 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDRFusion: Drift-Resilient Temporally Consistent Infrared-Visible Video Fusion
May 25, 2026Infrared and visible video fusion is essential for achieving comprehensive perception in dynamic scenes. However, maintaining temporal consistency remains a formidable challenge. Conventional methods relying on optical flow often suffer from geometric rigidity and ghosting artifacts. Moreover, standard diffusion-based fusion models typically operate in a frame-by-frame manner; when extended to autoregressive settings, they lack intrinsic temporal constraints and are prone to severe error accumulation and drifting, where minor artifacts amplify over time. To address these limitations, we propose a drift-resilient video fusion method that reformulates the task as history-conditioned motion generation. We introduce Stabilized History Guidance and Soft Temporal Anchoring to reframe temporal consistency as spectral filtering, implicitly aggregating motion dynamics without rigid alignment. Furthermore, our Decoupled Structure-Motion Adaptation strategy bridges pre-trained priors and structural constraints via two-stage training and latent refinement. Extensive experiments demonstrate that our method achieves state-of-the-art performance in both fusion quality and temporal stability.
Uncertainty-aware Spatial-Frequency Registration and Fusion for Infrared and Visible Images
May 13, 2026Infrared and Visible Image Fusion (IVIF) has shown promise in visual tasks under challenging environments, but fusion under unregistered conditions faces inherent misalignments. Current studies to solve them either predict the deformation parameters coarse-to-fine (i.e., coarse registration and fine registration) or estimate the deformation fields in multi-scales for registration. Though straightforward, they overlook the cumulative errors in registration, which contaminate the fusion stage and severely deteriorate the resulting images. We introduce the Spatial-Frequency Registration and Fusion (SFRF) framework, which incorporates uncertainty estimation and infrared thermal radiation distribution consistency into a unified pipeline to handle the error accumulation for robust registration and fusion across both spatial and frequency domains. Specifically, SFRF constructs a Multi-scale Iterative Registration (MIR) framework that iteratively refines the deformation field across scales, leveraging uncertainty estimation at each stage to mitigate error accumulation and enhance alignment accuracy dynamically. To ensure the accurate alignment of infrared thermal distributions during registration, thermal radiation distribution consistency is employed as a frequency-domain supervisory signal, promoting global consistency in the frequency domain. Based on the spatial-frequency alignment, SFRF further adopts a Dual-branch Spatial-Frequency Fusion (DSFF) module, which incorporates spatial geometric features and frequency distribution information to reconstruct visually appealing images. SFRF achieves impressive performance across diverse datasets.
UniFusion: A Unified Image Fusion Framework with Robust Representation and Source-Aware Preservation
Mar 15, 2026Image fusion aims to integrate complementary information from multiple source images to produce a more informative and visually consistent representation, benefiting both human perception and downstream vision tasks. Despite recent progress, most existing fusion methods are designed for specific tasks (i.e., multi-modal, multi-exposure, or multi-focus fusion) and struggle to effectively preserve source information during the fusion process. This limitation primarily arises from task-specific architectures and the degradation of source information caused by deep-layer propagation. To overcome these issues, we propose UniFusion, a unified image fusion framework designed to achieve cross-task generalization. First, leveraging DINOv3 for modality-consistent feature extraction, UniFusion establishes a shared semantic space for diverse inputs. Second, to preserve the understanding of each source image, we introduce a reconstruction-alignment loss to maintain consistency between fused outputs and inputs. Finally, we employ a bilevel optimization strategy to decouple and jointly optimize reconstruction and fusion objectives, effectively balancing their coupling relationship and ensuring smooth convergence. Extensive experiments across multiple fusion tasks demonstrate UniFusion's superior visual quality, generalization ability, and adaptability to real-world scenarios. Code is available at https://github.com/dusongcheng/UniFusion.
Toward Real-world Infrared Image Super-Resolution: A Unified Autoregressive Framework and Benchmark Dataset
Mar 05, 2026Infrared image super-resolution (IISR) under real-world conditions is a practically significant yet rarely addressed task. Pioneering works are often trained and evaluated on simulated datasets or neglect the intrinsic differences between infrared and visible imaging. In practice, however, real infrared images are affected by coupled optical and sensing degradations that jointly deteriorate both structural sharpness and thermal fidelity. To address these challenges, we propose Real-IISR, a unified autoregressive framework for real-world IISR that progressively reconstructs fine-grained thermal structures and clear backgrounds in a scale-by-scale manner via thermal-structural guided visual autoregression. Specifically, a Thermal-Structural Guidance module encodes thermal priors to mitigate the mismatch between thermal radiation and structural edges. Since non-uniform degradations typically induce quantization bias, Real-IISR adopts a Condition-Adaptive Codebook that dynamically modulates discrete representations based on degradation-aware thermal priors. Also, a Thermal Order Consistency Loss enforces a monotonic relation between temperature and pixel intensity, ensuring relative brightness order rather than absolute values to maintain physical consistency under spatial misalignment and thermal drift. We build FLIR-IISR, a real-world IISR dataset with paired LR-HR infrared images acquired via automated focus variation and motion-induced blur. Extensive experiments demonstrate the promising performance of Real-IISR, providing a unified foundation for real-world IISR and benchmarking. The dataset and code are available at: https://github.com/JZD151/Real-IISR.
Bridging Human Evaluation to Infrared and Visible Image Fusion
Mar 04, 2026Infrared and visible image fusion (IVIF) integrates complementary modalities to enhance scene perception. Current methods predominantly focus on optimizing handcrafted losses and objective metrics, often resulting in fusion outcomes that do not align with human visual preferences. This challenge is further exacerbated by the ill-posed nature of IVIF, which severely limits its effectiveness in human perceptual environments such as security surveillance and driver assistance systems. To address these limitations, we propose a feedback reinforcement framework that bridges human evaluation to infrared and visible image fusion. To address the lack of human-centric evaluation metrics and data, we introduce the first large-scale human feedback dataset for IVIF, containing multidimensional subjective scores and artifact annotations, and enriched by a fine-tuned large language model with expert review. Based on this dataset, we design a domain-specific reward function and train a reward model to quantify perceptual quality. Guided by this reward, we fine-tune the fusion network through Group Relative Policy Optimization, achieving state-of-the-art performance that better aligns fused images with human aesthetics. Code is available at https://github.com/ALKA-Wind/EVAFusion.
Semi-Supervised Diseased Detection from Speech Dialogues with Multi-Level Data Modeling
Jan 08, 2026Detecting medical conditions from speech acoustics is fundamentally a weakly-supervised learning problem: a single, often noisy, session-level label must be linked to nuanced patterns within a long, complex audio recording. This task is further hampered by severe data scarcity and the subjective nature of clinical annotations. While semi-supervised learning (SSL) offers a viable path to leverage unlabeled data, existing audio methods often fail to address the core challenge that pathological traits are not uniformly expressed in a patient's speech. We propose a novel, audio-only SSL framework that explicitly models this hierarchy by jointly learning from frame-level, segment-level, and session-level representations within unsegmented clinical dialogues. Our end-to-end approach dynamically aggregates these multi-granularity features and generates high-quality pseudo-labels to efficiently utilize unlabeled data. Extensive experiments show the framework is model-agnostic, robust across languages and conditions, and highly data-efficient-achieving, for instance, 90\% of fully-supervised performance using only 11 labeled samples. This work provides a principled approach to learning from weak, far-end supervision in medical speech analysis.
HATIR: Heat-Aware Diffusion for Turbulent Infrared Video Super-Resolution
Jan 08, 2026Infrared video has been of great interest in visual tasks under challenging environments, but often suffers from severe atmospheric turbulence and compression degradation. Existing video super-resolution (VSR) methods either neglect the inherent modality gap between infrared and visible images or fail to restore turbulence-induced distortions. Directly cascading turbulence mitigation (TM) algorithms with VSR methods leads to error propagation and accumulation due to the decoupled modeling of degradation between turbulence and resolution. We introduce HATIR, a Heat-Aware Diffusion for Turbulent InfraRed Video Super-Resolution, which injects heat-aware deformation priors into the diffusion sampling path to jointly model the inverse process of turbulent degradation and structural detail loss. Specifically, HATIR constructs a Phasor-Guided Flow Estimator, rooted in the physical principle that thermally active regions exhibit consistent phasor responses over time, enabling reliable turbulence-aware flow to guide the reverse diffusion process. To ensure the fidelity of structural recovery under nonuniform distortions, a Turbulence-Aware Decoder is proposed to selectively suppress unstable temporal cues and enhance edge-aware feature aggregation via turbulence gating and structure-aware attention. We built FLIR-IVSR, the first dataset for turbulent infrared VSR, comprising paired LR-HR sequences from a FLIR T1050sc camera (1024 X 768) spanning 640 diverse scenes with varying camera and object motion conditions. This encourages future research in infrared VSR. Project page: https://github.com/JZ0606/HATIR
Step-Audio 2 Technical Report
Jul 24, 2025



This paper presents Step-Audio 2, an end-to-end multi-modal large language model designed for industry-strength audio understanding and speech conversation. By integrating a latent audio encoder and reasoning-centric reinforcement learning (RL), Step-Audio 2 achieves promising performance in automatic speech recognition (ASR) and audio understanding. To facilitate genuine end-to-end speech conversation, Step-Audio 2 incorporates the generation of discrete audio tokens into language modeling, significantly enhancing its responsiveness to paralinguistic information such as speaking styles and emotions. To effectively leverage the rich textual and acoustic knowledge in real-world data, Step-Audio 2 integrates retrieval-augmented generation (RAG) and is able to call external tools such as web search to mitigate hallucination and audio search to switch timbres. Trained on millions of hours of speech and audio data, Step-Audio 2 delivers intelligence and expressiveness across diverse conversational scenarios. Evaluation results demonstrate that Step-Audio 2 achieves state-of-the-art performance on various audio understanding and conversational benchmarks compared to other open-source and commercial solutions. Please visit https://github.com/stepfun-ai/Step-Audio2 for more information.
KAN-SAM: Kolmogorov-Arnold Network Guided Segment Anything Model for RGB-T Salient Object Detection
Apr 08, 2025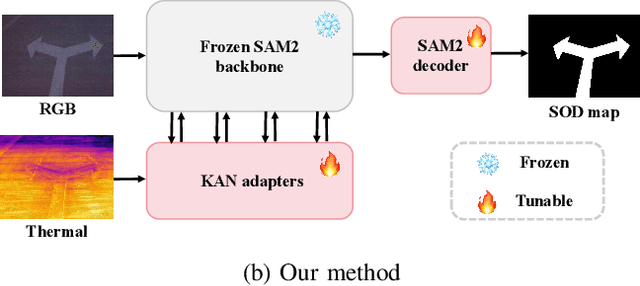
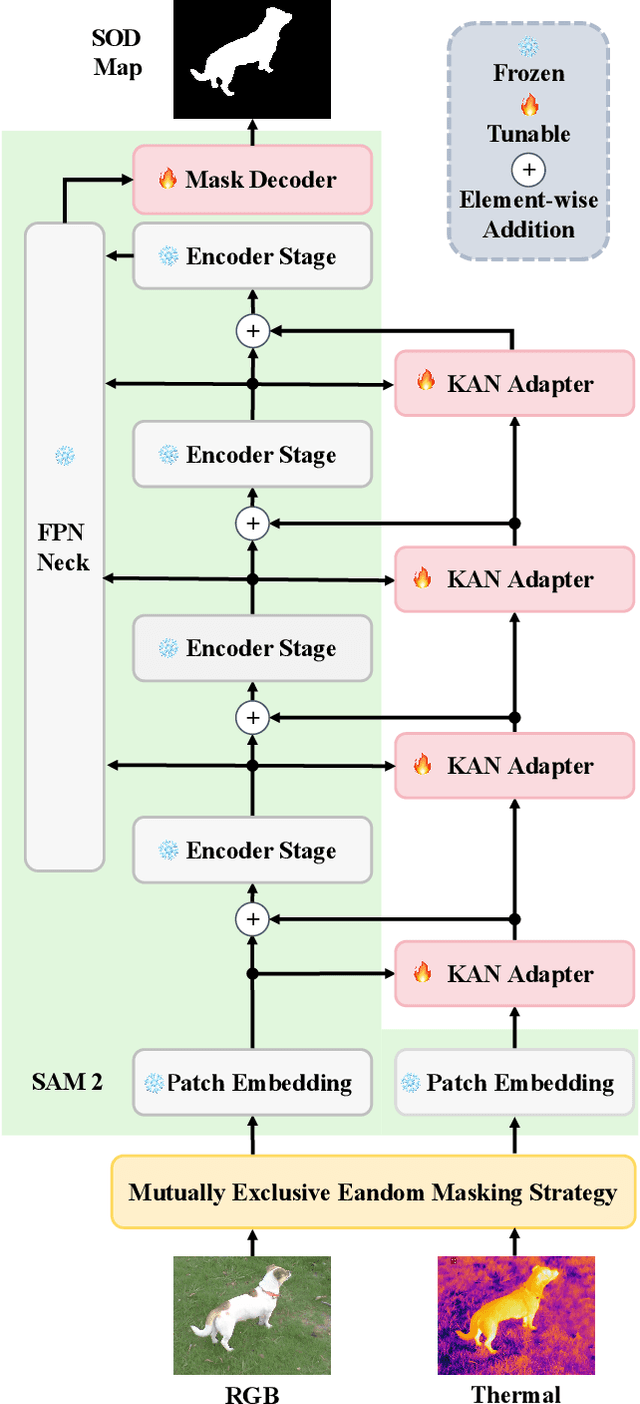
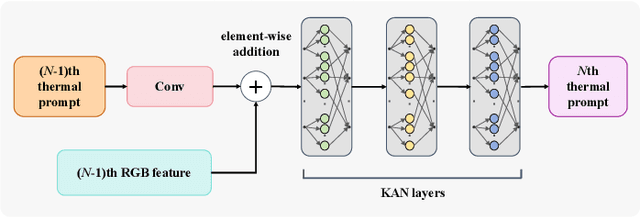
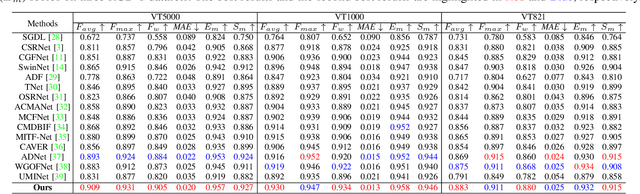
Existing RGB-thermal salient object detection (RGB-T SOD) methods aim to identify visually significant objects by leveraging both RGB and thermal modalities to enable robust performance in complex scenarios, but they often suffer from limited generalization due to the constrained diversity of available datasets and the inefficiencies in constructing multi-modal representations. In this paper, we propose a novel prompt learning-based RGB-T SOD method, named KAN-SAM, which reveals the potential of visual foundational models for RGB-T SOD tasks. Specifically, we extend Segment Anything Model 2 (SAM2) for RGB-T SOD by introducing thermal features as guiding prompts through efficient and accurate Kolmogorov-Arnold Network (KAN) adapters, which effectively enhance RGB representations and improve robustness. Furthermore, we introduce a mutually exclusive random masking strategy to reduce reliance on RGB data and improve generalization. Experimental results on benchmarks demonstrate superior performance over the state-of-the-art methods.
AxisPose: Model-Free Matching-Free Single-Shot 6D Object Pose Estimation via Axis Generation
Mar 09, 2025



Object pose estimation, which plays a vital role in robotics, augmented reality, and autonomous driving, has been of great interest in computer vision. Existing studies either require multi-stage pose regression or rely on 2D-3D feature matching. Though these approaches have shown promising results, they rely heavily on appearance information, requiring complex input (i.e., multi-view reference input, depth, or CAD models) and intricate pipeline (i.e., feature extraction-SfM-2D to 3D matching-PnP). We propose AxisPose, a model-free, matching-free, single-shot solution for robust 6D pose estimation, which fundamentally diverges from the existing paradigm. Unlike existing methods that rely on 2D-3D or 2D-2D matching using 3D techniques, such as SfM and PnP, AxisPose directly infers a robust 6D pose from a single view by leveraging a diffusion model to learn the latent axis distribution of objects without reference views. Specifically, AxisPose constructs an Axis Generation Module (AGM) to capture the latent geometric distribution of object axes through a diffusion model. The diffusion process is guided by injecting the gradient of geometric consistency loss into the noise estimation to maintain the geometric consistency of the generated tri-axis. With the generated tri-axis projection, AxisPose further adopts a Triaxial Back-projection Module (TBM) to recover the 6D pose from the object tri-axis. The proposed AxisPose achieves robust performance at the cross-instance level (i.e., one model for N instances) using only a single view as input without reference images, with great potential for generalization to unseen-object level.