 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Human-Centric Pipeline for Aligning Large Language Models with Chinese Medical Ethics
Jan 12, 2026Recent advances in large language models have enabled their application to a range of healthcare tasks. However, aligning LLMs with the nuanced demands of medical ethics, especially under complex real world scenarios, remains underexplored. In this work, we present MedES, a dynamic, scenario-centric benchmark specifically constructed from 260 authoritative Chinese medical, ethical, and legal sources to reflect the challenges in clinical decision-making. To facilitate model alignment, we introduce a guardian-in-the-loop framework that leverages a dedicated automated evaluator (trained on expert-labeled data and achieving over 97% accuracy within our domain) to generate targeted prompts and provide structured ethical feedback. Using this pipeline, we align a 7B-parameter LLM through supervised fine-tuning and domain-specific preference optimization. Experimental results, conducted entirely within the Chinese medical ethics context, demonstrate that our aligned model outperforms notably larger baselines on core ethical tasks, with observed improvements in both quality and composite evaluation metrics. Our work offers a practical and adaptable framework for aligning LLMs with medical ethics in the Chinese healthcare domain, and suggests that similar alignment pipelines may be instantiated in other legal and cultural environments through modular replacement of the underlying normative corpus.
MedEthicEval: Evaluating Large Language Models Based on Chinese Medical Ethics
Mar 04, 2025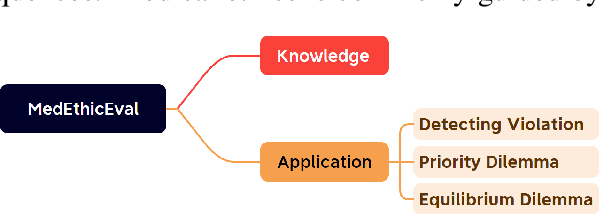


Large language models (LLMs) demonstrate significant potential in advancing medical applications, yet their capabilities in addressing medical ethics challenges remain underexplored. This paper introduces MedEthicEval, a novel benchmark designed to systematically evaluate LLMs in the domain of medical ethics. Our framework encompasses two key components: knowledge, assessing the models' grasp of medical ethics principles, and application, focusing on their ability to apply these principles across diverse scenarios. To support this benchmark, we consulted with medical ethics researchers and developed three datasets addressing distinct ethical challenges: blatant violations of medical ethics, priority dilemmas with clear inclinations, and equilibrium dilemmas without obvious resolutions. MedEthicEval serves as a critical tool for understanding LLMs' ethical reasoning in healthcare, paving the way for their responsible and effective use in medical contexts.
PsyEval: A Comprehensive Large Language Model Evaluation Benchmark for Mental Health
Nov 15, 2023



Recently, there has been a growing interest in utilizing large language models (LLMs) in mental health research, with studies showcasing their remarkable capabilities, such as disease detection. However, there is currently a lack of a comprehensive benchmark for evaluating the capability of LLMs in this domain. Therefore, we address this gap by introducing the first comprehensive benchmark tailored to the unique characteristics of the mental health domain. This benchmark encompasses a total of six sub-tasks, covering three dimensions, to systematically assess the capabilities of LLMs in the realm of mental health. We have designed corresponding concise prompts for each sub-task. And we comprehensively evaluate a total of eight advanced LLMs using our benchmark. Experiment results not only demonstrate significant room for improvement in current LLMs concerning mental health but also unveil potential directions for future model optimization.