 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerating Storytelling Images with Rich Chains-of-Reasoning
Dec 08, 2025An image can convey a compelling story by presenting rich, logically connected visual clues. These connections form Chains-of-Reasoning (CoRs) within the image, enabling viewers to infer events, causal relationships, and other information, thereby understanding the underlying story. In this paper, we focus on these semantically rich images and define them as Storytelling Images. Such images have diverse applications beyond illustration creation and cognitive screening, leveraging their ability to convey multi-layered information visually and inspire active interpretation. However, due to their complex semantic nature, Storytelling Images are inherently challenging to create, and thus remain relatively scarce. To address this challenge, we introduce the Storytelling Image Generation task, which explores how generative AI models can be leveraged to create such images. Specifically, we propose a two-stage pipeline, StorytellingPainter, which combines the creative reasoning abilities of Large Language Models (LLMs) with the visual synthesis capabilities of Text-to-Image (T2I) models to generate Storytelling Images. Alongside this pipeline, we develop a dedicated evaluation framework comprising three main evaluators: a Semantic Complexity Evaluator, a KNN-based Diversity Evaluator and a Story-Image Alignment Evaluator. Given the critical role of story generation in the Storytelling Image Generation task and the performance disparity between open-source and proprietary LLMs, we further explore tailored training strategies to reduce this gap, resulting in a series of lightweight yet effective models named Mini-Storytellers. Experimental results demonstrate the feasibility and effectiveness of our approaches. The code is available at https://github.com/xiujiesong/StorytellingImageGeneration.
MedEthicEval: Evaluating Large Language Models Based on Chinese Medical Ethics
Mar 04, 2025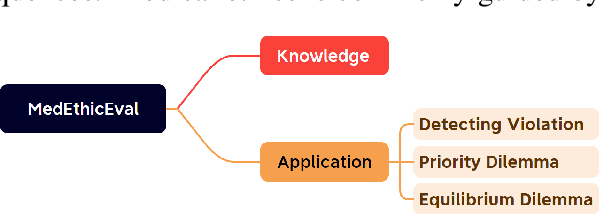

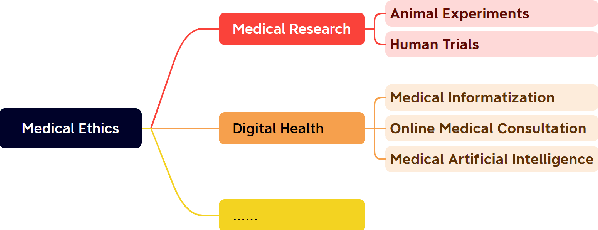

Large language models (LLMs) demonstrate significant potential in advancing medical applications, yet their capabilities in addressing medical ethics challenges remain underexplored. This paper introduces MedEthicEval, a novel benchmark designed to systematically evaluate LLMs in the domain of medical ethics. Our framework encompasses two key components: knowledge, assessing the models' grasp of medical ethics principles, and application, focusing on their ability to apply these principles across diverse scenarios. To support this benchmark, we consulted with medical ethics researchers and developed three datasets addressing distinct ethical challenges: blatant violations of medical ethics, priority dilemmas with clear inclinations, and equilibrium dilemmas without obvious resolutions. MedEthicEval serves as a critical tool for understanding LLMs' ethical reasoning in healthcare, paving the way for their responsible and effective use in medical contexts.
Is Your Image a Good Storyteller?
Dec 29, 2024Quantifying image complexity at the entity level is straightforward, but the assessment of semantic complexity has been largely overlooked. In fact, there are differences in semantic complexity across images. Images with richer semantics can tell vivid and engaging stories and offer a wide range of application scenarios. For example, the Cookie Theft picture is such a kind of image and is widely used to assess human language and cognitive abilities due to its higher semantic complexity. Additionally, semantically rich images can benefit the development of vision models, as images with limited semantics are becoming less challenging for them. However, such images are scarce, highlighting the need for a greater number of them. For instance, there is a need for more images like Cookie Theft to cater to people from different cultural backgrounds and eras. Assessing semantic complexity requires human experts and empirical evidence. Automatic evaluation of how semantically rich an image will be the first step of mining or generating more images with rich semantics, and benefit human cognitive assessment, Artificial Intelligence, and various other applications. In response, we propose the Image Semantic Assessment (ISA) task to address this problem. We introduce the first ISA dataset and a novel method that leverages language to solve this vision problem. Experiments on our dataset demonstrate the effectiveness of our approach. Our data and code are available at: https://github.com/xiujiesong/ISA.
Mixed Chain-of-Psychotherapies for Emotional Support Chatbot
Sep 29, 2024



In the realm of mental health support chatbots, it is vital to show empathy and encourage self-exploration to provide tailored solutions. However, current approaches tend to provide general insights or solutions without fully understanding the help-seeker's situation. Therefore, we propose PsyMix, a chatbot that integrates the analyses of the seeker's state from the perspective of a psychotherapy approach (Chain-of-Psychotherapies, CoP) before generating the response, and learns to incorporate the strength of various psychotherapies by fine-tuning on a mixture of CoPs. Through comprehensive evaluation, we found that PsyMix can outperform the ChatGPT baseline, and demonstrate a comparable level of empathy in its responses to that of human counselors.
A Cognitive Evaluation Benchmark of Image Reasoning and Description for Large Vision Language Models
Feb 29, 2024



Large Vision Language Models (LVLMs), despite their recent success, are hardly comprehensively tested for their cognitive abilities. Inspired by the prevalent use of the "Cookie Theft" task in human cognition test, we propose a novel evaluation benchmark to evaluate high-level cognitive ability of LVLMs using images with rich semantics. It defines eight reasoning capabilities and consists of an image description task and a visual question answering task. Our evaluation on well-known LVLMs shows that there is still a large gap in cognitive ability between LVLMs and humans.
Phonetic and Lexical Discovery of a Canine Language using HuBERT
Feb 25, 2024



This paper delves into the pioneering exploration of potential communication patterns within dog vocalizations and transcends traditional linguistic analysis barriers, which heavily relies on human priori knowledge on limited datasets to find sound units in dog vocalization. We present a self-supervised approach with HuBERT, enabling the accurate classification of phoneme labels and the identification of vocal patterns that suggest a rudimentary vocabulary within dog vocalizations. Our findings indicate a significant acoustic consistency in these identified canine vocabulary, covering the entirety of observed dog vocalization sequences. We further develop a web-based dog vocalization labeling system. This system can highlight phoneme n-grams, present in the vocabulary, in the dog audio uploaded by users.
On the Efficacy of Eviction Policy for Key-Value Constrained Generative Language Model Inference
Feb 17, 2024



Despite the recent success associated with Large Language Models (LLMs), they are notably cost-prohibitive to deploy in resource-constrained environments due to their excessive memory and computational demands. In addition to model parameters, the key-value cache is also stored in GPU memory, growing linearly with batch size and sequence length. As a remedy, recent works have proposed various eviction policies for maintaining the overhead of key-value cache under a given budget. This paper embarks on the efficacy of existing eviction policies in terms of importance score calculation and eviction scope construction. We identify the deficiency of prior policies in these two aspects and introduce RoCo, a robust cache omission policy based on temporal attention scores and robustness measures. Extensive experimentation spanning prefilling and auto-regressive decoding stages validates the superiority of RoCo. Finally, we release EasyKV, a versatile software package dedicated to user-friendly key-value constrained generative inference. Code available at https://github.com/DRSY/EasyKV.
PsyEval: A Comprehensive Large Language Model Evaluation Benchmark for Mental Health
Nov 15, 2023



Recently, there has been a growing interest in utilizing large language models (LLMs) in mental health research, with studies showcasing their remarkable capabilities, such as disease detection. However, there is currently a lack of a comprehensive benchmark for evaluating the capability of LLMs in this domain. Therefore, we address this gap by introducing the first comprehensive benchmark tailored to the unique characteristics of the mental health domain. This benchmark encompasses a total of six sub-tasks, covering three dimensions, to systematically assess the capabilities of LLMs in the realm of mental health. We have designed corresponding concise prompts for each sub-task. And we comprehensively evaluate a total of eight advanced LLMs using our benchmark. Experiment results not only demonstrate significant room for improvement in current LLMs concerning mental health but also unveil potential directions for future model optimization.
Zero-shot Faithfulness Evaluation for Text Summarization with Foundation Language Model
Oct 18, 2023



Despite tremendous improvements in natural language generation, summarization models still suffer from the unfaithfulness issue. Previous work evaluates faithfulness either using models trained on the other tasks or in-domain synthetic data, or prompting a large model such as ChatGPT. This paper proposes to do zero-shot faithfulness evaluation simply with a moderately-sized foundation language model. We introduce a new metric FFLM, which is a combination of probability changes based on the intuition that prefixing a piece of text that is consistent with the output will increase the probability of predicting the output. Experiments show that FFLM performs competitively with or even outperforms ChatGPT on both inconsistency detection and faithfulness rating with 24x fewer parameters. FFLM also achieves improvements over other strong baselines.
Context Compression for Auto-regressive Transformers with Sentinel Tokens
Oct 15, 2023The quadratic complexity of the attention module makes it gradually become the bulk of compute in Transformer-based LLMs during generation. Moreover, the excessive key-value cache that arises when dealing with long inputs also brings severe issues on memory footprint and inference latency. In this work, we propose a plug-and-play approach that is able to incrementally compress the intermediate activation of a specified span of tokens into compact ones, thereby reducing both memory and computational cost when processing subsequent context. Experiments on both in-domain language modeling and zero-shot open-ended document generation demonstrate the advantage of our approach over sparse attention baselines in terms of fluency, n-gram matching, and semantic similarity. At last, we comprehensively profile the benefit of context compression on improving the system throughout. Code is available at https://github.com/DRSY/KV_Compression.