 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDual-Path Learning based on Frequency Structural Decoupling and Regional-Aware Fusion for Low-Light Image Super-Resolution
Mar 28, 2026Low-light image super-resolution (LLISR) is essential for restoring fine visual details and perceptual quality under insufficient illumination conditions with ubiquitous low-resolution devices. Although pioneer methods achieve high performance on single tasks, they solve both tasks in a serial manner, which inevitably leads to artifact amplification, texture suppression, and structural degradation. To address this, we propose Decoupling then Perceive (DTP), a novel frequency-aware framework that explicitly separates luminance and texture into semantically independent components, enabling specialized modeling and coherent reconstruction. Specifically, to adaptively separate the input into low-frequency luminance and high-frequency texture subspaces, we propose a Frequency-aware Structural Decoupling (FSD) mechanism, which lays a solid foundation for targeted representation learning and reconstruction. Based on the decoupled representation, a Semantics-specific Dual-path Representation (SDR) learning strategy that performs targeted enhancement and reconstruction for each frequency component is further designed, facilitating robust luminance adjustment and fine-grained texture recovery. To promote structural consistency and perceptual alignment in the reconstructed output, building upon this dual-path modeling, we further introduce a Cross-frequency Semantic Recomposition (CSR) module that selectively integrates the decoupled representations. Extensive experiments on the most widely used LLISR benchmarks demonstrate the superiority of our DTP framework, improving $+$1.6\% PSNR, $+$9.6\% SSIM, and $-$48\% LPIPS compared to the most state-of-the-art (SOTA) algorithm. Codes are released at https://github.com/JXVision/DTP.
UniGeo: A Unified 3D Indoor Object Detection Framework Integrating Geometry-Aware Learning and Dynamic Channel Gating
Jan 30, 2026The growing adoption of robotics and augmented reality in real-world applications has driven considerable research interest in 3D object detection based on point clouds. While previous methods address unified training across multiple datasets, they fail to model geometric relationships in sparse point cloud scenes and ignore the feature distribution in significant areas, which ultimately restricts their performance. To deal with this issue, a unified 3D indoor detection framework, called UniGeo, is proposed. To model geometric relations in scenes, we first propose a geometry-aware learning module that establishes a learnable mapping from spatial relationships to feature weights, which enabes explicit geometric feature enhancement. Then, to further enhance point cloud feature representation, we propose a dynamic channel gating mechanism that leverages learnable channel-wise weighting. This mechanism adaptively optimizes features generated by the sparse 3D U-Net network, significantly enhancing key geometric information. Extensive experiments on six different indoor scene datasets clearly validate the superior performance of our method.
Beyond Shadows: A Large-Scale Benchmark and Multi-Stage Framework for High-Fidelity Facial Shadow Removal
Jan 27, 2026Facial shadows often degrade image quality and the performance of vision algorithms. Existing methods struggle to remove shadows while preserving texture, especially under complex lighting conditions, and they lack real-world paired datasets for training. We present the Augmented Shadow Face in the Wild (ASFW) dataset, the first large-scale real-world dataset for facial shadow removal, containing 1,081 paired shadow and shadow-free images created via a professional Photoshop workflow. ASFW offers photorealistic shadow variations and accurate ground truths, bridging the gap between synthetic and real domains. Deep models trained on ASFW demonstrate improved shadow removal in real-world conditions. We also introduce the Face Shadow Eraser (FSE) method to showcase the effectiveness of the dataset. Experiments demonstrate that ASFW enhances the performance of facial shadow removal models, setting new standards for this task.
A New Paradigm for Trusted Respiratory Monitoring Via Consumer Electronics-grade Radar Signals
Jan 22, 2026Respiratory monitoring is an extremely important task in modern medical services. Due to its significant advantages, e.g., non-contact, radar-based respiratory monitoring has attracted widespread attention from both academia and industry. Unfortunately, though it can achieve high monitoring accuracy, consumer electronics-grade radar data inevitably contains User-sensitive Identity Information (USI), which may be maliciously used and further lead to privacy leakage. To track these challenges, by variational mode decomposition (VMD) and adversarial loss-based encryption, we propose a novel Trusted Respiratory Monitoring paradigm, Tru-RM, to perform automated respiratory monitoring through radio signals while effectively anonymizing USI. The key enablers of Tru-RM are Attribute Feature Decoupling (AFD), Flexible Perturbation Encryptor (FPE), and robust Perturbation Tolerable Network (PTN) used for attribute decomposition, identity encryption, and perturbed respiratory monitoring, respectively. Specifically, AFD is designed to decompose the raw radar signals into the universal respiratory component, the personal difference component, and other unrelated components. Then, by using large noise to drown out the other unrelated components, and the phase noise algorithm with a learning intensity parameter to eliminate USI in the personal difference component, FPE is designed to achieve complete user identity information encryption without affecting respiratory features. Finally, by designing the transferred generalized domain-independent network, PTN is employed to accurately detect respiration when waveforms change significantly. Extensive experiments based on various detection distances, respiratory patterns, and durations demonstrate the superior performance of Tru-RM on strong anonymity of USI, and high detection accuracy of perturbed respiratory waveforms.
Breaking Coordinate Overfitting: Geometry-Aware WiFi Sensing for Cross-Layout 3D Pose Estimation
Jan 18, 2026WiFi-based 3D human pose estimation offers a low-cost and privacy-preserving alternative to vision-based systems for smart interaction. However, existing approaches rely on visual 3D poses as supervision and directly regress CSI to a camera-based coordinate system. We find that this practice leads to coordinate overfitting: models memorize deployment-specific WiFi transceiver layouts rather than only learning activity-relevant representations, resulting in severe generalization failures. To address this challenge, we present PerceptAlign, the first geometry-conditioned framework for WiFi-based cross-layout pose estimation. PerceptAlign introduces a lightweight coordinate unification procedure that aligns WiFi and vision measurements in a shared 3D space using only two checkerboards and a few photos. Within this unified space, it encodes calibrated transceiver positions into high-dimensional embeddings and fuses them with CSI features, making the model explicitly aware of device geometry as a conditional variable. This design forces the network to disentangle human motion from deployment layouts, enabling robust and, for the first time, layout-invariant WiFi pose estimation. To support systematic evaluation, we construct the largest cross-domain 3D WiFi pose estimation dataset to date, comprising 21 subjects, 5 scenes, 18 actions, and 7 device layouts. Experiments show that PerceptAlign reduces in-domain error by 12.3% and cross-domain error by more than 60% compared to state-of-the-art baselines. These results establish geometry-conditioned learning as a viable path toward scalable and practical WiFi sensing.
Beyond Physical Labels: Redefining Domains for Robust WiFi-based Gesture Recognition
Jan 08, 2026In this paper, we propose GesFi, a novel WiFi-based gesture recognition system that introduces WiFi latent domain mining to redefine domains directly from the data itself. GesFi first processes raw sensing data collected from WiFi receivers using CSI-ratio denoising, Short-Time Fast Fourier Transform, and visualization techniques to generate standardized input representations. It then employs class-wise adversarial learning to suppress gesture semantic and leverages unsupervised clustering to automatically uncover latent domain factors responsible for distributional shifts. These latent domains are then aligned through adversarial learning to support robust cross-domain generalization. Finally, the system is applied to the target environment for robust gesture inference. We deployed GesFi under both single-pair and multi-pair settings using commodity WiFi transceivers, and evaluated it across multiple public datasets and real-world environments. Compared to state-of-the-art baselines, GesFi achieves up to 78% and 50% performance improvements over existing adversarial methods, and consistently outperforms prior generalization approaches across most cross-domain tasks.
ReMA: A Training-Free Plug-and-Play Mixing Augmentation for Video Behavior Recognition
Jan 01, 2026Video behavior recognition demands stable and discriminative representations under complex spatiotemporal variations. However, prevailing data augmentation strategies for videos remain largely perturbation-driven, often introducing uncontrolled variations that amplify non-discriminative factors, which finally weaken intra-class distributional structure and representation drift with inconsistent gains across temporal scales. To address these problems, we propose Representation-aware Mixing Augmentation (ReMA), a plug-and-play augmentation strategy that formulates mixing as a controlled replacement process to expand representations while preserving class-conditional stability. ReMA integrates two complementary mechanisms. Firstly, the Representation Alignment Mechanism (RAM) performs structured intra-class mixing under distributional alignment constraints, suppressing irrelevant intra-class drift while enhancing statistical reliability. Then, the Dynamic Selection Mechanism (DSM) generates motion-aware spatiotemporal masks to localize perturbations, guiding them away from discrimination-sensitive regions and promoting temporal coherence. By jointly controlling how and where mixing is applied, ReMA improves representation robustness without additional supervision or trainable parameters. Extensive experiments on diverse video behavior benchmarks demonstrate that ReMA consistently enhances generalization and robustness across different spatiotemporal granularities.
Disentangling Emotional Bases and Transient Fluctuations: A Low-Rank Sparse Decomposition Approach for Video Affective Analysis
Nov 14, 2025Video-based Affective Computing (VAC), vital for emotion analysis and human-computer interaction, suffers from model instability and representational degradation due to complex emotional dynamics. Since the meaning of different emotional fluctuations may differ under different emotional contexts, the core limitation is the lack of a hierarchical structural mechanism to disentangle distinct affective components, i.e., emotional bases (the long-term emotional tone), and transient fluctuations (the short-term emotional fluctuations). To address this, we propose the Low-Rank Sparse Emotion Understanding Framework (LSEF), a unified model grounded in the Low-Rank Sparse Principle, which theoretically reframes affective dynamics as a hierarchical low-rank sparse compositional process. LSEF employs three plug-and-play modules, i.e., the Stability Encoding Module (SEM) captures low-rank emotional bases; the Dynamic Decoupling Module (DDM) isolates sparse transient signals; and the Consistency Integration Module (CIM) reconstructs multi-scale stability and reactivity coherence. This framework is optimized by a Rank Aware Optimization (RAO) strategy that adaptively balances gradient smoothness and sensitivity. Extensive experiments across multiple datasets confirm that LSEF significantly enhances robustness and dynamic discrimination, which further validates the effectiveness and generality of hierarchical low-rank sparse modeling for understanding affective dynamics.
Optimizing Federated Graph Learning with Inherent Structural Knowledge and Dual-Densely Connected GNNs
Aug 21, 2024Federated Graph Learning (FGL) is an emerging technology that enables clients to collaboratively train powerful Graph Neural Networks (GNNs) in a distributed manner without exposing their private data. Nevertheless, FGL still faces the challenge of the severe non-Independent and Identically Distributed (non-IID) nature of graphs, which possess diverse node and edge structures, especially across varied domains. Thus, exploring the knowledge inherent in these structures becomes significantly crucial. Existing methods, however, either overlook the inherent structural knowledge in graph data or capture it at the cost of significantly increased resource demands (e.g., FLOPs and communication bandwidth), which can be detrimental to distributed paradigms. Inspired by this, we propose FedDense, a novel FGL framework that optimizes the utilization efficiency of inherent structural knowledge. To better acquire knowledge of diverse and underexploited structures, FedDense first explicitly encodes the structural knowledge inherent within graph data itself alongside node features. Besides, FedDense introduces a Dual-Densely Connected (DDC) GNN architecture that exploits the multi-scale (i.e., one-hop to multi-hop) feature and structure insights embedded in the aggregated feature maps at each layer. In addition to the exploitation of inherent structures, we consider resource limitations in FGL, devising exceedingly narrow layers atop the DDC architecture and adopting a selective parameter sharing strategy to reduce resource costs substantially. We conduct extensive experiments using 15 datasets across 4 different domains, demonstrating that FedDense consistently surpasses baselines by a large margin in training performance, while demanding minimal resources.
FacialPulse: An Efficient RNN-based Depression Detection via Temporal Facial Landmarks
Aug 07, 2024
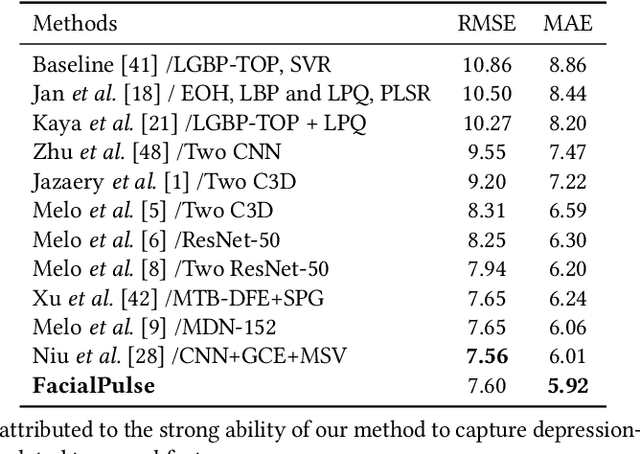
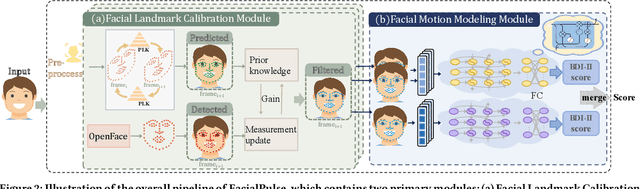

Depression is a prevalent mental health disorder that significantly impacts individuals' lives and well-being. Early detection and intervention are crucial for effective treatment and management of depression. Recently, there are many end-to-end deep learning methods leveraging the facial expression features for automatic depression detection. However, most current methods overlook the temporal dynamics of facial expressions. Although very recent 3DCNN methods remedy this gap, they introduce more computational cost due to the selection of CNN-based backbones and redundant facial features. To address the above limitations, by considering the timing correlation of facial expressions, we propose a novel framework called FacialPulse, which recognizes depression with high accuracy and speed. By harnessing the bidirectional nature and proficiently addressing long-term dependencies, the Facial Motion Modeling Module (FMMM) is designed in FacialPulse to fully capture temporal features. Since the proposed FMMM has parallel processing capabilities and has the gate mechanism to mitigate gradient vanishing, this module can also significantly boost the training speed. Besides, to effectively use facial landmarks to replace original images to decrease information redundancy, a Facial Landmark Calibration Module (FLCM) is designed to eliminate facial landmark errors to further improve recognition accuracy. Extensive experiments on the AVEC2014 dataset and MMDA dataset (a depression dataset) demonstrate the superiority of FacialPulse on recognition accuracy and speed, with the average MAE (Mean Absolute Error) decreased by 21% compared to baselines, and the recognition speed increased by 100% compared to state-of-the-art methods. Codes are released at https://github.com/volatileee/FacialPulse.