progress has been made in the quality assessment research of static point cloud, little study has been done on Dynamic Point Cloud Quality Assessment (DPCQA), which hinders the development of quality-oriented applications, such as interframe compression and transmission in practical scenarios. In this paper, we introduce a large-scale DPCQA database, named DPCD, which includes 15 reference DPCs and 525 distorted DPCs from seven types of lossy compression and noise distortion. By rendering these samples to Processed Video Sequences (PVS), a comprehensive subjective experiment is conducted to obtain Mean Opinion Scores (MOS) from 21 viewers for analysis. The characteristic of contents, impact of various distortions, and accuracy of MOSs are presented to validate the heterogeneity and reliability of the proposed database. Furthermore, we evaluate the performance of several objective metrics on DPCD. The experiment results show that DPCQA is more challenge than that of static point cloud. The DPCD, which serves as a catalyst for new research endeavors on DPCQA, is publicly available at https://huggingface.co/datasets/Olivialyt/DPCD.
UP-Person: Unified Parameter-Efficient Transfer Learning for Text-based Person Retrieval
Apr 14, 2025Text-based Person Retrieval (TPR) as a multi-modal task, which aims to retrieve the target person from a pool of candidate images given a text description, has recently garnered considerable attention due to the progress of contrastive visual-language pre-trained model. Prior works leverage pre-trained CLIP to extract person visual and textual features and fully fine-tune the entire network, which have shown notable performance improvements compared to uni-modal pre-training models. However, full-tuning a large model is prone to overfitting and hinders the generalization ability. In this paper, we propose a novel Unified Parameter-Efficient Transfer Learning (PETL) method for Text-based Person Retrieval (UP-Person) to thoroughly transfer the multi-modal knowledge from CLIP. Specifically, UP-Person simultaneously integrates three lightweight PETL components including Prefix, LoRA and Adapter, where Prefix and LoRA are devised together to mine local information with task-specific information prompts, and Adapter is designed to adjust global feature representations. Additionally, two vanilla submodules are optimized to adapt to the unified architecture of TPR. For one thing, S-Prefix is proposed to boost attention of prefix and enhance the gradient propagation of prefix tokens, which improves the flexibility and performance of the vanilla prefix. For another thing, L-Adapter is designed in parallel with layer normalization to adjust the overall distribution, which can resolve conflicts caused by overlap and interaction among multiple submodules. Extensive experimental results demonstrate that our UP-Person achieves state-of-the-art results across various person retrieval datasets, including CUHK-PEDES, ICFG-PEDES and RSTPReid while merely fine-tuning 4.7\% parameters. Code is available at https://github.com/Liu-Yating/UP-Person.
AxisPose: Model-Free Matching-Free Single-Shot 6D Object Pose Estimation via Axis Generation
Mar 09, 2025



Object pose estimation, which plays a vital role in robotics, augmented reality, and autonomous driving, has been of great interest in computer vision. Existing studies either require multi-stage pose regression or rely on 2D-3D feature matching. Though these approaches have shown promising results, they rely heavily on appearance information, requiring complex input (i.e., multi-view reference input, depth, or CAD models) and intricate pipeline (i.e., feature extraction-SfM-2D to 3D matching-PnP). We propose AxisPose, a model-free, matching-free, single-shot solution for robust 6D pose estimation, which fundamentally diverges from the existing paradigm. Unlike existing methods that rely on 2D-3D or 2D-2D matching using 3D techniques, such as SfM and PnP, AxisPose directly infers a robust 6D pose from a single view by leveraging a diffusion model to learn the latent axis distribution of objects without reference views. Specifically, AxisPose constructs an Axis Generation Module (AGM) to capture the latent geometric distribution of object axes through a diffusion model. The diffusion process is guided by injecting the gradient of geometric consistency loss into the noise estimation to maintain the geometric consistency of the generated tri-axis. With the generated tri-axis projection, AxisPose further adopts a Triaxial Back-projection Module (TBM) to recover the 6D pose from the object tri-axis. The proposed AxisPose achieves robust performance at the cross-instance level (i.e., one model for N instances) using only a single view as input without reference images, with great potential for generalization to unseen-object level.
DM-Adapter: Domain-Aware Mixture-of-Adapters for Text-Based Person Retrieval
Mar 06, 2025Text-based person retrieval (TPR) has gained significant attention as a fine-grained and challenging task that closely aligns with practical applications. Tailoring CLIP to person domain is now a emerging research topic due to the abundant knowledge of vision-language pretraining, but challenges still remain during fine-tuning: (i) Previous full-model fine-tuning in TPR is computationally expensive and prone to overfitting.(ii) Existing parameter-efficient transfer learning (PETL) for TPR lacks of fine-grained feature extraction. To address these issues, we propose Domain-Aware Mixture-of-Adapters (DM-Adapter), which unifies Mixture-of-Experts (MOE) and PETL to enhance fine-grained feature representations while maintaining efficiency. Specifically, Sparse Mixture-of-Adapters is designed in parallel to MLP layers in both vision and language branches, where different experts specialize in distinct aspects of person knowledge to handle features more finely. To promote the router to exploit domain information effectively and alleviate the routing imbalance, Domain-Aware Router is then developed by building a novel gating function and injecting learnable domain-aware prompts. Extensive experiments show that our DM-Adapter achieves state-of-the-art performance, outperforming previous methods by a significant margin.
CLIP-PCQA: Exploring Subjective-Aligned Vision-Language Modeling for Point Cloud Quality Assessment
Jan 17, 2025



In recent years, No-Reference Point Cloud Quality Assessment (NR-PCQA) research has achieved significant progress. However, existing methods mostly seek a direct mapping function from visual data to the Mean Opinion Score (MOS), which is contradictory to the mechanism of practical subjective evaluation. To address this, we propose a novel language-driven PCQA method named CLIP-PCQA. Considering that human beings prefer to describe visual quality using discrete quality descriptions (e.g., "excellent" and "poor") rather than specific scores, we adopt a retrieval-based mapping strategy to simulate the process of subjective assessment. More specifically, based on the philosophy of CLIP, we calculate the cosine similarity between the visual features and multiple textual features corresponding to different quality descriptions, in which process an effective contrastive loss and learnable prompts are introduced to enhance the feature extraction. Meanwhile, given the personal limitations and bias in subjective experiments, we further covert the feature similarities into probabilities and consider the Opinion Score Distribution (OSD) rather than a single MOS as the final target. Experimental results show that our CLIP-PCQA outperforms other State-Of-The-Art (SOTA) approaches.